
1. Overview
Large Multimodal Models (LMM) 과 관련된 최신 연구들이
- Visual Instruction Tuning
- Scaling up pre-training (Feature Alignment) Data
- Scaling up fine-tuning (instrurction-following) Data
- Scaling up Visual Encoder (ex. CLIP ViT)
- Scaling up Language Decoder (ex. Llama, Vicuna)
위와 같은 다양한 Design Choice를 통한 Performance Improvment를 증명하였지만,
General Purpose Multi-modal Agent를 구축하기 위한,
LMM's Best-Recipe가 무엇인지는 여전히 불분명하다.
- Amount of Data (Pre-Training, Instruction Tuning)
- Scale of Model (Visual Encoder, Language Decoder)
- Shape of Visual Resamplers (Fully-Connected based, Cross-Attention based)
위와 같은 다양한 Design Choice가 존재하는 LMM 분야에서,
본 연구는 LLaVA Framework에 기반하여
LMM's Best Design Choice에 대한 Systematic study를 진행하였다.
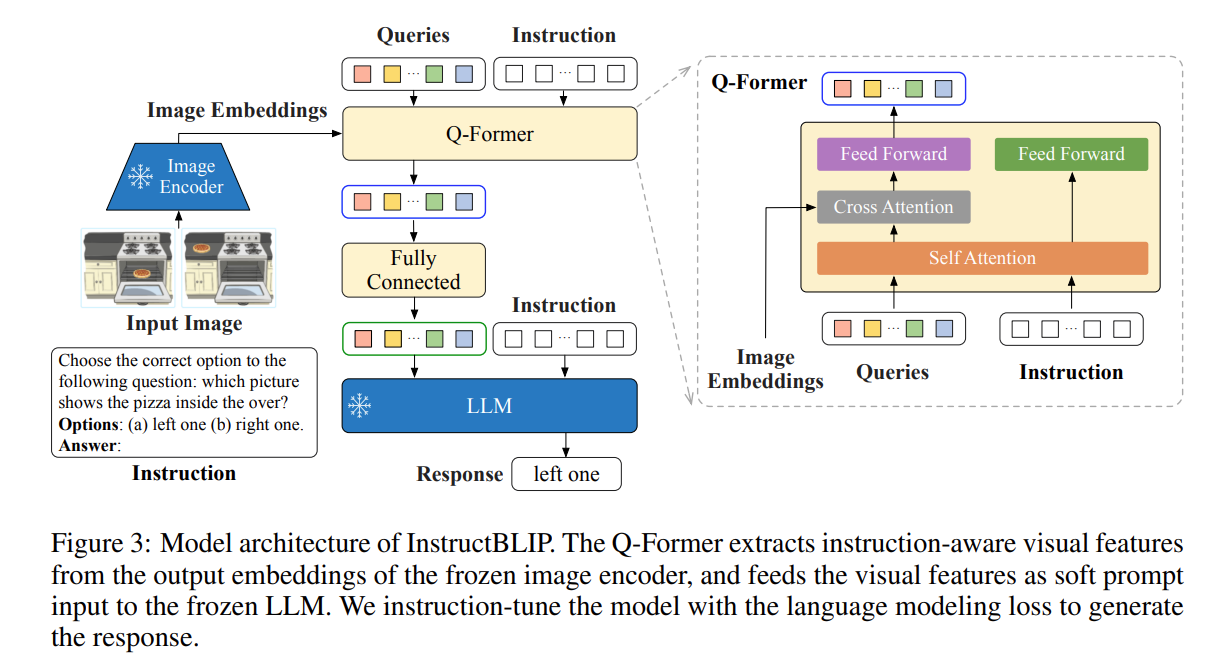
InstructBLIP에서의 Q-Former와 같이 Cross Attention mechanism에 기반하여,
Variably sized image feature → Fixed Sized Language Tokens
위와 같은 Token Resampling을 수행하는 Visual Resampler가 Multi-modal Embedding을 위한 Feature Alignment를 효과적으로 이루기도 하였지만,
이러한 Specially designed Visual Resampler는
millions or even billions of image-text paired data를 Pre-Training에 활용해야 한다.
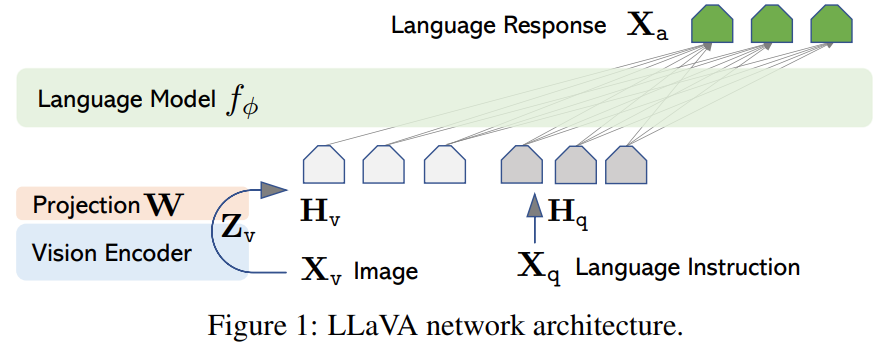
허나, LLaVA의 경우, Simple Fully-Connected Projection Layer 를 활용함에 따라, 600K의 image-text pairs만으로, 효과적인 학습을 이루는 Data-Efficiency를 달성하였다.
이에 해당 연구 LLaVA-1.5는, LLaVA의 효율적인 아키텍처를 기반으로 정확성을 높이고자, 다음과 같은 변화를 취하였다.
