
✅조건으로 검색
1️⃣masking 연산
- query문으로도 가능
import numpy as np
import pandas as pd
df=pd.DataFrame(np.random.rand(5,2), columns=["A", "B"]
df[df['A']>0.5 & df['B']<0.3]
--> query문으로도 가능
df.query("A > 0.5 and B <0.3")2️⃣문자열 검색
df["Animal"].str.contains ("Cat")
df.Animal.str.match("Cat")✅함수로 데이터 처리
apply()를 통해서 함수로 데이터를 다루기
df=pd.DataFrame(np.arange(5), column=["Num"])
def square(x) :
return x**2
df["Num"].apply(square) --> Num에 제곱수 넣기
df["Square"]=df.Num.apply(lambda x:x**2) -->square 칼럼을 만들고 람다 식 이용replace()
df.sex.replace({"Male" :0, "Female":1})
df.sex.replace({"Male" :0, "Female":1}, inplace=True) # 원래 값 자체를 바꿀 ✅그룹으로 묶기
-
groupby(): 간단한 집계를 넘어서서 조건부로 집계할 경우
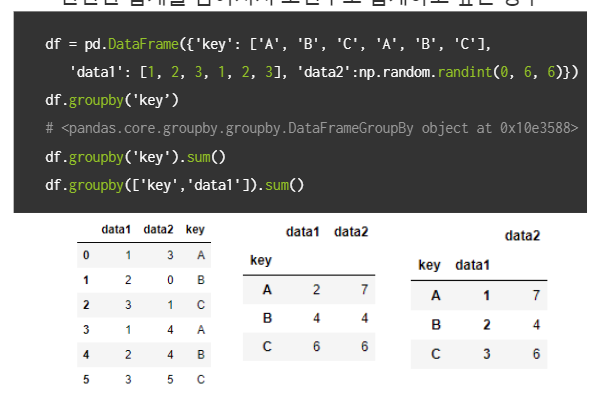
-
aggregate():groupby를 통해서 집계를 한 번에 계산하는 방법
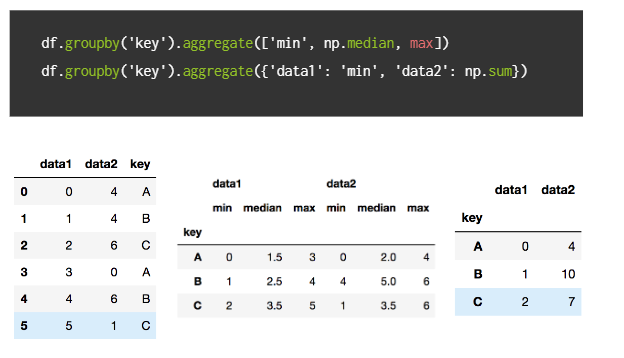
칼럼별로 다른 집계 함수를 사용하고 싶을 때는 딕셔너리 형태로 표현
get_group(): groupby로 묶인 데이터에서 key값으로 데이터를 가져올 수 있음


백엔드 개발자 지망생에서 Test Engineer. 를 지나 AI Engineer를 향해 가는 Software Engineer (https://juyoungkimmy-kim.github.io/ 블로그 이주))