
SSD란?
SSD란 Single-Shot multibox Detecter의 줄임말이다.
기존의 객체탐지 기술들(RCNN, Fast RCNN 등..)은 two stage processing방법을 이용하였다. 이는 RPN( Region Proposal Network )과 분류기로 구성이 된 형태를 말한다.
- two stage processing : Region proposal이후 classification을 순서대로 진행한다. 연산량이 많다는 단점이 있다.
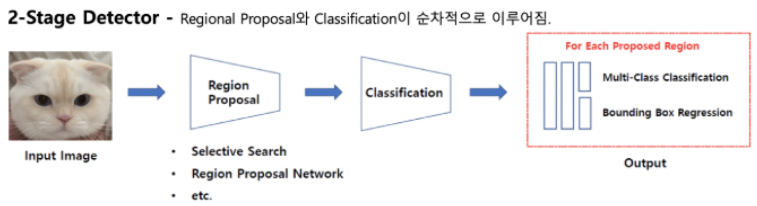
즉, 물체(object)가 있을 만한 위치 Region Proposal을 선정해 나가는 RPN을 통해 물체에 대한 BBox(Bounding Box)를 찾고, box내 물체에 대한 object type을 분류기를 통해 어떤 객체인지를 탐지해왔다.
하지만 이는 많은 연산량으로 인해 실시간으로 객체를 탐지하기엔 너무 느려 실생활에 적용시키기는 어려웠고 그 결과 one stage processing의 방법을 가진 여러 알고리즘이 제시되어 왔다.(ex. YOLO)
- one stage processing : Region proposal과 classification을 동시에 수행하여, two stage processing때보다 더 빠른 연산이 가능해지므로 실시간 객체 탐지가 가능하다. convolution layer를 통해 입력 이미지에 대한 특징 추출을 수행한다.
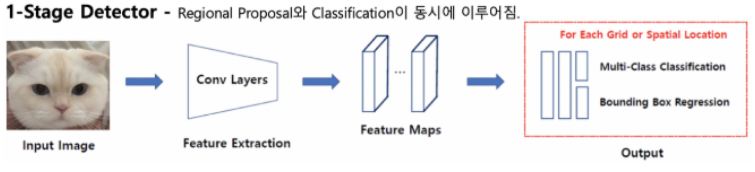
SSD는 객체 탐지에 있어 one stage processing 방식을 채택하여 실시간 객체 탐지를 가능하게 했다.
또한 기존의 YOLO가 처리 속도의 측면에서 보완을 많이 해주었으나 작은 object에 대한 탐지를 어려워했었는데, 이에 대한 어느정도의 보완도 이루어냈다.
이 포스팅을 통해 살펴볼 SSD는 어떠한 구조를 이루고 있는지 관련 용어들을 통해 대략적으로 이론적인 내용들을 살펴보도록 하겠다.
Architecture
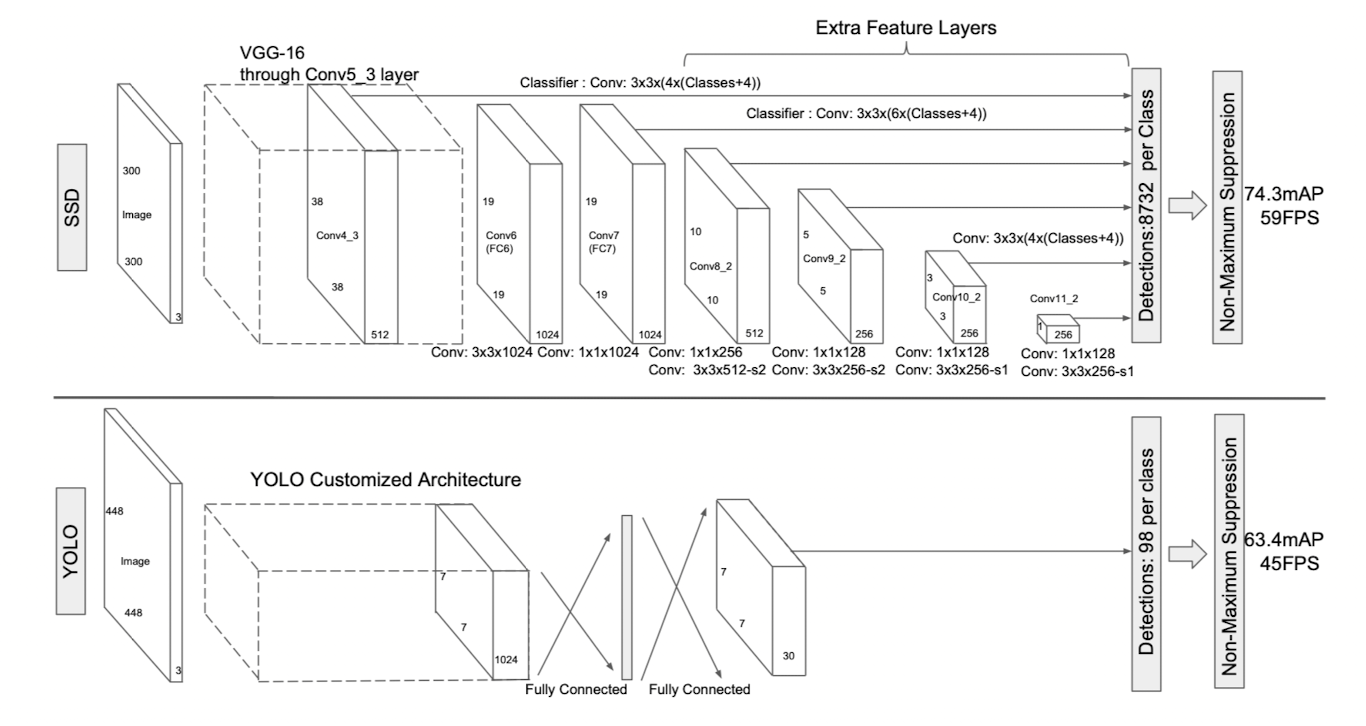
