
[Daily report] 26-05-26
LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation 이 논문이 언급하고 있는 주요점은 크게 3가지로 나눌 수 있다. NVFP4 연산 4비트로 데이터가 표현되기 때문에 기존의

바이브 코딩으로 앱만들기
완성된 앱은 하단 링크를 통해 다운받을 수 있습니다.https://apps.apple.com/us/app/star-clear/id6757729574새해에 개인 프로젝트로 바이브 코딩에 도전해보았습니다.바이브 코딩에는 관심이 있었는데 가장 접근하기 쉬운 코파일럿
결산과 피할 수 없는 1일
긴 글이 될 수도 있을 것 같다.남들이 서로 앞다퉈 신년 계획과 목표를 짜는 동안 나는 그런 것들을 짜고 싶지 않다는 생각을 했다. 다만 새해가 되어서야 한 해를 글로 적어내릴 결심을 했을 뿐이다. 25년에 정리한 생각들을 나누어보고자 한다.25년 2월 드디어 대학원을
[Daily report] 25-12-02
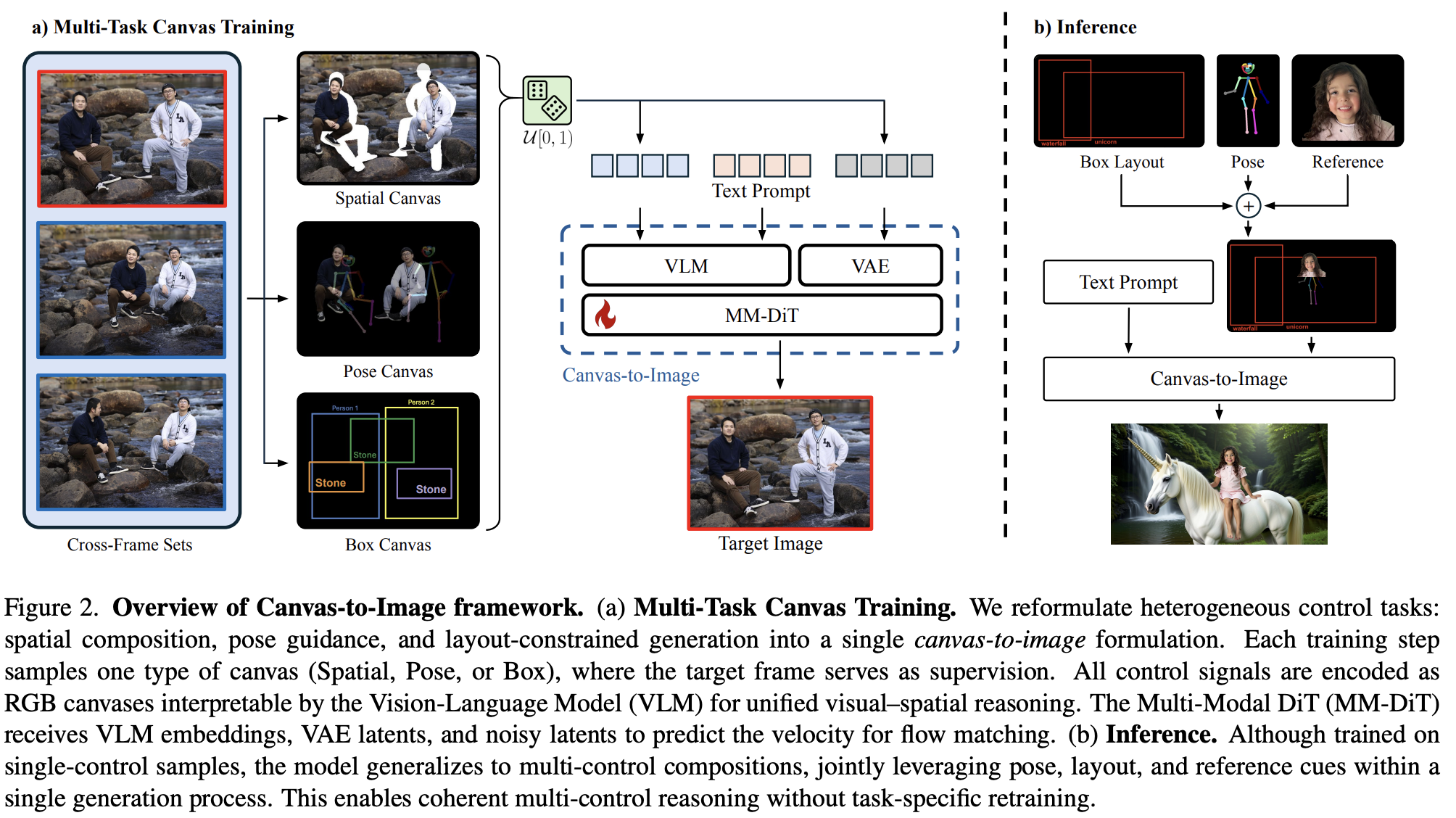
Canvas-to-Image: Compositional Image Generation with Multimodal Controls 큰 구조는 각 canvas에 대해 (Spatial, Pose, Box) supervision으로 학습하여 inference에서 can
[Daily report] 25-11-14
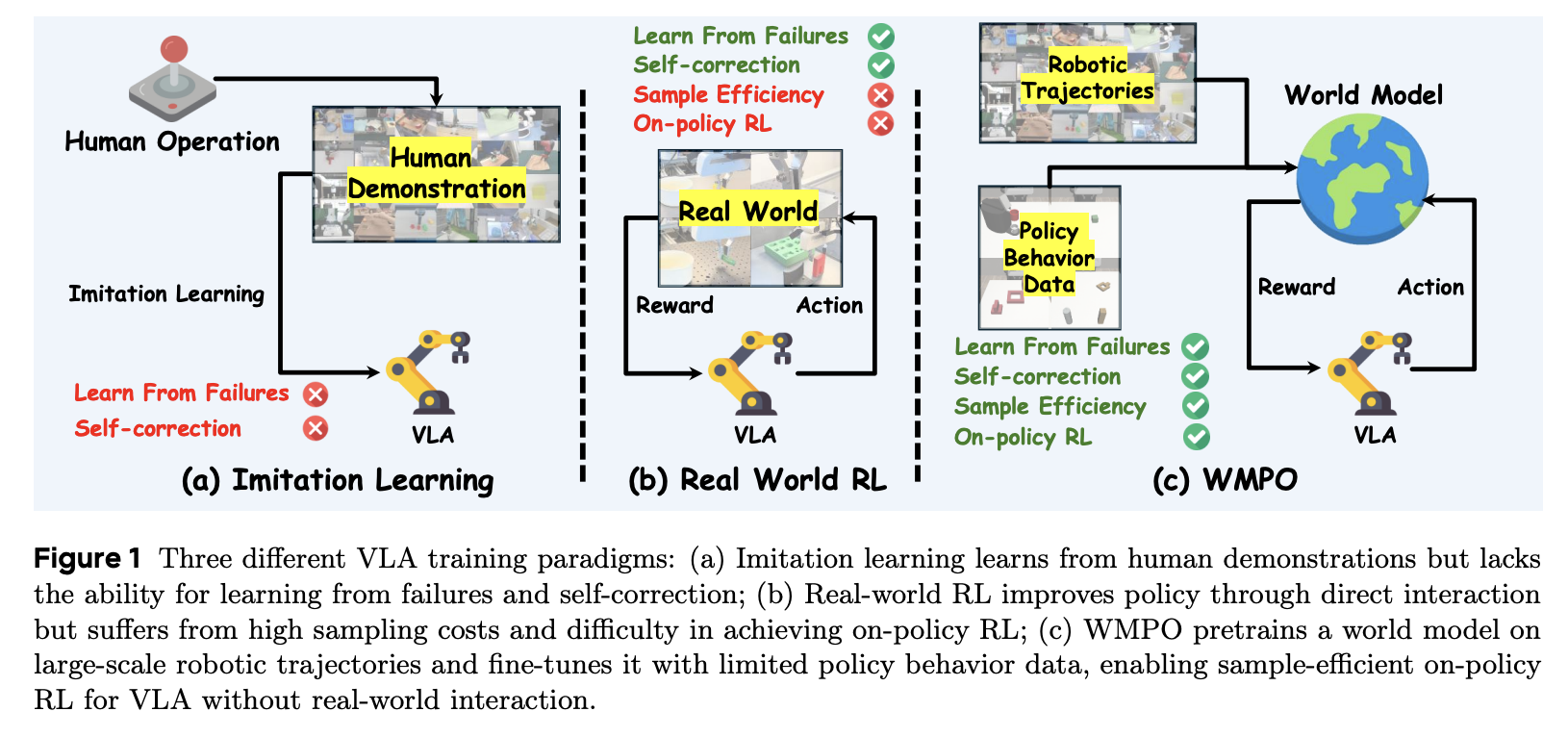
Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising Nvidia 논문. 결과물을 보고 육성으로 "미친 거 아니야?"라고 했다. 왜냐면 training free라고
[Daily report] 25-11-12
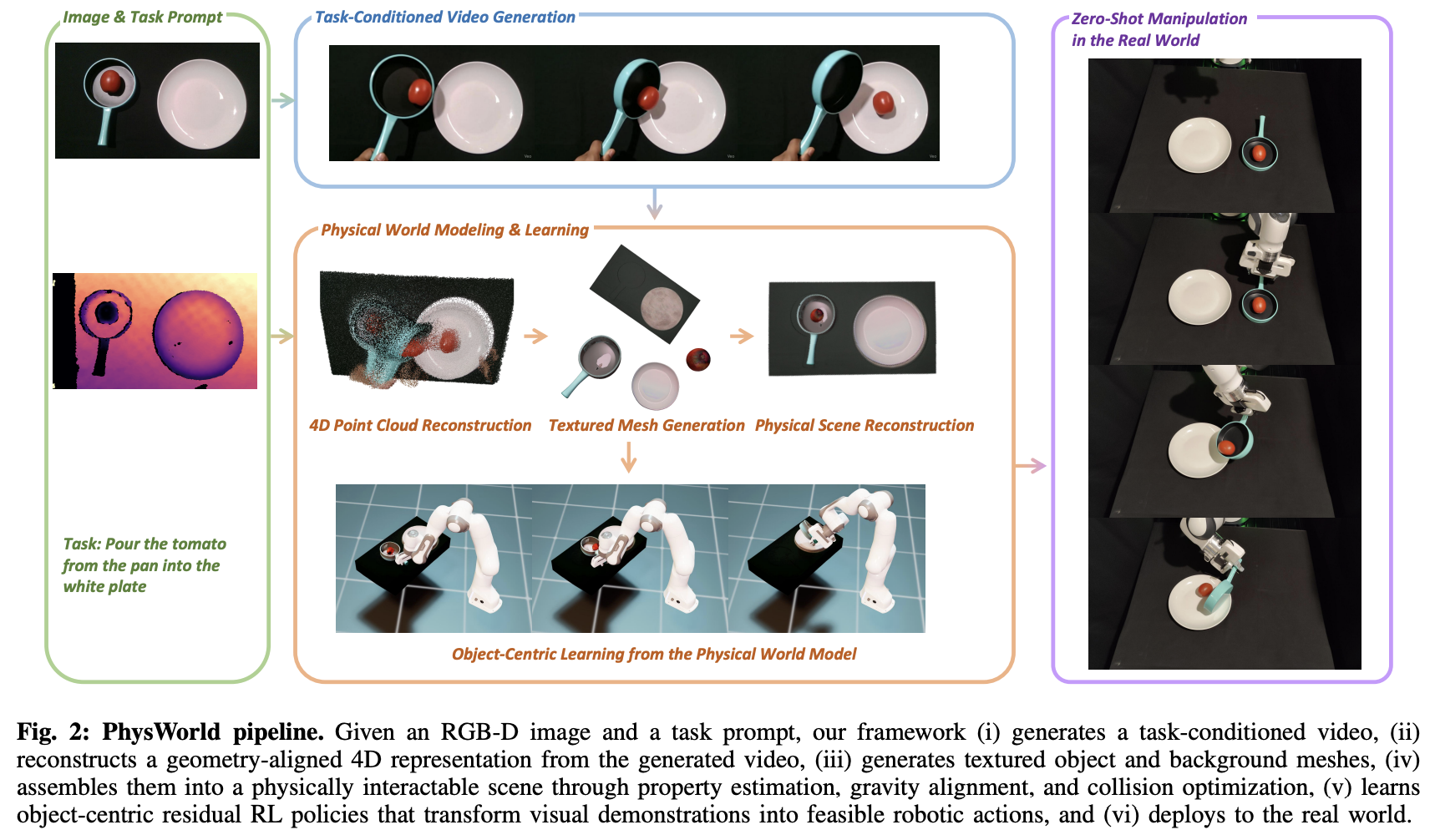
Robot Learning from a Physical World Model 비디오를 따라 zero-shot으로 로봇의 움직임을 만드는 연구. 기존의 비디오 관련 로봇 연구는 많은 데이터가 필요하거나 사람의 개입이 필수적이었는데 이를 최소화하여 zero-shot으로

[Daily report] 25-11-03
★ThinkMorph:Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning 텍스트와 이미지의 chain of thought을 합쳐서 보는 것이 아닌 상호 보완적으로 보는 것이 핵심. Ques
[Daily report] 25-10-20
WithAnyone: Towards Controllable and ID-Consistent Image Generation모델 자체엔 엄청 특이하거나 특별하게 느껴지는 새로운 구조는 없다. 다만 데이터셋 수집 방법이나, 이걸 진짜 다? 싶을 정도로 짜임새가 좋다. 뭔가
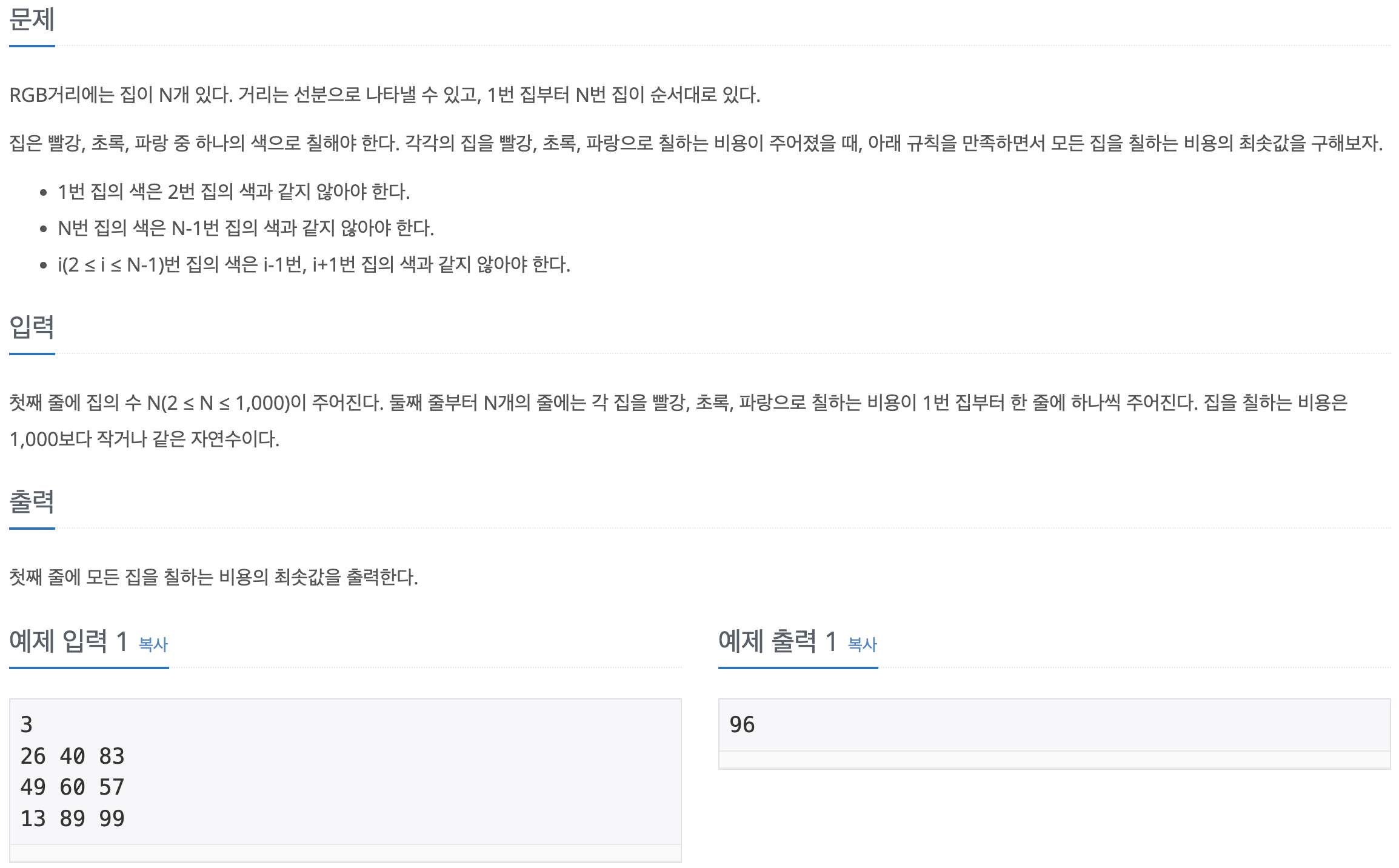
[백준-파이썬] 1149-RGB거리
문제바로가기i번째 위치에 있을 때, 각각 R G B을 선택했을 때의 최소값을 계산하면 모든 경우의 수를 확인할 수 있다. 이후 마지막 row의 최소값이 정답이 된다.

