머신러닝
1.모델 성능 평가 지표
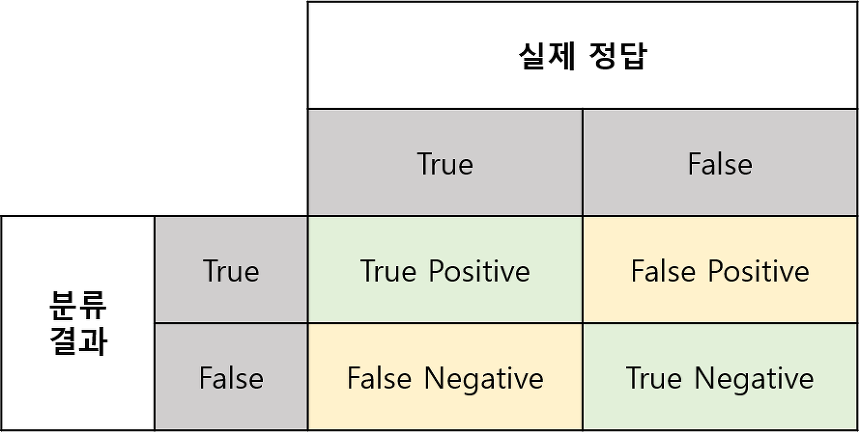
좌우로 나뉜 영역에서 좌측은 실제 True인 영역이고, 우측은 실제 False인 영역이다.원으로 그려진 영역은 모델이 True로 추정한 영역이다.True / False : 추정이 맞았다 / 틀렸다Positive / Negative : True로 추정을 했다 / 하지 않
2.Intra/Inter Class Variability
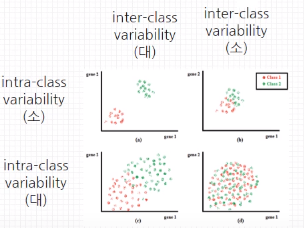
데이터의 분포에 대한 개념이다.Intra Class Variability : 클래스 내부 다양성 → 낮을수록 좋다Inter Class Variability : 클래스 간 다양성 → 높을수록 좋다Variability가 아니라 Distance라고 생각해도 좋다A라는 분
3.Class Imbalance
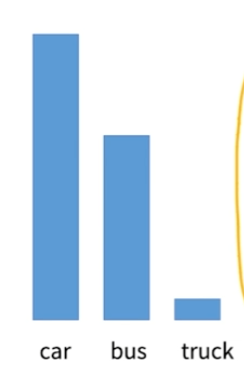
데이터 분류시에 데이터가 골고루 분포해 있는 경우는 오히려 찾기 힘들다.차량 분류시에 승용차, 버스, 트럭이라고 한다면 트럭의 비중이 작을 가능성이 낮고, abnormal detection 시에도 abnormal한 예외 상황은 흔히 발생하는 케이스가 아니다.loss 계