SSD는 기본적으로 VGGnet을 사용한다. 위 논문의 그림처럼 YOLO와 비교했을 때 SSD는 더 많은 feature층을 두었다.
VGG conv4_3층 이후 기존 FC(fully connected)층이 conv층으로 대체되어 있으며(conv 6, conv7), Extra feature층에서 추가 conv층을 두어 여러 conv층에서 feature맵을 추출한다.
conv4_3과 conv7에서 커널 크기가 각각 3x3( 4x( class+4 ) )와 3x3( 6x( class+4 ) )인 것처럼 볼드체로 표기된 자리의 숫자가 층마다 다른 것을 볼 수 있을 것이다. 잠시 후 살펴보겟지만, 이는 prior(anchor box)의 수를 나타내며 층별로 다른 수의 prior가 적용한 것이다.
conv층별로 feature map을 얻어낸 결과 최종적으로 prior들의 LOC( location )과 Class( class별 confidence score )에 대한 정보를 얻게 되며, 해당 텐서의 shape은 ( 1 x 8732 x 25 ) 이 된다.
저렇게 나온 ( 1 x 8732 x 25 ) 텐서에 비최대억제를 적용하여 객체를 탐지( location 예측 : Region proposal )하고, 객체의 type을 파악(분류 : classification)한다고 생각할 수 있다
그렇다면 8732개의 개수는 왜 나온 것이며, 25개의 열은 어떤 의미일까?
보다 쉽게 이해하기위해 아래 용어를 먼저 참고해보자.
관련 용어
Multi-scale Feature Maps
YOLO에서 작은 객체에 대한 탐지가 어려웠던 것을 보완한 방법이라고 한다.
이는 입력으로 들어오는 이미지에 대해, 이미지 각 셀마다 특정한 개수만큼의 Box들을 두어 객체를 탐지할 수 있는 범위를 늘렸다. conv층마다 다양한 크기와 개수의 feature map이 존재하기 때문에 이러한 이름을 가지게 된 것이다.
예를 들면 이미지 크기(5x5)에서 이미지 내 총 25개의 각각의 셀에 대해, conv9_2층에서는 셀마다 크기가 서로 다른 6개의 box들( 이 개수는 conv층 별로 정해져있다. )을 적용하여 객체를 찾아낸다고 생각하면 되겠다.