[백준-파이썬] 1753-최단경로
문제바로가기완벽히 다엑스트라 구현 문제이다. 처음에 구현한 코드는 잘 돌아가지만, 인접리스트로 구현했기 때문에 메모리 초과를 피할 수 없었다. 왜냐하면 v가 커질수록 더 많은 메모리가 필요한데 최대 v는 20000이므로 10^8을 수용할 수 있는 메모리가 필요하다. 굉
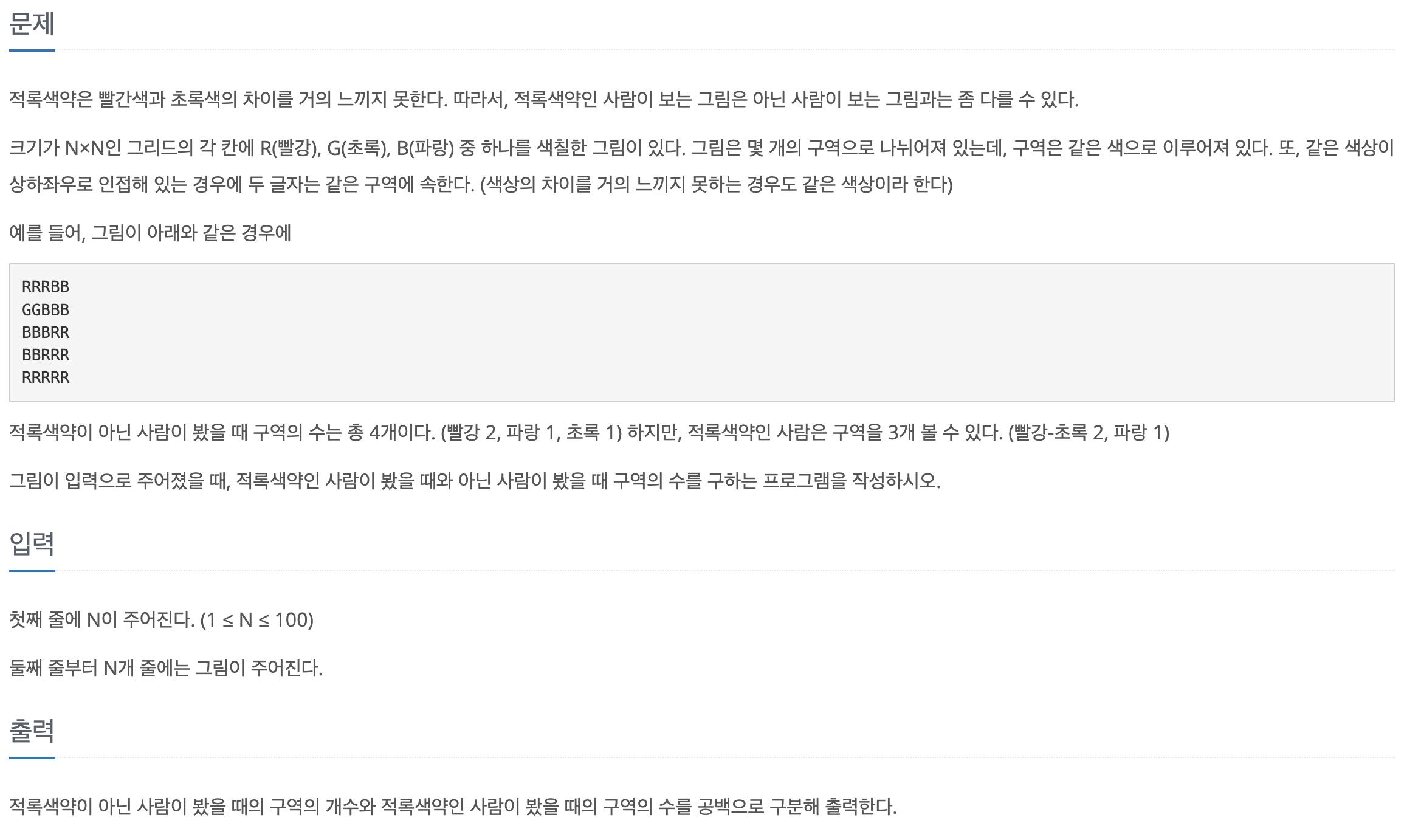
[백준-파이썬] 10026-적록색맹
문제바로가기2178과 2160을 섞은 문제다.핵심은 사방의 (좌우상하) 값을 보고 같은 지 비교해야 하는 것이다. 