→ CLIP-ViT-L-336px: More capable Visual Encoder
→ MLP projection: More capable Vision-Text Connector
→ Adding academic-task-oriented VQA data: Enhance Visual Reasoning
이를 통해 11개의 Benchmark에서 SOTA를 달성하였고 (23.10 기준),
최종 13B Checkpoint는 단지 1.2M publicly available data를 활용하였으며
single 8-A100 node에서 1일 이내로 전체 학습을 완료하였다.
저자들은 Data-Efficient한 LLaVA-1.5 아키텍처가 다음과 같은 특성 또한 지닌다고 이야기한다.
(1) Effectively scaling to higher resolution inputs
High resolution Image가 Input으로 들어왔을 때, 단순히 여러 grids로 나누어서 별도로 Embedding을 산출하고 후에 병합하는 방식을 취하기에, High-Resolution Image에 대해 전체 파이프라인을 따로 학습시킬 필요가 없다.
이에 Data-Efficient한 방식으로 High Resolution Image를 처리할 수 있음에 따라, Detailed Visual Perception을 기반으로 Hallucination을 적게 발생시킨다.
(2) Reduce model hallucination
Visual Encoder와 Visual Token Resampler, 즉 Model의 전반적인 Capability를 Scaling함에 있어, Dataset의 Size 및 Granularity 또한 균형 있게 Scaling함에 따라, Hallucination을 최소화하며 성능 향상을 이루었다.
(3) Compositional capabilities
이는 Large Multi-modal Model에서 공통적으로 나타나는 Generalization capability로서, 'Long-form langauge reasnoing' 데이터셋과 'Shorter-from visual reasnoing' 데이터셋으로 모델을 학습시켰을 때, 'multi-modal Input에 대해 complex reasoning' capability가 증가하는 등을 의미한다.
2. Related Works
2.1. Instruction-following large multimodal models (LMMs)
일반적인 LMM 아키텍처는 다음의 3가지로 구성된다.
(1) Pre-trained visual backbone to encode visual features (Ex. ViT)
(2) Pre-trained large language model (LLM) to comprehend the user instructions and produce responses (Ex. Llama, Vicuna, Qwen)
(3) Vision-Language cross-modal connector to align the vision encoder outputs to the language models (Ex. MLP, Q-Former)
Multi-modal instruction following LMM은 일반적으로 2단계의 학습을 거친다.
(1) Vision-Language alignment pre-training stage:
Vision-Language cross-modal connector를 학습시킴으로써, Visual Feature와 Language Model's word embedding space 간에 alignment를 이루는 과정이다.
∼600K or ∼6M 과 같이 뒤따르는 Instruction Tuning에 비해 상대적으로 적은 image-text pairs를 활용하지만,
Cross-Attention 메커니즘에 기반하여 특정한 Language Model을 위해 설계된 Vision-Language Connector의 경우, Alignment를 Maximize하기 위해 129M 혹은 1.4B 등의 대량의 데이터셋을 활용하는 경우도 있다.
(2) Visual instruction tuning stage:
Image, Video 등의 Visual Content를 포함하는 사용자의 다양한 Instruction을 따를 수 있게, LMM을 학습시키는 과정이다.
2.2. Multimodal instruction-following data
많은 NLP 연구에서, Instruction Following Data의 Quality가
Instruction-following Model의 Capability에 큰 영향을 미침을 확인하였기에,
LLaVA는 Text-only GPT-4를 활용하여
'COCO Bounding box and caption dataset'을 기반으로

Multi-modal instruction following dataset을 구축하였고, 이는 다음의 3가지를 포함한다.
(1) conversational-style QA
(2) detailed description
(3) complex reasoning

이와 별개로, FLAN family의 경우, LLM의 Instruction Tuning에 대량의 Academic-task-oriented dataset을 활용하는 것이 Generalization Capability를 향상시킴을 확인하였기에,
해당 연구 LLaVA-1.5는, Multi-modal reasoning capability를 향상시키고자, Academic VQA Dataset을 Multi-Turn 혹은 Single Turn Conversation Format의 Instruction following dataset으로 확장하여, 모델 학습에 활용하였다.
3. LLaVA-1.5: Methodologies
3.1. Preliminaries
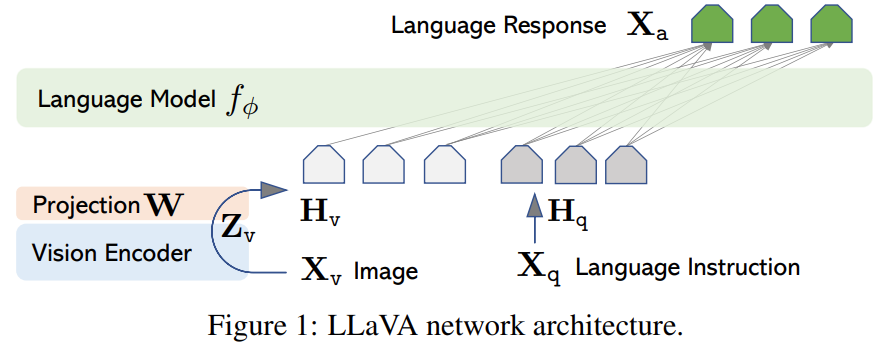
LLaVA는 Visual Feature를 LLM의 Word Embedding Space로 투영하기 위해, single linear layer 를 활용하고,
Feature-Alignment를 위해 Data-Efficient한 Pre-Training을 진행하며,
뒤 따르는 Visual Instruction Tuning (Fine Tuning)에서는 전체 LLM Decoder를 최적화한다.
Visual Instruction Tuning에서
- 'Conversation-style QA'
- 'Detailed description'
- 'Complex reasoning'
3가지를 포함한 Instruction-following-dataset을 학습함에 따라,
real life natural conversation에서 우수한 추론 능력을 보였다.
