Boosting Zero-shot Learning via Contrastive Optimization of Attribute Representations 제5-2부 method
C. Comparisons to state of the arts
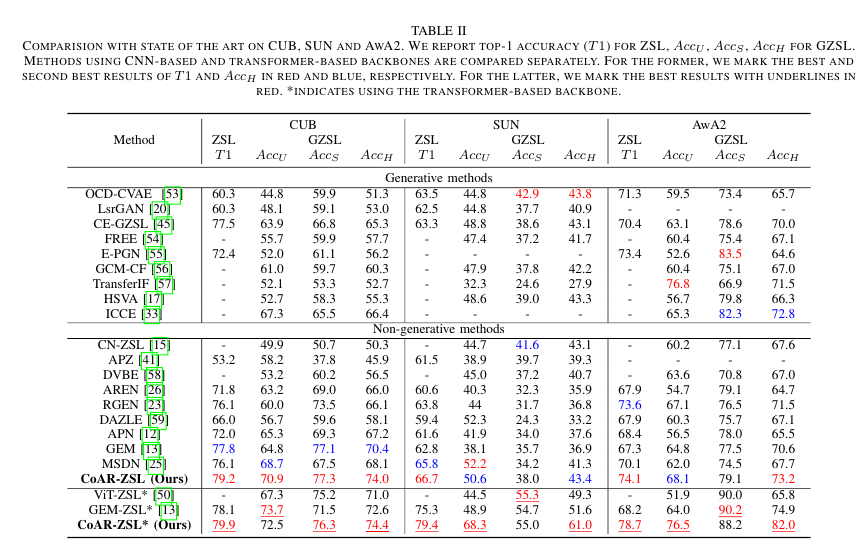
COMPARISION WITH STATE OF THE ART ON CUB, SUN AND AWA2. WE REPORT TOP-1 ACCURACY (T1) FOR ZSL, Acc U , Acc S , Acc H FOR GZSL.
CUB, SUN 및 AWA2에 대한 최신 기술과의 비교. ZSL, Acc U, Acc S, GZSL에 대한 Acc H에 대한 TOP-1 정확도(T1)를 보고합니다.
METHODS USING CNN-BASED AND TRANSFORMER-BASED BACKBONES ARE COMPARED SEPARATELY.
separately 각각, 별도로
CNN 기반 및 TRANSFORMER 기반 백본을 사용하는 방법을 별도로 비교합니다.
FOR THE FORMER, WE MARK THE BEST AND SECOND BEST RESULTS OF T1 AND IN RED AND BLUE, RESPECTIVELY.
전자의 경우 T1 및 AccH의 최고 및 두 번째 최고 결과를 각각 빨간색과 파란색으로 표시합니다.
FOR THE LATTER, WE MARK THE BEST RESULTS WITH UNDERLINES IN RED.*INDICATES USING THE TRANSFORMER-BASED BACKBONE.
전자의 경우 T1 및 AccH의 최고 및 두 번째 최고 결과를 각각 빨간색과 파란색으로 표시합니다.
후자의 경우 가장 좋은 결과를 빨간색 밑줄로 표시합니다.*변압기 기반 백본 사용을 나타냅니다.
In Table II we compare our CoAR-ZSL to recent state of the arts [12], [13], [15], [17], [20], [23], [25], [26], [33], [41], [45], [50], [53]–[60] in both ZSL and GZSL settings.
표 II에서는 CoAR-ZSL을 최신 기술 [12], [13], [15], [17], [20], [23], [25], [26], [33]과 비교합니다. , [41], [45], [50], [53]–[60] ZSL 및 GZSL 설정 모두에서.
We partition them into generative methods [17], [20], [33], [45], [53]–[57] and non-generative methods [12], [13], [15], [23], [25], [26], [41], [50], [58], [59] following [12], [13].
partition 나누다
우리는 그것들을 [17], [20], [33], [45], [53]–[57] 및 [12], [13], [15], [23], [25], [26], [41], [50], [59]로 나눈다.
Our CoAR-ZSL is a non-generative method.
우리의 CoAR-ZSL은 비생성 방법이다.
1) CNN-based architecture
All methods except for [50] use the same CNN-based ResNet101 backbone with our CoAR-ZSL.
1) CNN 기반 아키텍처: [50]을 제외한 모든 방법은 CoAR-ZSL과 동일한 CNN 기반 ResNet101 백본을 사용합니다.
CoAR-ZSL significantly outperforms the state of the art CNN-based methods on most of the indicators.
indicator 지표
CoAR-ZSL은 대부분의 지표에서 CNN 기반 방법을 크게 능가한다.