처음에 이중포문 없이 구현하겠다고 last_r, last_c를 선언하여 끝나는 지점의 인덱스를 저장하고 한칸 이동하여 다시 search를 했더니 예제의 G
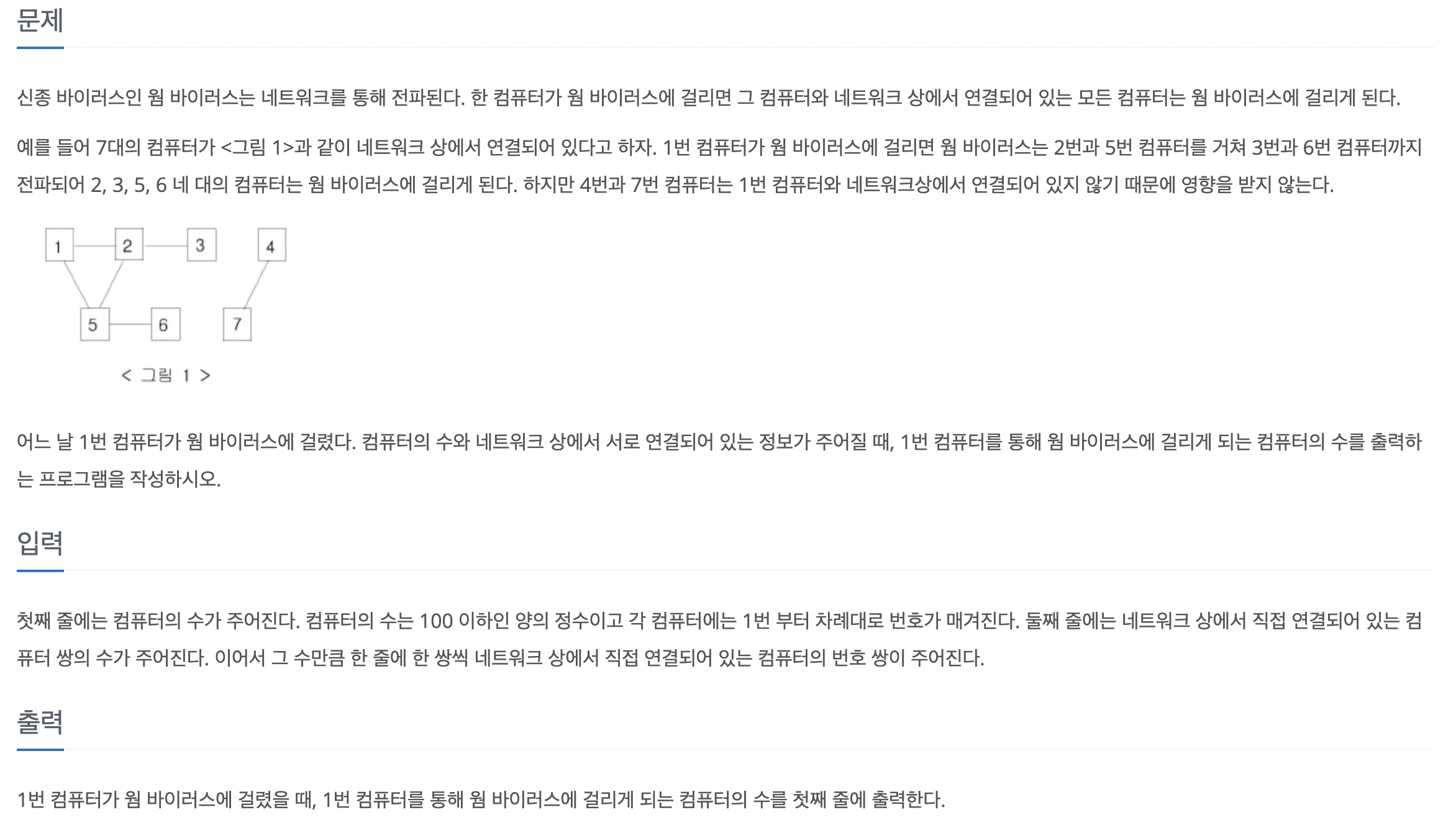
[백준-파이썬] 2606-바이러스
문제바로가기1번 컴퓨터에 연결된 모든 컴퓨터의 개수를 세는 문제로 bfs나 dfs를 구현하는 문제이다. 나는 평소에 dfs로 문제풀이를 많이 하기 때문에 이번엔 bfs로 코드를 짜보았다.마지막에 count-1을 해주는 이유는 1번 컴퓨터도 개수 집계가 되기 때문이다.