하지만, Training Distribution 상에, short-form answer를 주로 요구하는 academic-task-oriented-dataset이 부족함에 따라,
single-word 등의 짧은 답변을 요구하는 academic benchmark에서는 성능이 좋지 않았고, yes/no question에 대해 주로 yes로 응답하는 경향을 보였다.
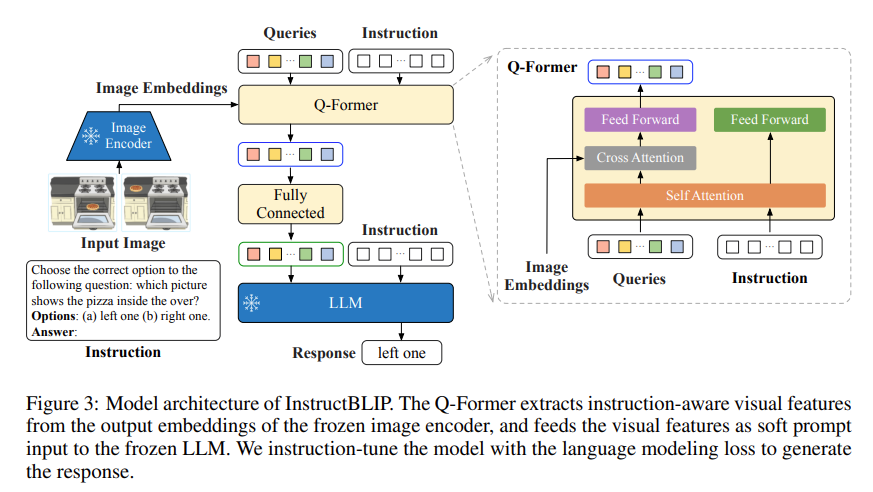
이와 반대로 InstructBLIP은 위의 아키텍처를 학습함에 있어,
아래 이미지의 '사용된 데이터셋 목록'에서 확인할 수 있듯이
LLaVA-Instruct와 같은 Instruct Following Dataset 뿐만 아니라,
VQA-v2와 같이 short-form answer를 주로 요구하는 academic-task-oriented-dataset도 적극적으로 포함하였고,
이에 VQA benchmark에서 우수한 성능을 달성하였다.
허나, '129M image-text pairs' 라는 scale이 큰 데이터셋으로 Vision-Language connector로서의 Q-Former를 Pre-Training하였음에도 불구하고,
아래 제시된 예시와 같이, Short-Form answer를 주로 요구하는 VQA dataset에 Overfitting됨에 따라,

 아래와 같이, 상세한 답변을 요구하는 Instruction에도 짧게 대답하는 등,
아래와 같이, 상세한 답변을 요구하는 Instruction에도 짧게 대답하는 등,
real life visual conversation에서는 LLaVA 만큼의 성능을 보이지 못하였다. 
정리하자면,
LLaVA의 경우 Short-Form answer를 생성하는데 어려움을 겪고
InstructBLIP의 경우, Long-Form answer를 생성하는데 어려움을 겪고 있기에,
- Long-Form answers
(Detailed Description, Natural Conversation, Complex Reasoning) - Short-Form answers
(Visual Question Answering benchmarks)
2가지에 모두 Capable한 Vision Language Model을 만들고자
LLaVA-1.5 연구진은 Long-Form Answer에 능숙한 LLaVA Framework을 기반으로
Visual-Instruct-Tuning 과정에
'short-form answering academic-task-oriented-datasets'을 포함하였다.
3.2. Response Format Prompting
- Long-Form 'natural conversations' 와
- Short-From 'VQA datasets' 을
모두 Instruct-Tuning 과정에 사용함에도 불구하고,
InstructBLIP이 답변의 길이를 자체적으로 조절하지 못하는 원인에 대해,
LLaVA-1.5 연구진은 다음의 2가지를 제시한다.
(1) Ambiguous prompts on the response format
예를 들자면, "Q: {Question} A: {Answer}" 이와 같은 단순한 Prompt는
desired-output-format을 명확하게 나타내지 못하고,
LLM이 질문에 대해 Short-Form Answer를 생성하게끔
Overfitting 시킬 수 있다고 제시한다.