In particular with T1 and , which are two important indicators for ZSL and GZSL, it achieves 79.2, 66.7, 74.1 for T1 and 74.0, 43.4, 73.2 for on CUB, SUN and AwA2, respectively.
particular 특히
특히 ZSL 및 GZSL에 대한 두 가지 중요한 지표인 T1 및 의 경우 CUB, SUN 및 AwA2에서 각각 T1의 경우 79.2, 66.7, 74.1 및 의 경우 74.0, 43.4, 73.2를 달성합니다.
Also, we would like to point out that our method produces very good results on all three datasets while the previous best results are spread over different methods on the three datasets.
spread 분산되다 point out 지적하다
또한 우리의 방법은 세 가지 데이터 세트 모두에서 매우 좋은 결과를 생성하는 반면 이전의 최상의 결과는 세 가지 데이터 세트에서 서로 다른 방법으로 분산된다는 점을 지적하고 싶습니다.
Unlike those generative-based methods [17], [20], [23], [41], [45], [53], [57], our CoAR-ZSL does not need to synthesize virtual features of unseen classes nor do we need the semantics or visual features of unseen classes during training.
이러한 생성 기반 방법[17], [20], [23], [41], [45], [53], [57]과 달리 CoAR-ZSL은 보이지 않는 클래스의 가상 기능을 합성할 필요도 없고 훈련 중에 보이지 않는 클래스의 의미론이나 시각적 기능이 필요하지 않다.
If we do a fairer comparison to other non-generative methods [12], [13], [15], [23], [25], [26], [41], [50], [58], [59], our improvements over the state of the art are even more!!
fairer 공정한
우리가 다른 비 생성 방법 [12], [13], [15], [23], [25], [26], [41], [50], [58], [59]와 더 공정한 비교를한다면, 최첨단 기술에 대한 우리의 개선은 훨씬 더 많습니다 !!
Overall, CoAR-ZSL is apparently the most competitive method.
overall 전반적인 apparently 분명한, 명백한
전반적으로 CoAR-ZSL이 가장 경쟁력 있는 방법이다.
2) Transformer-based architecture:
When replacing the CNN-based architecture with the transformer-based architecture, the improvement of CoAR-ZSL* over CoAR-ZSL is impressive!
CNN 기반 아키텍처를 트랜스포머 기반 아키텍처로 교체할 때 CoAR-ZSL에 비해 CoAR-ZSL*의 개선이 인상적입니다!
It raises T1 to 79.9, 79.4, 78.7 and to 74.4, 61.0, 82.0 for the three datasets, respectively.
세 가지 데이터 세트에 대해 각각 T1을 79.9, 79.4, 78.7 및 를 74.4, 61.0, 82.0으로 올립니다.
The improvements on SUN and AwA2 are particularly significant: 12.7% and 4.6% on T1, 17.6% and 8.8% on .
SUN 및 AwA2의 개선 사항은 특히 중요합니다. T1에서 12.7% 및 4.6%, 에서 17.6% 및 8.8%입니다.
These improvements make CoAR-ZSL* significantly outperforming the recent work, ViT-ZSL [50], who also utilizes ViT [49].
이러한 개선으로 CoAR-ZSL*은 ViT[49]도 활용하는 최근 작업인 ViT-ZSL[50]을 훨씬 능가합니다.
The ViT backbone is pretrained on ImageNet21k which is not comparable to the CNN-based backbone.
ViT 백본은 CNN 기반 백본과 비교할 수 없는 ImageNet21k에서 사전 학습됩니다.
To make a fair comparison, we replace the backbone of the state of the art method GEM-ZSL [13] with the ViT backbone and report the results in Table II: GEM-ZSL.
공정한 비교를 위해 최신 방법 GEM-ZSL[13]의 백본을 ViT 백본으로 교체하고 결과를 표 II: GEM-ZSL``에 보고합니다.
Our CoAR-ZSL* significantly outperforms GEM-ZSL*
CoAR-ZSL*은 GEM-ZSL*을 훨씬 능가합니다.
We did not elaborate values on and , as they are sort of reflected in .
elaborate 상술하다, 설명하다
와 에 대한 값은 에 일종의 반영되므로 구체적으로 설명하지 않았다.
D. Ablation study
Ablation study is on all three datasets and we report T1 and for ZSL/GZSL, using the CNN backbone.
절제 연구는 세 가지 데이터 세트 모두에 대해 수행되며 CNN 백본을 사용하여 ZSL/GZSL에 대한 T1 및 를 보고합니다.

ABLATION STUDY OF LOSS TERMS IN (7). WE ACCUMULATE EACH TERM FROM TOP TO BOTTOM OF THE TABLE.
term 조건
(7)의 손실 조건에 대한 절제 연구. 우리는 표의 위에서 아래로 각 항을 누적한다.
1) Impact of attribute representation optimization
속성 표현 최적화의 영향:
We show the impact of adding losses for attribute representation learning one-by-one in (7).
