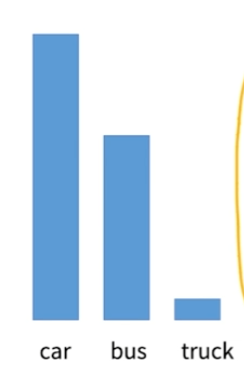
데이터 분류시에 데이터가 골고루 분포해 있는 경우는 오히려 찾기 힘들다.
차량 분류시에 승용차, 버스, 트럭이라고 한다면 트럭의 비중이 작을 가능성이 낮고, abnormal detection 시에도 abnormal한 예외 상황은 흔히 발생하는 케이스가 아니다.
Focal Loss
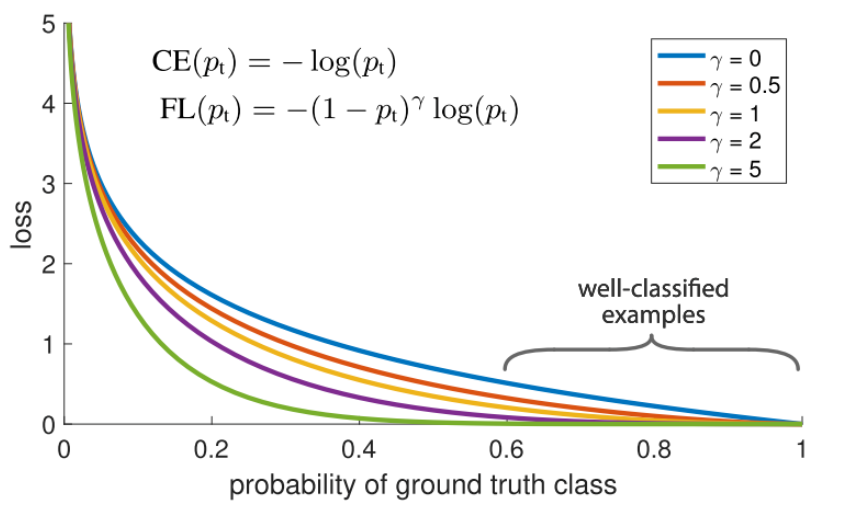
loss 계산시에 현재까지의 클래스별 정확도를 고려하여 가중치를 별도로 주는 Loss Function을 적용하는 방식 = Focal Loss
epoch마다 현재까지 분류 성능이 이미 높은 클래스에 대해서는 가중치를 낮게 부여하여 덜 신경쓰게 하고, 대신 분류 성능이 낮은 클래스에 더 집중하게 하는 전략이다.
Class Weight
weights = torch.FloatTensor([1/20, 1/20, 1/20, 7/20, 1/20, 7/20, 1/20, 1/20, 1/100]).cuda()
criterion = torch.nn.CrossEntropyLoss(weight=weights)이런식으로 단순하게 class마다 weight를 부여하는 방법도 있다. 클래스별 가중치 비율을 CrossEntropyLoss에 넘기는 것이다.
Over/Under Sampling
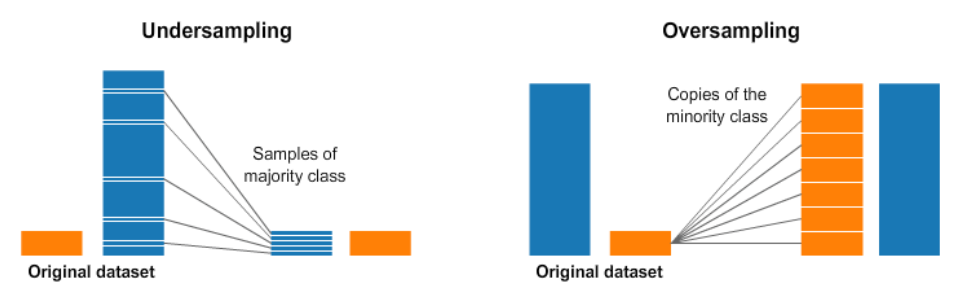
단순히 데이터가 많은 쪽을 덜어내거나, 데이터가 부족한 쪽을 복사 붙여넣기하여 무작정 늘리는 것이다. 차라리 데이터가 imbalance 한 것보다는 이런 식으로라도 균형을 맞추는게 낫다고 한다.
Data Augmentation
데이터 증강을 통해 해결하는 방법도 있다. 즉, 데이터의 특성을 다양하게 변형시키고 이러한 데이터를 추가적으로 학습하여 데이터가 늘어난 효과를 보는 것이다.
다만 대부분의 경우, 증강된 데이터는 원본에 비해 그렇게 많은 양의 정보를 포함하고 있지는 않다. 실세계에서 얻을 수 있는 데이터가 당연히 가장 품질이 좋고 정보량이 많은 것은 어쩔 수 없지만, 부족한 데이터 양을 보충하거나, 실세계에서 발생할 수는 있으나 발생 가능성이 낮은 데이터를 생성하거나 하는 등의 이점이 있다.