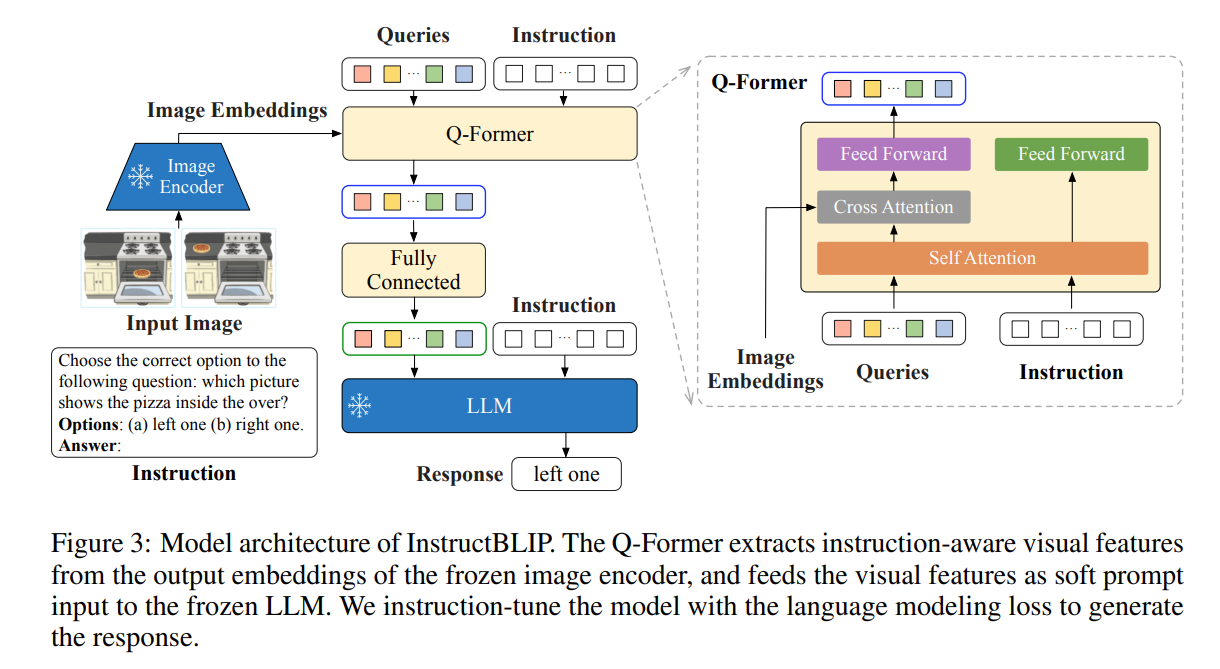
(2) Not finetuning the LLM
InstructBLIP의 경우, Vision-Language-Connector로서의 'Q-Former'만을 Fine-Tuning한다. 허나, 이는 Q-Former로부터 추출된 Visual-Output-Token이 LLM's Output이 Long-Form 혹은 Short-Form 이어야 하는지를 제어하기를 요구하지만, Llama 혹은 Vicuna와 같은 LLM에 비해 Q-Former의 Capability는 제한적이다. 따라서, LLM의 가중치를 고정한 채로, Visual-Resampler만을 Fine-Tuning하는 것이 답변 길이의 자체적 조절을 어렵게 만든다고 제시한다.
LLaVA-1.5 연구진은, LLaVA가 LLM Decoder를 Fine-Tuning함에 따라, 해당 문제를 이미 다루었음을 이야기한다.
따라서, LLaVA로 하여금 Short-Form Answer를 생성하는 길이 조절 능력 또한 함양하게끔 하고자,
LLaVA-1.5 연구진은 Short-Form Answer를 요구하는 VQA Question의 끝에 Response-Format을 명확히 나타내는 다음의 Prompt를 추가하였다.
“Answer the question using a single word or phrase”

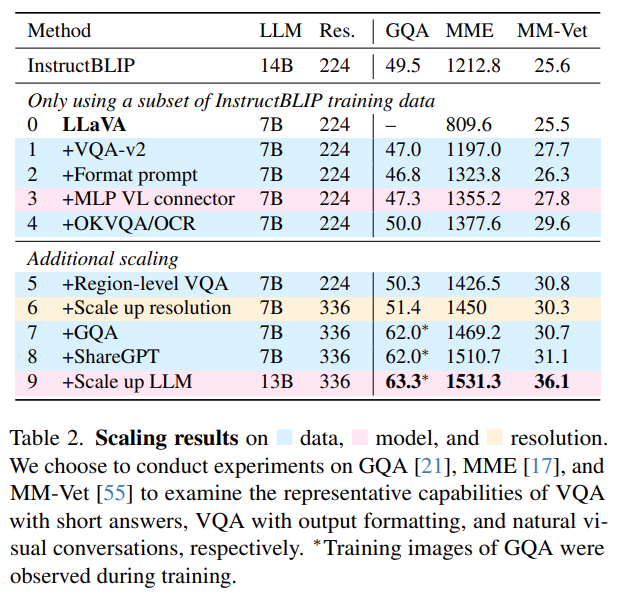
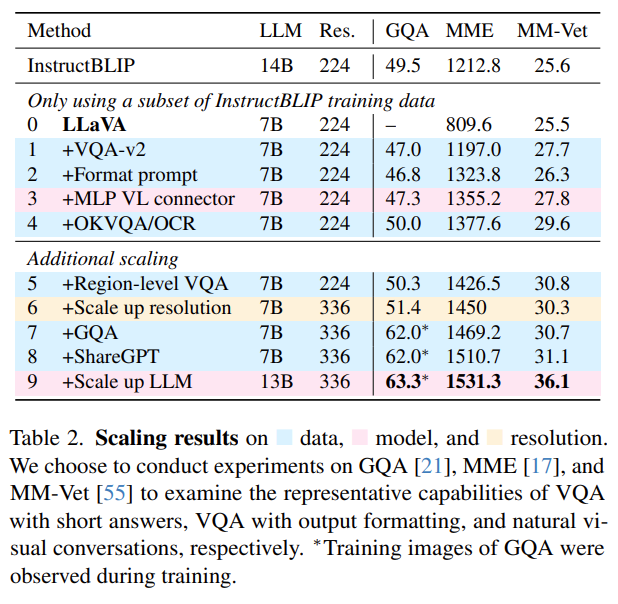 위 표에서 확인할 수 있듯이, 단순히 'Short-Form-Answering VQA-v2 Dataset'을 간단한 'Response Formatting'과 함께 Fine-Tuning 과정에 포함한 것 만으로, MME Multi-modal-benchmark에 대한 LLaVA의 점수가 InstructBLIP을 111점이나 앞서게 되었다.
위 표에서 확인할 수 있듯이, 단순히 'Short-Form-Answering VQA-v2 Dataset'을 간단한 'Response Formatting'과 함께 Fine-Tuning 과정에 포함한 것 만으로, MME Multi-modal-benchmark에 대한 LLaVA의 점수가 InstructBLIP을 111점이나 앞서게 되었다.
3.3. Scaling the Data and Model
3.3.1. MLP vision-language connector
Vision-Language-Connector's의 Representation Power를
Single Projection Matrix 에서 Two-Lyaer MLP로 개선한 결과, LLaVA의 Multi-modal Capability 또한 증가함을 확인하였다.
