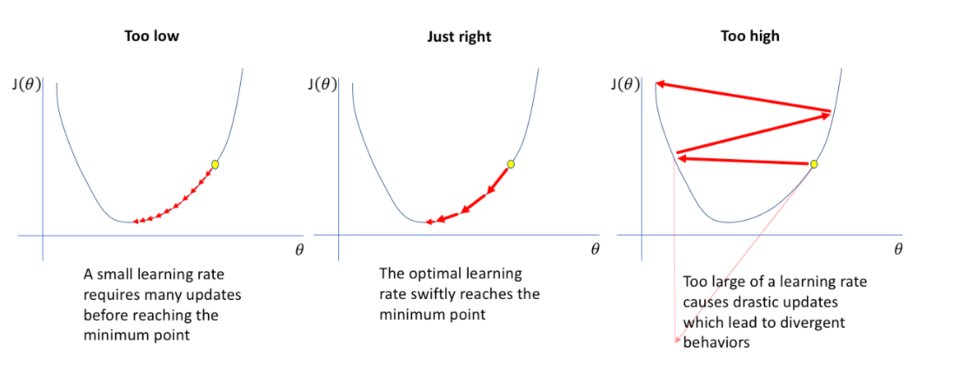
머신러닝에서 Learning Rate란 학습률 이라고도 불리며, 학습 시에 얼마나 빠르게 optima에 수렴하는 지를 결정하는 요소 중 하나이다.
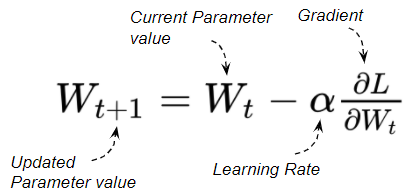
위 공식에서 Loss에 weight 값을 편미분하여 gradient (기울기) 를 계산하는데, 이 값을 기존 값에 빼준다. 즉, 기울기와 반대 방향으로 이동하는 것이다
쉬운 이해를 위해 이차함수 위에서의 움직임을 생각해보면, 우리는 이차함수 위에 공을 떨어뜨려서 극소점을 향해 나아가게 하는 것이 목표이다.
- gradient가 높다 = 기울기가 양의 방향으로 가파르다 = 음의 방향으로 이동시킨다.
- gradient가 낮다 = 기울기가 음의 방향으로 가파르다 = 양의 방향으로 이동시킨다.
이러한 반복을 통해 결과적으로 극소점 (local optima) 에 도달하도록 만드는 것이다.
Learning Rate (lr) 는 위 공식에서 gradient의 계수가 되는데 그러므로 이동을 얼마나 크게 할지를 결정짓게 된다.
- learning rate가 높다 = 더 큰 보폭으로 이동시킨다
- learning rate가 낮다 = 더 작은 보폭으로 이동시킨다
다만 learning rate가 지나치게 큰 경우, 오히려 gradient가 발산해버릴 수 있어서 적당한 값을 지정해주어야 한다.
일반적인 초기 값으로는 0.1, 0.01, 0.001 등의 값이 시도된다.
decay와 scheduler
Learning Rate (이하 lr) 를 고정 값으로 하는 것보다 일정 epoch 마다 감쇠시키는 것도 하나의 학습 전략이다. 만약 고정된 값만을 사용한다면 다음과 같은 단점이 있다.
- 높은 lr을 사용하는 경우 : 일정 수준까지 빠르게 loss가 감소하다가, 그 이후 진동하면서 더 이상 낮아지지 않음
- 낮은 lr을 사용하는 경우 : 너무 학습이 느리고 많은 epoch이 소요됨. 또한 momentum이 부족하여 local minima에 빠질 수 있다.
pytorch의 scheduler 등을 사용해 lr을 일정 epoch마다 decay한다면 처음에는 lr을 크게 하여 빠르게 학습이 진행되도록 하다가, 나중에는 lr을 점차 감소시키면서 조금이라도 더 loss를 감소시키도록 할 수 있다.
사용 예시
StepLR
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)개인적으로 가장 많이 사용하는 것은 StepLR인데, 이를 이용하여 일정 step마다 lr에 gamma를 곱해주어 decay할 수 있다. 위 예시에서는 0.001에서 시작하여, 10 epoch마다 0.5가 곱해지는 것이다.

그 외에도 다양한 종류의 방식이 있다. milestone마다 decay하거나, exponential하게 하거나 등
ReduceLROnPlateau
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min')
for epoch in range(100):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)이 방식은 metric이 향상되지 않을때 decay하는 방식이다. scheduler.step에는 매번 metric 값을 넘겨주어야 한다.
CosineAnnealingLR
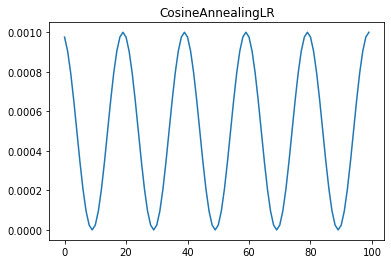
개인적으로 자주 사용하진 않지만 일정한 주기마다 lr을 갱신하는 전략도 있다.
CyclicLR 도 이와 비슷하게 cyclic하게 lr을 갱신한다.