4.Over Fitting
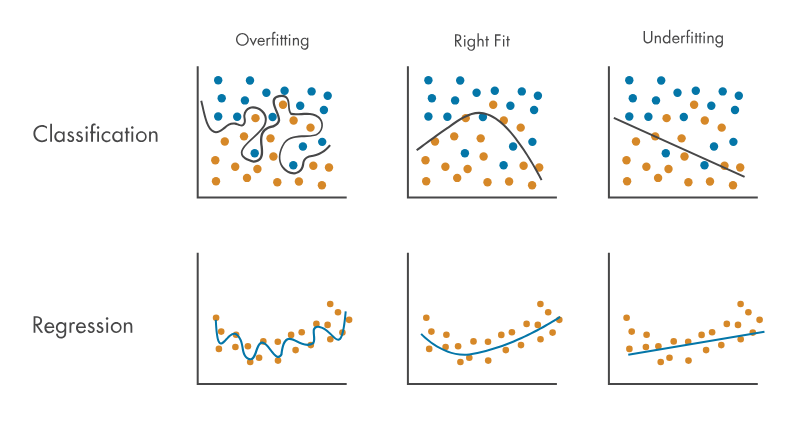
언더 피팅 : 모델이 그냥 학습되지가 않은 것이다. 이 경우 모델 자체가 아예 잘못된 구조가 아닌 이상 많은 학습을 하게되면 어느정도 해결이 된다오버 피팅 : 모델이 과하게 학습되어 train data에서만 동작하는 경직된 모델이 된다. 즉 robustness가 없는
5.Image Augmentation

데이터가 모자랄때는 데이터를 추가하면 가장 좋겠지만, 더 이상 데이터를 추가하기 어려울 수 있다. 또는 데이터는 있는데 레이블링 작업이 어려울 수도 있고, 기존 데이터를 가지고 발생할 수 있는 상황을 예측해서 데이터를 만들어야 될 수도 있다. 이 때 유용하게 사용되는
6.Activation Function
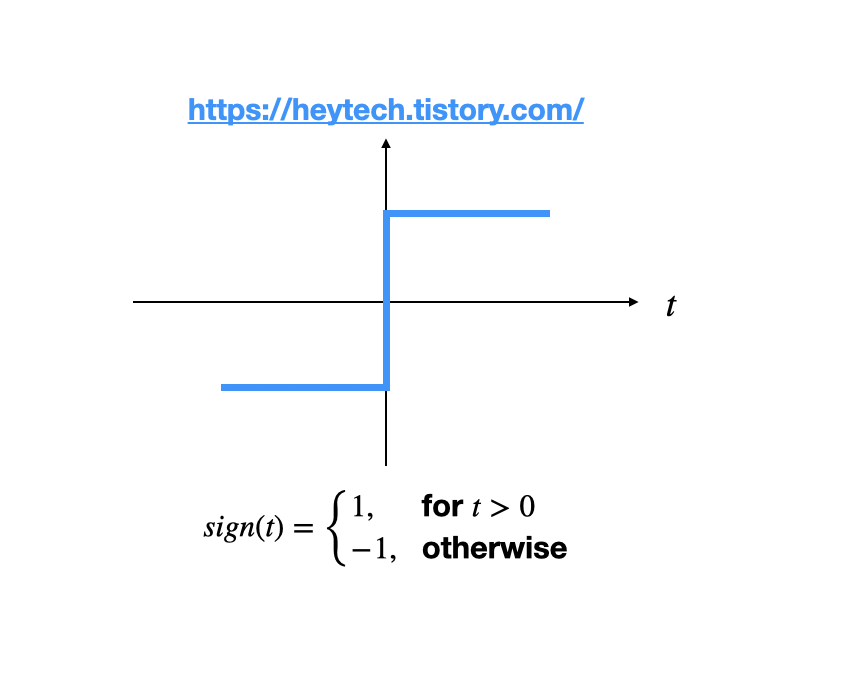
