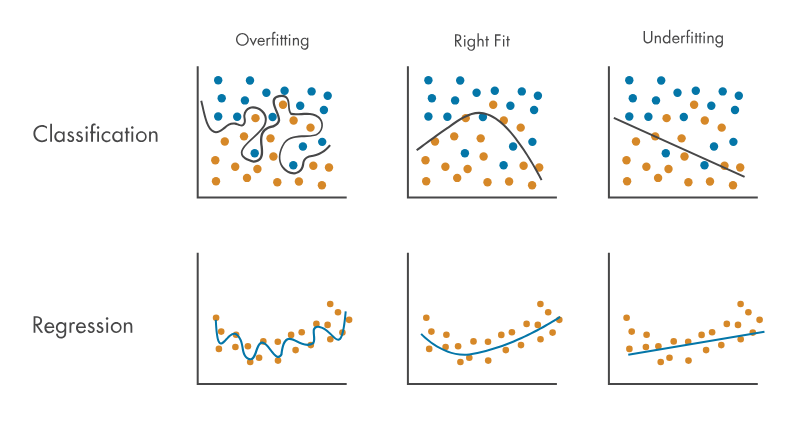
- 언더 피팅 : 모델이 그냥 학습되지가 않은 것이다. 이 경우 모델 자체가 아예 잘못된 구조가 아닌 이상 많은 학습을 하게되면 어느정도 해결이 된다
- 오버 피팅 : 모델이 과하게 학습되어 train data에서만 동작하는 경직된 모델이 된다. 즉 robustness가 없는 모델이다
잘 학습된 모델은 일반화가 잘된 모델이다. 위 그림에서처럼 완벽한 분류 또는 회귀를 하는 것은 아니지만, 어떠한 데이터가 들어와도 '꽤' 잘 동작하는 것이 좋은 모델이다.
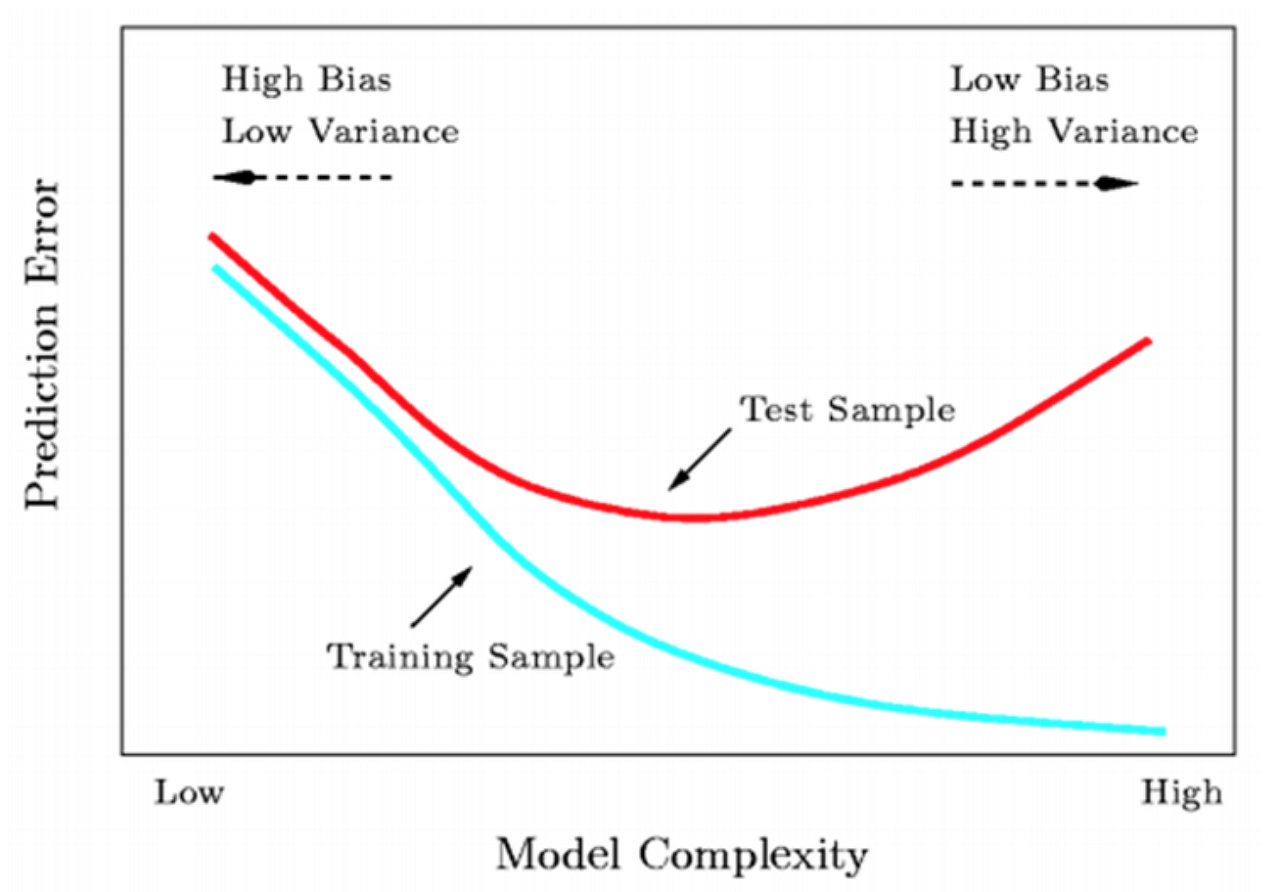
그렇다면 꽤 잘 동작한다는 것을 어떻게 정량적으로 판단할 수 있을까
train loss는 계속하여 감소하지만, validation set에 대한 loss는 어느순간 우상향 하게 되고 이 시점이 오버피팅의 시작점이다. 다만 그러한 지점이 local한 상황일 수도 있어서 보통은 patience를 두어 어느정도까지는 지켜보기도 한다.
그래서 대부분의 경우 validation loss가 global하게 낮은 모델을 best 모델로서 취한다.
Overfitting 해결책
모델의 일반성을 높일 수 있는 다양한 방법들이 사용된다
- 데이터를 추가하거나 증강한다
- 데이터 검수 : 데이터가 편향되어 있거나, 과도한 outlier를 포함하고 있지 않은지, 결측치(NaN, N/A 등)를 내재하고 있지 않은지
- Model의 구조를 단순화한다
- Regularization이나 Normalization
- Dropout : 일부 노드를 랜덤하게 제거하여 variance를 높인다
- Early Stopping : val loss가 상승하는 순간부터 학습을 종료한다
- feature engineering : 여러 피쳐 엔지니어링 기법을 적용한다. 여기에는 도메인에 맞게 커스텀 로직을 적용하거나, 전처리를 통해 저차원화 시킨 데이터를 입력으로 넣는 것(PCA)도 포함된다.
- weight decay : weight 계산시에 weight 값을 일정 이상 커지지 않게 하는 항 추가
Undefitting 해결책
- 더 많은 학습 (epoch를 늘린다)
- 데이터를 추가하거나 증강한다
- Model의 구조를 복잡화한다
- learning rate를 높인다 : 너무 느린 learning rate로 loss가 본격적으로 감소하기 까지 오랜 기간이 걸리는 것일 수도 있음
Python, CV, ML, Backend