Pandas Package
- 데이터 처리와 분석을 위한 라이브러리
- 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있음
- Array계산에 특화된 NumPy를 기반으로 설계
- Pandas의 자료 구조로는
1차원 Series,2차원 DataFrame,3차원 Panel import pandas as pd를 import하여 사용
✅Series
-
numpy array가 보강된 형태로 data와 index를 가지고 있음
-
index를 가지고 있어 인덱스로 접근이 가능 (index를 따로 지정하지 않았을 때는 0부터 할당)
data=pd.Series([1,2,3,4], index=['a', 'b', 'c', 'd']) -
name 인자로 이름을 지정할 수 있음
-
딕셔너리를 사용하여 만들 수 있음
country_dic={ "korea" : 5180, "japan" : 12718, "china" : 141500, "usa" : 32676 } country=pd.Series(country_dic)
✅DataFrame
- 2차원 자료구조로 행레이블/열레이블, 데이터로 구성됨
1️⃣dictionary에서 데이터 프레임 생성
import pandas as pd
# 딕셔너리
data = {
'year':[2016, 2017, 2018],
'GDP rate': [2.8, 3.1, 3.0],
'GDP': ['1.637M', '1.73M', '1.83M' ]
}
df = pd.DataFrame(data, index=data['year']) # index추가할 수 있음
print(df)## year GDP rate GDP
## 2016 2016 2.8 1.637M
## 2017 2017 3.1 1.73M
## 2018 2018 3.0 1.83Mdf.index: 2016,2017... index 반환df.columns: year, GDP rate, GDP
2️⃣Indexing / Slicing
- 특정 변수의 추출 :
df['year']ordf.year
## 2016 2016
## 2017 2017
## 2018 2018
## Name: year, dtype: int64.loc: 명시적인 인덱스를 참조하는 indexing/slicing
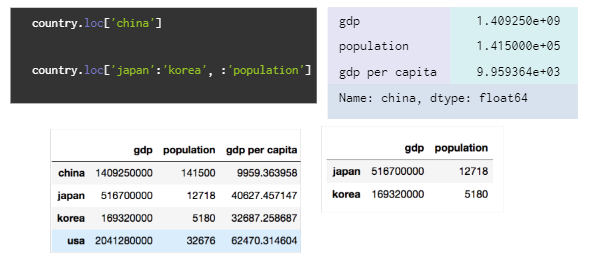
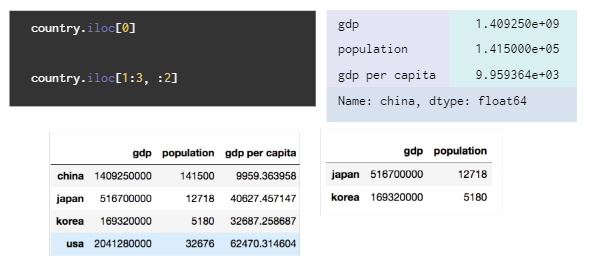
위와 같은 예시에서country.loc['japan':'korea', : 'population']의 의미는 japan에서 korea까지, 처음부터 population까지의 정보를 가져온다는 뜻이다.iloc: python 스타일 정수 index indexing/slicing
3️⃣DataFrame 새 데이터 추가/수정, 칼럼 추가
dataframe=pd.DataFrame(columns=['이름', '나이', '주소'])
# 위와 같이 이름, 나이, 주소를 가진 칼럼이 있을 때
- 리스트로 추가
dataframe.loc[0]=['홍길동', '27', '부산']
- 딕셔너리로 추가
dataframe.loc[1]=['박길동', '27', '서울'] dataframe.loc[1, '이름']='최길동'다음과 같은 결과를 확인할 수 있다
- dataframe 새 컬럼 추가
dataframe['전화번호']=np.nan

4️⃣Pandas 연산
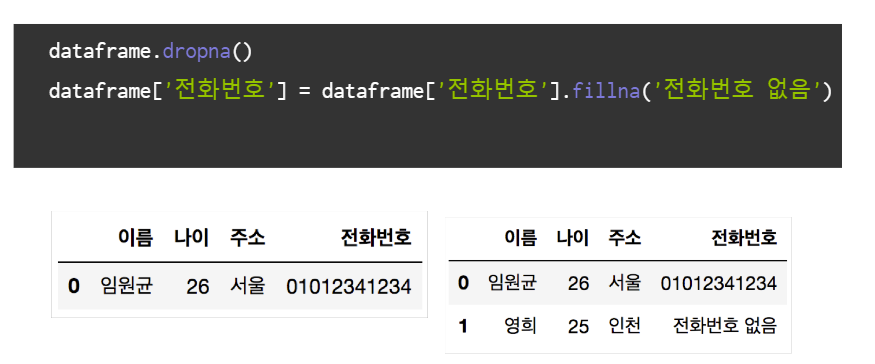
- 누락된 데이터 체크
dropna()
# 결측값 제거 : 관측값이 아주 많고 결측값이 별로 없는 경우에는
# 결측값이 들어있는 행 전체를 삭제하고 분석을 진행해도 무리가 없고 편리
fillna()
# 결측값 변경 : 결측값을 원하는 값으로 변경
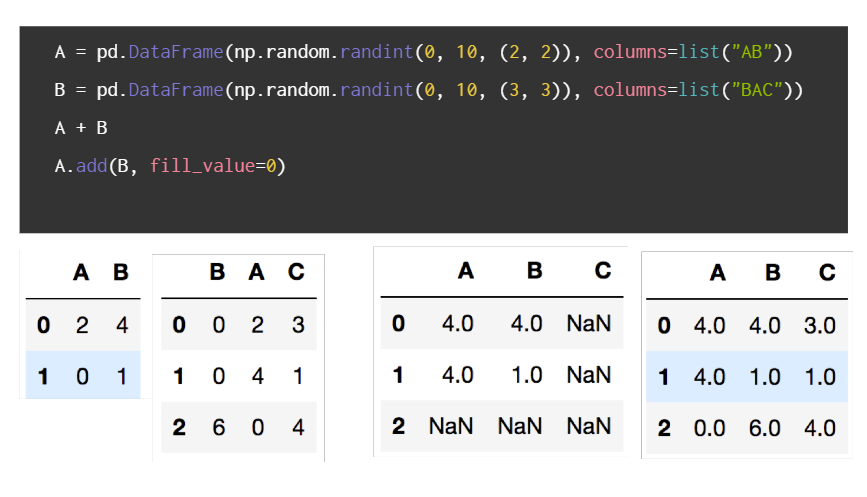
- DataFrame 연산
- 값으로 정렬하기
print(df.sort_values(by='영어')) #오름차순
print(df.sort_values(by='영어', ascending=False)) #내림차순
print(df.sort_values(by='영어', ascending=False).head(2)) #head 사용
print(df.sort_values(by='영어', ascending=False).tail(2)) #tail 사용Reference

백엔드 개발자 지망생에서 Test Engineer. 를 지나 AI Engineer를 향해 가는 Software Engineer (https://juyoungkimmy-kim.github.io/ 블로그 이주))