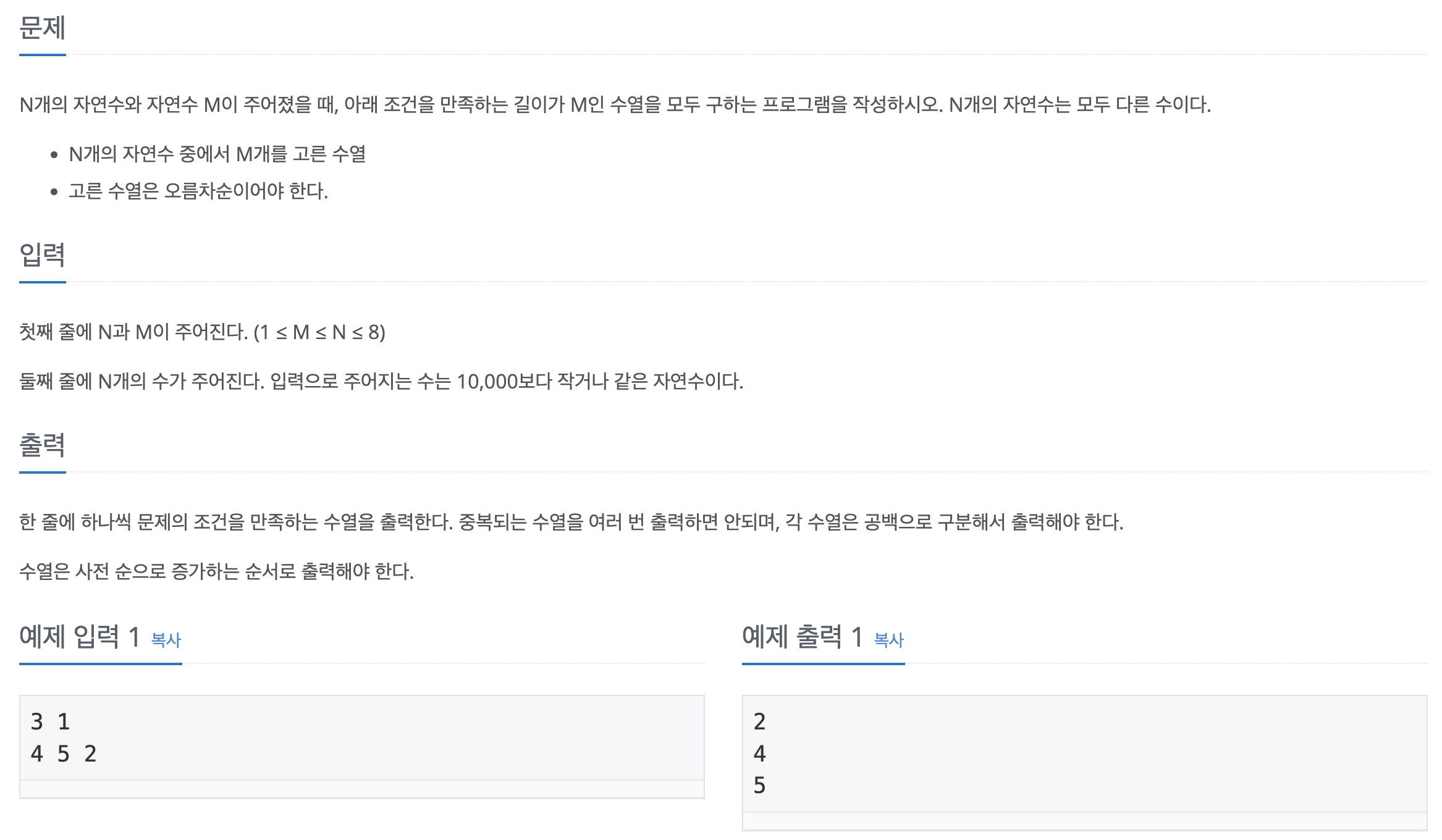
[백준-파이썬] 15655-N과 M(6)
문제바로가기여기서 주의해야할 점은 print(\*nums) 부분이었다. 출력양식이 대괄호 \[] 없이 숫자만 띄어쓰기로 구분해서 출력해야함!이 문제도 역시 N과 M 시리즈를 풀었다면 쉽게 금방 풀 수 있다.
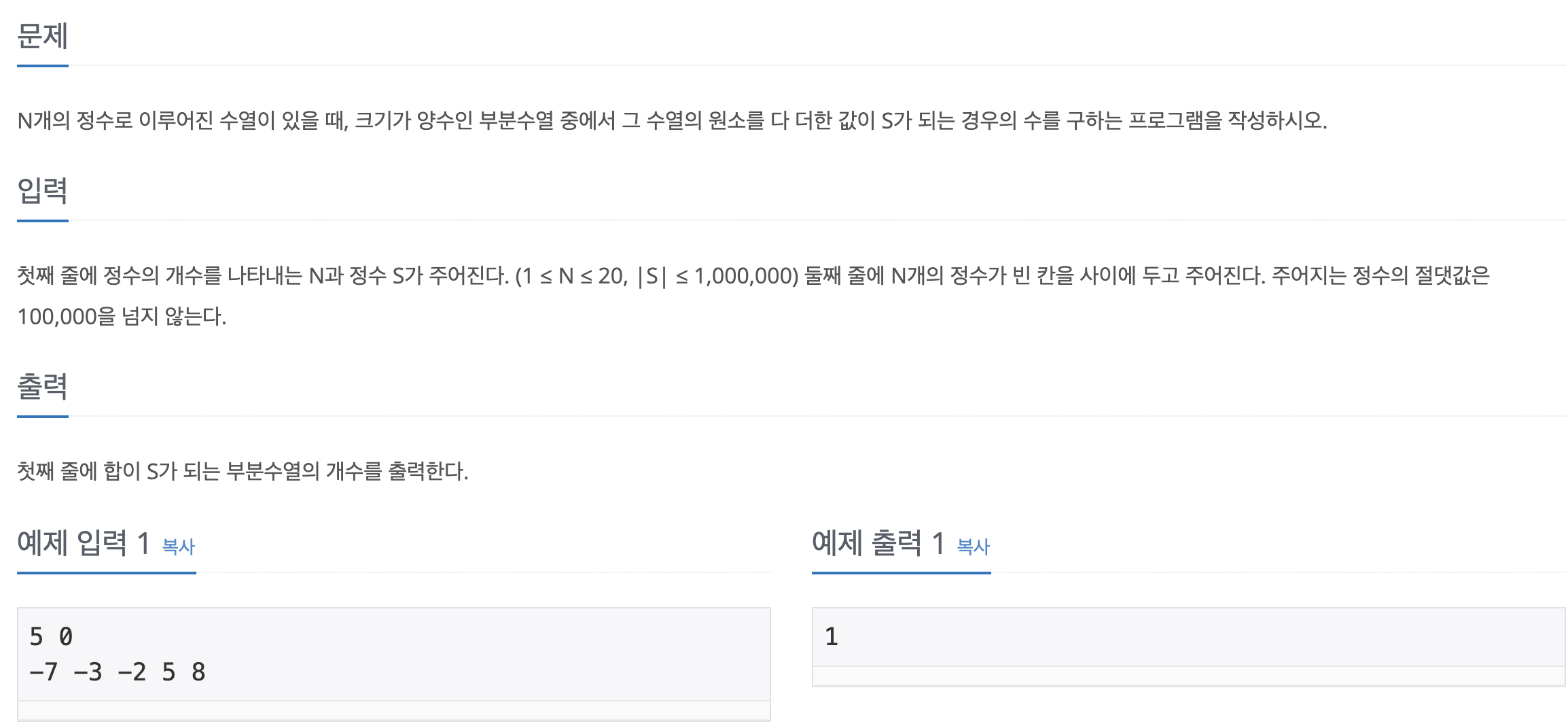
[백준-파이썬] 1882-부분수열의 합
문제바로가기N과 M 문제 시리즈의 변형 같은 문제.단지 멈추는 조건이 조합의 합이 S가 될 때로 바뀐 것 뿐이다. 한가지 간과한 것은 s가 0일 때 combi가 \[]인 경우도 포함되어서 count가 올라갔었다. 그래서 추가로 combi에 무조건 값이 있어야 한다는 조
[백준-파이썬] 2457-공주님의 정원
문제바로가기업로드중..이 문제의 핵심은 기준 날짜보다(초기값 3월1일) 앞서서 피는 꽃을 찾아야 하고, 그 꽃들 중에서 가장 오래 피어있는 꽃을 선택해야한다. 그리고 선택된 꽃이 지는 날이 다시 기준 날짜가 된다는 것이다. 이 아이디어만 생각하면 구현은 금방한다.마지막
[Daily report] 25-08-20
SSRL: SELF-SEARCH REINFORCEMENT LEARNING 칭화대, 상하이AI랩, 런던대 등 다수의 저자진이 연구했다. 스스로 검색을 통해 (Bing, wikipidia, google 등) policy 모델을 업데이트 한다는 방법을 제시한 연구이다.(퍼