3.3.2. Academic task oriented data (Dataset scaling)
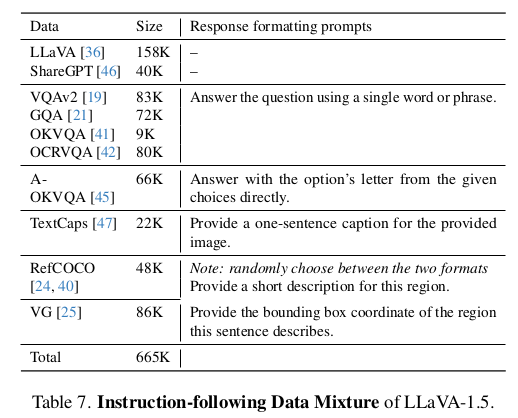
위 표에서 확인할 수 있듯이, Simple Visual-Question-Answering, OCR, Region-level-perception 등과 관련된 Academic-Task-Oriented VQA Dataset을 추가적으로 포함함에 따라, 다양한 방면에서의 Multi-modal capability를 향상시키고자 하였다.
- VQA: Visual Question Answering
- OKVQA: Open Knowledge VQA
- OCR: Optical Character Recognition
- GQA: Real images from the Visual Genome dataset with scene graph annotations
- ShareGPT: collection of conversation logs shared by ChatGPT users
3.3.3. Visual Encoder Scaling
LLM Decoder로 하여금, Input Image의 Detail을 더욱 분명하게 보게끔 하고자, Vision Encoder를 CLIP-ViT-L-336px (the highest resolution available for CLIP) 로 바꿈으로써, Input Image Resolution을 로 Scale-Up 하였다.
3.3.4. LLM (Text Decoder) Scaling
LLM을 7B에서 13B로 Scale-Up 하였을 때, MM-Vet 벤치마크에서 상당한 성능향상을 이루었고, 이는 Visual-Conversation에 있어서 Base-LLM의 Capability의 중요성을 나타낸다.
3.4. LLaVA-1.5
위에서 언급한 사항들을 모두 반영한 Final model이 LLaVA-1.5 이며, Original LLaVA 혹은 InstructBLIP에 비해서 상당한 성능향상을 이루었음을 표를 통해 확인할 수 있다.
허나, Input Image Resolution이 로 증가함에 따라, LLaVA-1.5의 경우, 8×A100s 사용 하에 '∼6 hours of pretraining and ∼20 hours of visual instruction tuning'이 소요되었고, 이는 Original LLaVA 학습 시간의 약 2배에 해당한다.
4. LLaVA-1.5-HD
4.1. Methodologies
Input Image Resolution을 증가시킴으로써, Visual Detail을 더욱 포착할 수 있지만, CLIP Visual Encoder ViT와 같은 Open Source Model들의 Input Image Resolution이 과 같이 제한적으로 고정됨에 따라, 단순히 Visual Encoder를 교체함으로써 Higher Resolution Image를 Input 받을 수는 없다.
이에 기존 연구들은
→ positional embedding interpolation
→ and adapt the ViT backbone to the new resolution during finetuning
이와 같은 방식으로, High-Resolution-Image를 처리하고자 하였으나,
이는 Visual Encoder가 다음의 제약사항을 가지도록 한다.
→ be finetuned on a large-scale image-text paired dataset,
→ and limits the resolution of the image to a fixed size that the LMM can accept during inference.
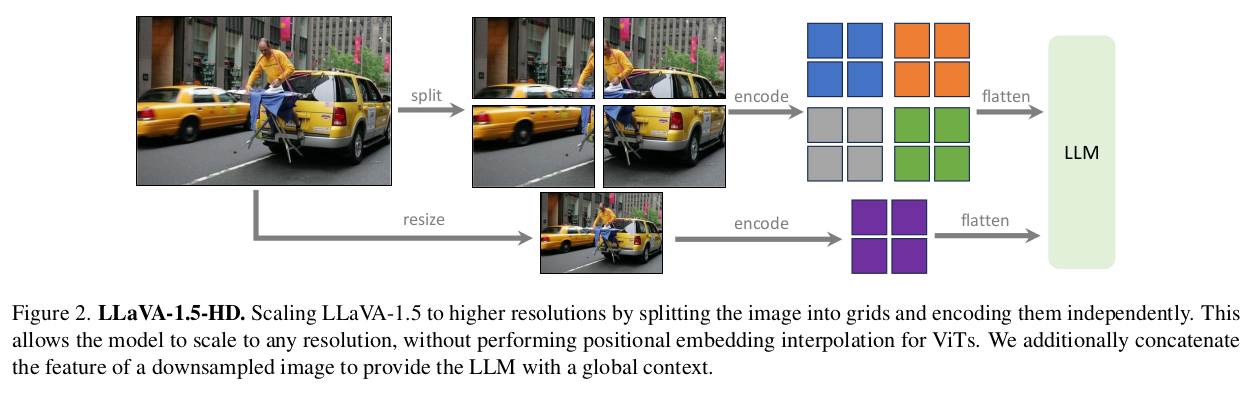 이에, LLaVA-.15 연구진은 High-Resolution Input Image를
이에, LLaVA-.15 연구진은 High-Resolution Input Image를
Vision Encoder가 사전학습된 해상도 (Ex. )의 작은 Patches로 분할한 뒤,
Vision Encoder를 통해 각 Patch를 독립적으로 Encoding하는 방식을 취하였다.
개별 Patch에 대한 Feature map을 계산한 이후에는, Concatenation 등을 통해 Target Resolution의 Single Feature map으로 합친 뒤, LLM Decoder에 Visual Context로서 Input 해준다.