퍼셉트론의 어떠한 노드에서의 출력 값을 간략화하면 y = f(wx+b) 정도로 표현할 수 있는데 여기서 f가 활성화 함수이다. weight를 곱하고 bias를 더한 후에 일정한 threshold에 따라 최종 출력이 결정되는 것이다.위와 같이 단순히 0보다 크냐 작냐로
7.Weight Initialization
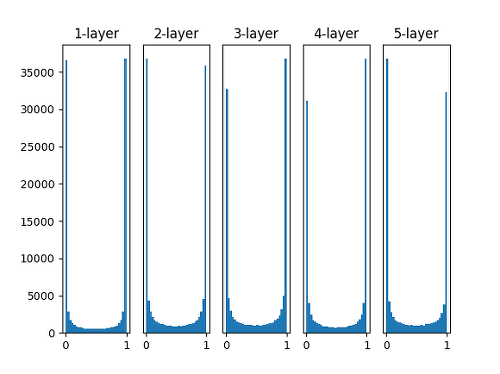
가중치를 따로 설정하지 않고 전부 0인 상태에서 시작하면 전체 뉴런들이 대칭성을 가지게 되어 variance가 약해지게 된다. 또한 gradient vanishing 현상이 심화될 수 있다랜덤하게 가중치를 초기화하므로 위에서 언급한 대칭성이나 기울기 소실 문제는 피할
8.Transfer Learning
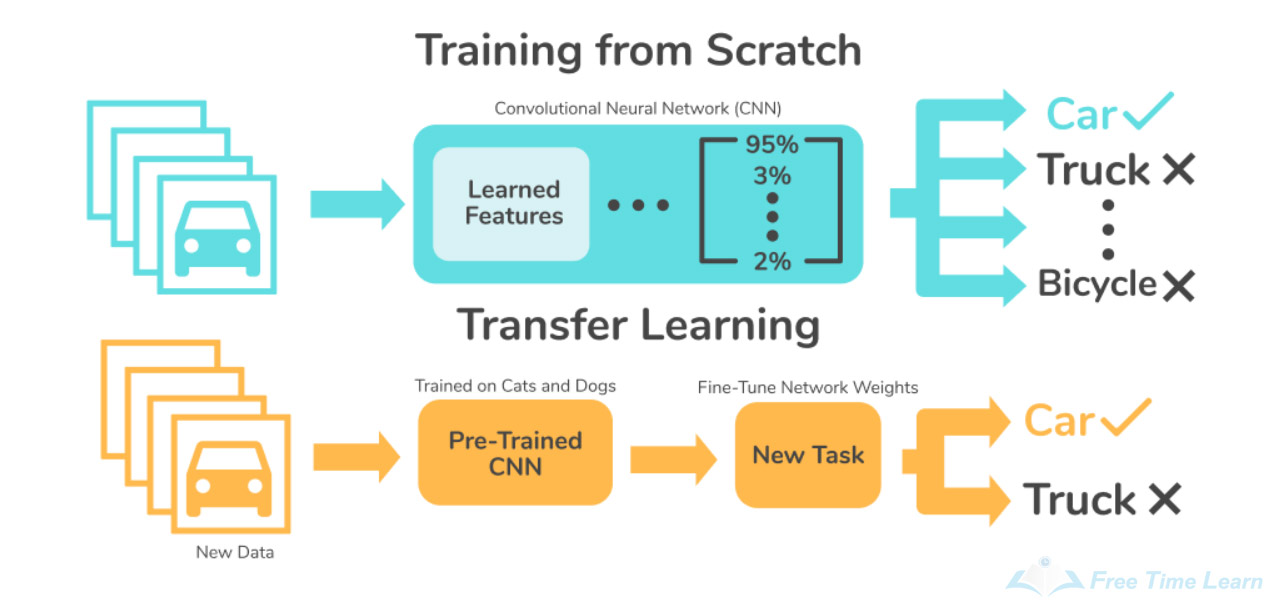
Transfer Learning 또는 Fine Tuning 이라는 기법은 사전 학습된 모델을 활용해 적은 데이터 셋으로도 모델의 성능을 끌어올리는 기법이다.예를 들면 VGG16 기반으로 fine tuning 하는 방법이다.torchvision에서 VGG 모델을 가져오고
9.Learning Rate
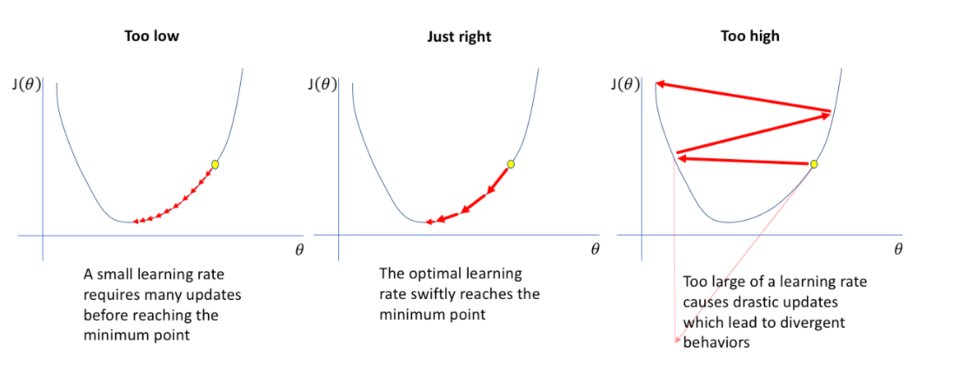