[백준-파이썬] 1715-카드정렬하기
문제바로가기최종합이 적어지려면 작은수 두개씩을 묶어 더해나가면 된다. 이런 생각으로 처음에는 간단하게 배열을 정렬하고 작은수를 pop하면 두개를 더한 값이 다른 수보다 클테니까 이걸 push해서 반복해나가면 되겠다는 아주 단순한 생각이었는데 항상 두 수를 더한 값이 큰

[백준-파이썬] 13305-주유소
문제바로가기업로드중..위 코드는 41점짜리다. 서브테스크 문제라서 n의 크기에 제약이 있으면 점수를 절반만 준다. 위 코드가 시간 복잡도가 큰 이유는 min연산이다. min만보더라도 $O(n)$인데 이걸 for문만큼 반복하기 때문에 총 $$O(n^2)$$만큼의 복잡도를

[백준-파이썬] 11399-ATM
문제바로가기누적합이 적으려면 앞사람의 처리시간이 적어야 한다. (그래야 뒷사람이 오래 안기다리기 때문.) 그래서 작은 순으로 정렬하고 모든 값을 합해주면 끝. 간단하게 완료.
[Daily report] 25-08-18
D2F: Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing기존 LLM보다 처리속도를 줄인 모델. 정리를 잘해놓았다. 기존 LLM이 연산 시간이 오래 걸리는 이유는 크게 2가지로 첫