허나, Split-Encode-Merge 연산의 과정에서, 개별 Patch의 Local Context에만 집중할 수도 있기에,
LLM Decoder에 Global Context를 제공하고자 Downsampling된 Input Image로부터 Feature Map을 추출한 뒤, Merged Feature Map에 추가적으로 Concatenate하는 방식을 취하였다.
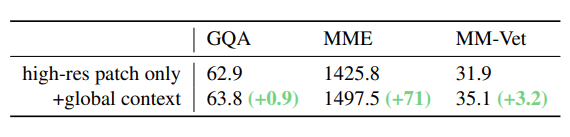
이를 통해 Visual Detail을 더욱 포착하면서도, Global Context를 반영할 수 있게 되어, 위 표에서 확인할 수 있듯이, Multi-modal Benchmark에 대한 성능이 향상되었다.
고정된 Input Image Resolution의 Image Encoder를 기반으로
Split-Encode-Merge, Global Context Concatenation의 방식을 적용함으로써,
High-Resolution Image-Text pairs에 모델을 추가적으로 Fine-Tuning할 필요가 없어졌기에,
LLaVA-1.5의 Data Efficiency를 유지하면서, Arbitrary Resolution으로 Input Image를 Scale Up할 수 있게 되었고,
연구진은 해당 모델을 LLaVA-1.5-HD로서 제시하였다.
4.2. Implementation Details
LLaVA-1.5-HD의 Split-Encode-Merge 과정에 대한 이해를 돕고자
Original Input Image로부터의 연산 과정을 적어 보았다.
-
Image Input
original resolution: (W_o, H_o) -
Target Resolution Selection
Two Criteria: [Detail preservation, Computational efficiency]
Candidate Resolutions: (224×224, 448×672 ,, etc) -
Convert Image Input to Target Resolution
→ Padding (Interpolation) on the (W_o, H_o)
→ Target Resolution: (W_t, H_t) -
Divide into grids with (224×224) Local Image Patches
→ (Grid_row, Grid_column, local_width, local_height)
→ e.g, (3, 2, 224, 224) ← Total 6 Local Patches
-
Input each individual Patch Into Image Encoder (CLIP-ViT-L-14 (224²))
→ Since Vision Transformer's
→ Output Visual Feature Shape: (# of patches, hidden dimension)
→ e.g, (224,224) —> (196, 1024) (If, 16×16 for each image chunk) -
Concatenate all the patches from each Local Image Patch
—> (Grid_row × Grid_column) patches with each of dimension (1,1,196,1024)
—> Output Size: (3, 2, 196, 1024) -
Remove Features generated from pure Paddings
—> # of Patches ⬇ -
Append Row-End Tokens
—> If Grid consists 3 Rows, 2 Columns —> 3 Row-End tokens
—> Explicitly indicate the original shape of variably sized images -
Flattening, due to sequential input to the LLM Decoder (e.g, Vicuna)
—> (Grid_row × Grid_clmn × # of patches - padding_embeddings + Row_Ends,
hidden_dim)
—> e.g, (3 × 2 × 196 - □ + 3, 1024) -
Vision-Language Connector (MLP) converts
—> [flattened visual token → multi-modal embedding]
—> Hidden Dimension alignment with LLM Decoder
—> Output dim: (# of tokens, dim_text) -
Aligned Visual Token, Text Query Embedding Concatenation
—> [Query_Embedding, Visual Token_Embedding]
”Multi-modal Input To LLM”
 Final Multi Modal Embedding: [Query_Embedding, Visual_Embedding, Output_Embedding]
Final Multi Modal Embedding: [Query_Embedding, Visual_Embedding, Output_Embedding]
-
Decoder Training:
LLM Decoder Instruction Fine-Tuning시,
Ground Truth를 한번에 Embedding 및 Concatenation 및 Attention-Masking 하여,
Parallel Next Word Prediction -
Decoder Inference:
LLM Decoder inference 시,
“Auto-regressively” Next word Prediction
이때, Caching을 통해 Auto-Regressive Computation Load ⬇
→ T번째 Predicted word만을 새롭게 Query, Key, Value로 Embedding한 이후
→ Query (1, dim_Q), Key (1, dim_K), Value (1, dim_V)
→ 기존 캐싱된 Token 들의 Query Key Value와 Self Attention Score 계산 이후
→ 전체적으로 Attention_Distribution 및 Value Extraction 재 진행
→ T+1 번째 Word Prediction 진행
→ Total Sequence Output 위해 위 과정 반복
5. Empirical Evaluations
5.1. Benchmarks
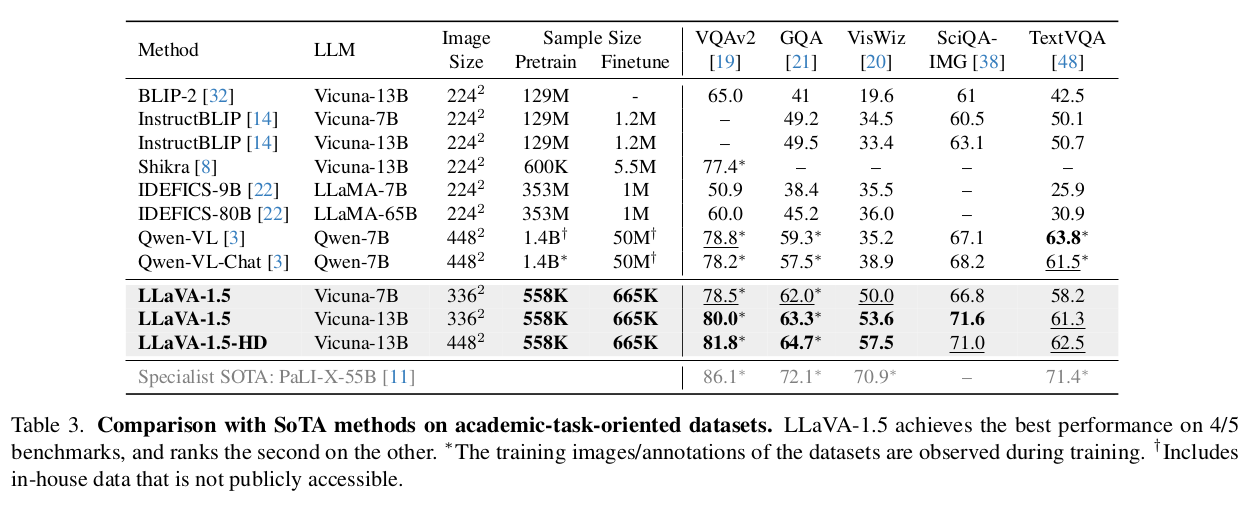
위 Academic-Task-Oriented Benchmark에 대해서
VQA-v2 and GQA: evaluate model’s visual perception capabilities on open-ended short answers.