머신러닝에서 Learning Rate란 학습률 이라고도 불리며, 학습 시에 얼마나 빠르게 optima에 수렴하는 지를 결정하는 요소 중 하나이다.위 공식에서 Loss에 weight 값을 편미분하여 gradient (기울기) 를 계산하는데, 이 값이 높으면 높을수록 그
10.Optimizer
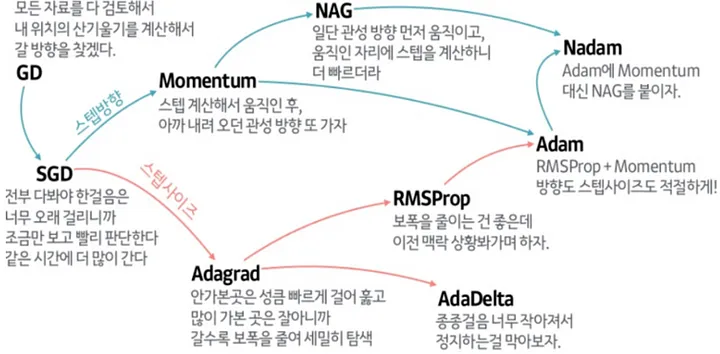
Gradient Descent (GD) 과정을 효율적으로 수행하게 해주는 것이 Optimizer이다.다만 GD는 모든 데이터 셋을 전부 이용해서 기울기를 계산하므로 현실적이지 않아서 여러 해결책이 등장하게 되었다.위 그림처럼 local minima에 빠져버리는 문제도
11.Normalization
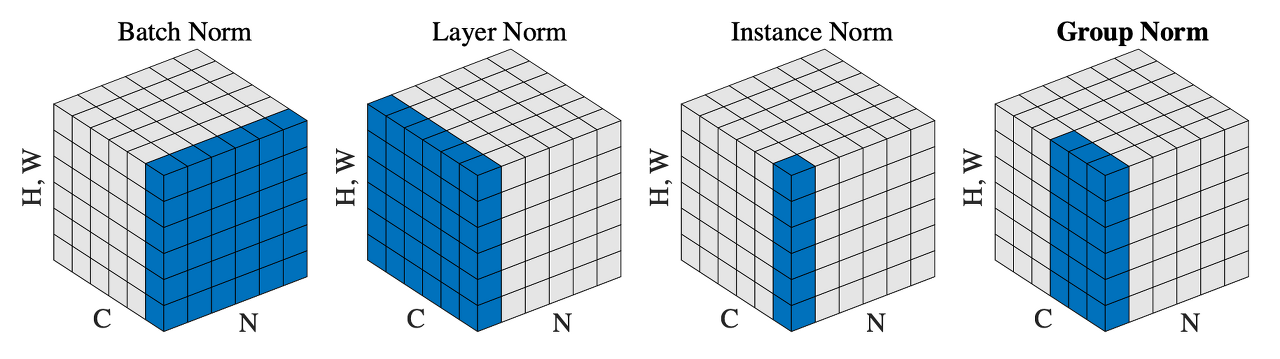
일반적으로 네트워크에서 사용되는 대표적인 Normalization은 Batch Normalization이고, Conv 레이어 중간중간에 넣어서 말 그대로 데이터 정규화를 해준다.예전엔 ICS (Internal Covariate Shift) 라는 Train 셋과 Test