(7)에서 하나씩 속성 표현 학습에 대한 손실 추가의 영향을 보여줍니다.
We start from which means no attribute representations are included into the framework
에서 시작합니다. 이는 속성 표현이 프레임워크에 포함되지 않음을 의미합니다.
The results are in Table III where it clearly shows that adding , , and all help the performance and they are complementary.
complementary 상호보안적인
결과는 , 및 를 추가하는 것이 모두 성능에 도움이 되며 상호 보완적임을 명확하게 보여주는 표 III에 있습니다.
In particular, the two contrastive optimization loss and contribute the most.
특히, 두 개의 대조적 최적화 손실 및 가 가장 많이 기여합니다.
The former is to learn explicit and robust attribute prototypes while the latter is to reinforce attribute-level features.
former 전자, latter 후자
전자는 명시적이고 강력한 속성 프로토타입을 학습하는 것이고 후자는 속성 수준 기능을 강화하는 것입니다.
They are also highlighted in Sec. III-D3.
highlight 강조하다
그들은 또한 Sec. III-D3에서 강조 표시됩니다.
Hard examples in .
의 어려운 예제
We offer a variant of without hard example selection, denoting as w/o HS.
denote 나타내다 variant 변형
우리는 hard example 를 선택하지 않은 의 변형을 제공하며, 이는 w/o HS로 나타낸다.
All examples will be used in (5) and the result in Table III shows that w/o HS performs clearly inferior to .
inferior 낮은, 열등한
모든 예는 (5)에서 사용될 것이며, 표 III의 결과는 w/o HS가 보다 확실히 열등하다는 것을 보여준다.

ABLATION STUDY ON PROTOTYPE MODULE (PM) STRUCTURE.
2) Prototype generation module(PM) :
The module consists of a few shared layers and two identical branches for class and attribute prototype generation.
이 모듈은 몇 개의 공유 레이어와 클래스 및 속성 프로토타입 생성을 위한 두 개의 동일한 분기로 구성됩니다.
Two variants can be made on the module design: 1) we devise two identical modules without shared layers to generate prototypes for class and attribute separately (PM-v1); 2) we devise one module without separate branches to generate prototypes for class and attribute simultaneously (PM-v2).
모듈 디자인에서 두 가지 변형을 만들 수 있습니다. 1) 클래스와 속성에 대한 프로토타입을 별도로 생성하기 위해 공유 레이어 없이 두 개의 동일한 모듈을 고안합니다(PM-v1). 2) 클래스와 속성에 대한 프로토타입을 동시에 생성하기 위해 별도의 분기 없이 하나의 모듈을 고안합니다(PM-v2).
Table IV shows that either case performs inferior to our original design.
표 IV는 두 경우 모두 원래 설계보다 성능이 떨어지는 것을 보여줍니다.
The shared part in our design enforces class- and attribute prototypes to share some common information while the separated part models their differences.
enforce 강제하다. 실시하다
설계의 공유 부분은 클래스 및 속성 프로토타입이 공통 정보를 공유하도록 강제하는 반면 분리된 부분은 차이점을 모델링한다.
The class normalization in the module (Section III-D1) also plays a vital role.
vital 중요한
모듈의 클래스 정규화(섹션 III-D1)도 중요한 역할을 합니다.
If we remove it (PM w/o CN), the performance drops as well.
제거하면(CN w/o PM) 성능도 떨어집니다.

3) Attribute semantics:
속성 의미론
We replace our one-hot attribute semantic vectors in AS with other forms to see the results.
AS의 one-hot 속성 의미 벡터를 다른 형식으로 대체하여 결과를 확인합니다.
For the random (nonorthogonal) matrix (Rnd), we generate it by drawing from a zero-mean Gaussian distribution with standard deviation of 0.1.
랜덤(직교하지 않은) 행렬(Rnd)의 경우, 표준 편차가 0.1인 0평균 가우시안 분포에서 그리면서 생성합니다.
For the orthogonal matrix (Rnd-ort), we use the Schmidt orthogonalization to orthogonalize the previous nonorthogonal matrix.
직교 행렬(Rnd-ort)의 경우 Schmidt 직교화를 사용하여 이전의 비직교 행렬을 직교화합니다.
The results are in Table V. The one-hot form works the best and serves as the simplest and most suitable basis for the class semantics.
suitable 적절한
결과는 표 V에 나와 있습니다. 원-핫 형식이 가장 잘 작동하며 클래스 의미론에 대한 가장 간단하고 가장 적합한 기초 역할을 합니다.
Rnd-ort is better than Rnd as its orthogonality complies with the nature of distinct attributes.
Rnd-ort는 직교성이 고유한 속성의 특성을 준수하므로 Rnd보다 낫습니다.