VizWiz: contains 8,000 images to evaluate model’s zero-shot generalization on visual questions asked by visually impaired people.
ScienceQA: with multiple choice are used to evaluate the zero-shot generalization on scientific question answering.
TextVQA: contains text-rich visual question answering.
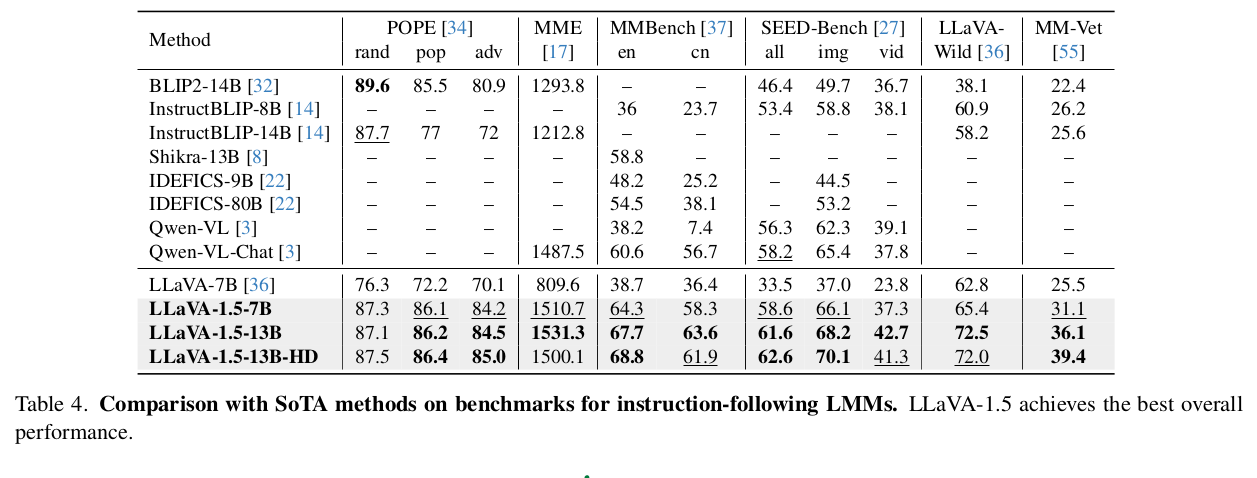
POPE: evaluates model’s degree of hallucination on three sampled subsets of COCO: random, common, and adversarial. Here reasearchers report the F1 score on all three splits.
MME-Perception: evaluates model’s visual perception with yes/no questions.
MMBench: evaluates model’s answer robustness with all-round shuffling on multiple choice answers.
SEED-Bench: evaluates model’s performance on both images and videos with multiple choices. Here reasearchers sample the frame in the middle to evaluate the accuracy on videos.
LLaVA-Bench-in-the-Wild and MM-Vet: evaluate model’s capabilities in engaging in visual conversations on a diverse range of tasks, and evaluates the correctness and the helpfulness of the response with GPT-4 evaluation.
5.2. Results
LLaVA-1.5의 경우, 여타 VLMs에 비해,
적은 Pre-Training and Instruction-Tuning 데이터셋을 사용하였음에도 불구하고,
12개의 Benchmarks에 대해 best overall performance를 달성하였다.
Base Model로서의 LLaVA와 비교하였을 때도,
LMM's Instruction-Following-Capability를 평가하기 위한 모든 Benchmark에서
상당한 성능 향상을 이루었다.

또한, LLaVA-1.5-HD에 기반하여, Input-Image-Resolution을
까지 Scale Up 하였을 때,
모든 벤치마크에서 전반적인 성능이 향상되었고
특히, 이미지의 세부적인 특징까지 인식하기를 요하는 Tasks에서 우수한 성능을 보였다.
(e.g. OCR in MM-Vet, detailed description in LLaVA-Bench-in-the-Wild)
이에 대해, LLaVA-1.5 연구진은
Split-Encode-Merge 과정에서, Global Context를 더해주는 방식이
LLaVA-1.5 모델로 하여금 High-Resolution Featurs로부터 Relevant regions를
손쉽게 Locate 할 수 있게 한다고 이야기한다.
또한, 80B IDEFICS (a Flamingo-like LMM) 보다도 우수한 성능을 보였기에
billions of trainable parameters를 지닌 cross-modal connector와
Feature-Alignment를 위한 Large-Scale Pre-Trainig이 진정으로 필요한지에 대해 의문을 제기하였고,
이미 Web-Scale Image-Text paired data에 대해 사전학습된 CLIP Vision Encoder의
Output Visual Feature를 LLM Decoder's Word Embedding Space로 투영함에 있어
MLP Vision-Language-Connector가 충분함을 이야기하였으며,
이미 Pre-Training된 Foundation Model들의
Multi-modal instruction following capability를 이끌어냄에 있어
Visual-Instruction-Tuning이 매우 중요함을 강조하였다.
5.3. Emerging Properties
5.3.1. Format instruction generalization
 LLaVA-1.5 의 경우, limited number of format instructions에 대해서
LLaVA-1.5 의 경우, limited number of format instructions에 대해서
Instruction Tuning되었음에도 불구하고,
처음 보는 Format의 Prompts에 대해서도, Generalization Capability를 보였다.
(e.g, “Unanswerable” when the provided content is insufficient to answer the question)
5.3.2. Multilingual multimodal capability
LLaVA-1.5의 경우, Multilingual multimodal instruction following dataset에 대해서 Instruction Tuning되지 않았음에도 불구하고
(all visual instructions including VQA are in English)
Multilingual instruction following capability를 보여주었고,
이는 부분적으로 'ShareGPT'의 Multilingual Language Instructions 덕분이라고 이야기된다.
→ Language Instruction Following Capability transferred to Multi-modal Capability
→ Compositional Capability
5.4. Ablation on LLM choices
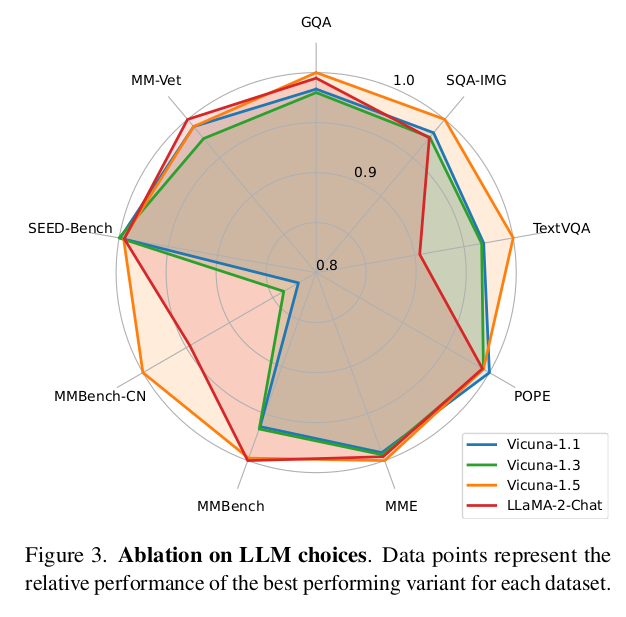 → Importance of the base language model
→ Importance of the base language model
6. Open Problems in LMMs (Ablation)
6.1. Data Efficiency
with only 50% of the samples, the model still maintains more than 98% of the full dataset performance
→ This suggests that there is room for further improvements in data efficiency.
6.2. Hallucination
LLaVA-1.5 Researchers found that
_hallucination is significantly reduced, when the image inputs are scaled up to higher resolutions.
However, when the input resolution is not sufficient for the model to discern all details in the training data, and the amount of data that is at that granularity beyond the model’s capability becomes large enough, the model learns to hallucinate.
→ Balanced scaling of the Models and Data (required)
6.3. Compositional Capabilities
LLaVA-1.5:
the model trained on a set of tasks independently generalizes to tasks
that require a combination of these capabilities without explicit joint training.
- multilingual multimodal conversations
- visual knowledge from the academic-task-oriented datasets
- visual groundness
However, still lack of certain combination of capabilities
- Global Context 속에서의 개별 Local object에 대한 상세한 이해 부족
- Certain foreign languages (e.g. Korean)에 대한 이해 부족

→ Further Fine-Tune (Instruction Tune) the LLaVA-1.5 with task-adaptive datasets (required)
7. Conclusion
LLaVA-1.5:
Simple, effective, and data-efficient baseline for large multimodal models.
“Main Contributions”
- Simple but powerful MLP Vision-Text Connector
→ without Exhaustively pre-training with large datasets,
→ enhance the Vision-Text Alignment, in a data-efficient manner- More Capable (High Resolution) Vision Encoder (CLIP-ViT-L-336px)
→ enhanced Visual Groundness, reducing hallucinations- More Capable (More parameters) LLM Decoder (LLaVA-1.5-13B)
→ Broader Knowledge Coverage- Further Training with Short Form Answering Academic Oriented Dataset
→ optimal balance between the
→ “Long-form Natural Conversational Capabilities” and “Short-form Accurate Answer”- Compositional Capabilities
→ Facilitate Further Data-Efficient Training of Model
→ Much More Task adaptive in a [data, computational power] limited environment.- Open Source
“Limitations”
- prolonged training for high-resolution images
→ Because LLaVA-1.5 utilizes full image patches,
→ Sample-efficient visual resampler 필요
→ Q-Former와 같은 Visual Resampler를 통해, Decoder Input Image Patch 감소 가능
→ But, Training / Data Efficiency 의 장점이 사라질 수도 있고
→ Vision-Text Alignment가 망가질 수도 있기에, 여러가지 시도해볼 필요 존재.
→ 우선, Learnable Query에 기반하여 간단한 Cross-Attn 구조 시도해볼 수 있을 듯.
→ Single Transformer BLock?- lack of multiple-image understanding
→ due to the lack of such instruction-following data
→ due to the limit of the context length
→ LLaVA 1.5는 단일 이미지를 처리하는데 최적화
→ 여러 이미지간의 유사성, 차이점, 시공간적 관계성을 처리하는데 한계
→ 시공간적 변화를 학습할 수 있는 데이터셋으로 추가적인 Instruction Tuning (Required)- Limited problem solving capabilities in certain fields
- hallucinations
→ Task-Specific-Dataset으로 Instruction Tuning (required)