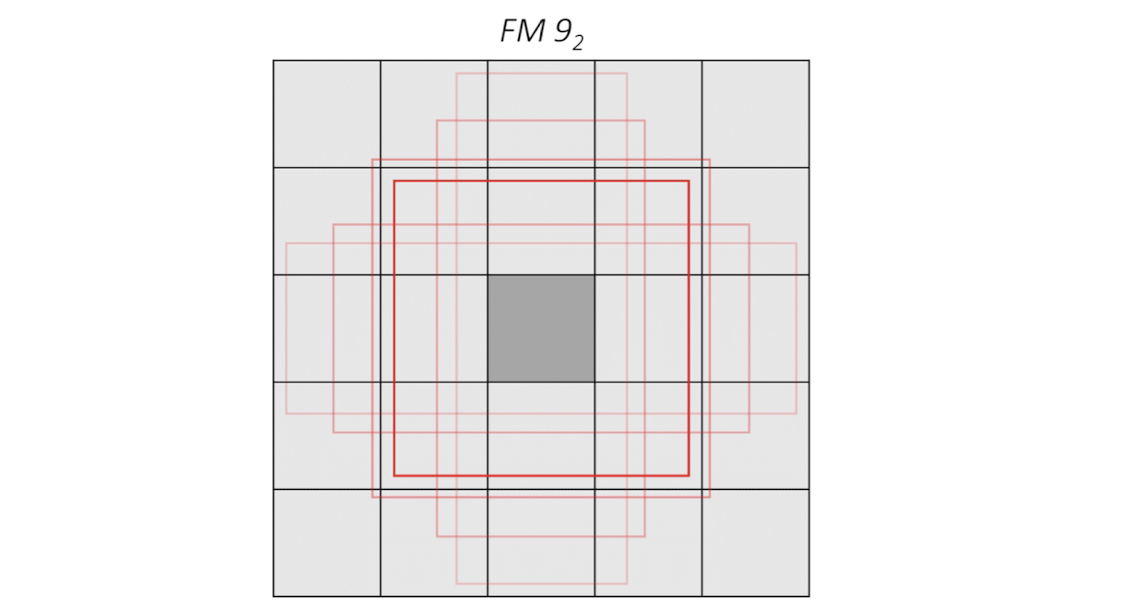
anchor box
위 그림처럼 가운데 셀에 대해 다양한 feature map들을 두어 찾아내는데 이를 anchor box라고도 한다. anchor box는 Priors 또는 default box라고도 하며, 이 box는 크기와 비율이 정해져있다. SSD에서는 prior라는 표현을 많이 쓰는거 같다.
처음 그림에서 출력텐서의 8732라는 숫자는 바로 이 prior의 개수를 의미하는 것이다.
- 8732
아래 그림은 source라는 출력을 하는 conv층에 대한 정보를 나타낸다.
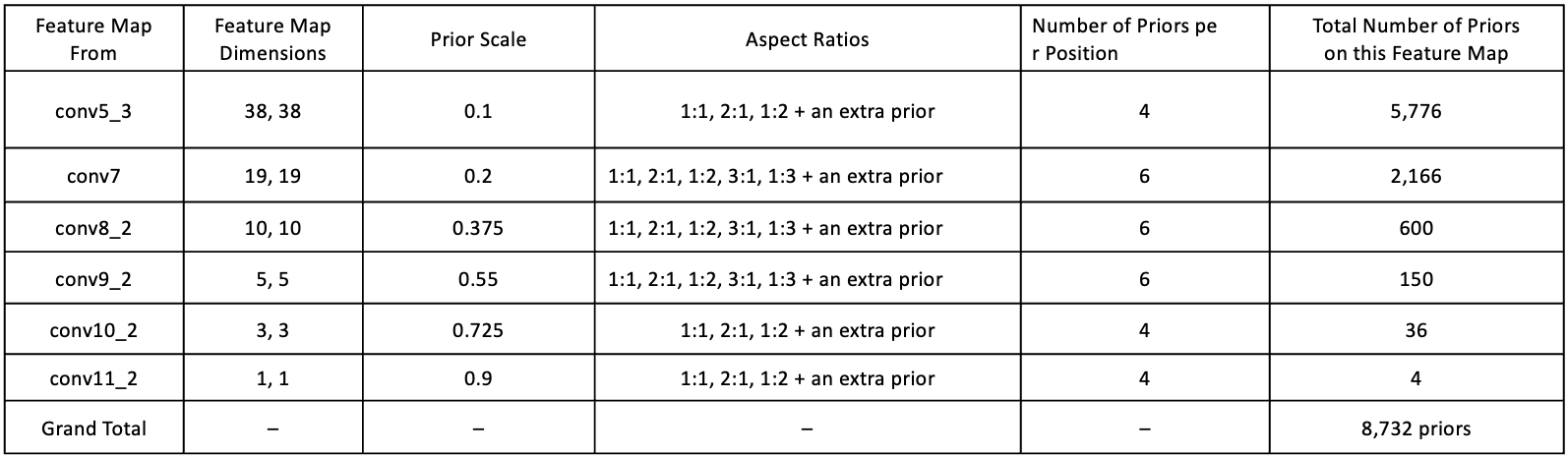
표에서 나오듯, 입력으로 들어오는 이미지의 셀마다 두는 prior의 개수를 conv층마다 다르게 둔 것을 볼 수 있다. 개수 뿐만이 아니라 셀에 대한 prior끼리도 scale( 0.1, 0.2, ... )과 종횡비( 1:1, 1:2, 2:1, ... )을 다르게 한 것은, 작은 bounding box의 예측( 찾아가는 과정 )을 더 잘 하며, 더 다양한 영역에서 Bounding box를 포착하도록 한다. 그래서 아까 예시에서 conv9_2의 prior 수가 6개였던 이유도, 상자별로 크기와 좌우비율이 모두 다른 이유도 이 때문이다.
conv5_3에서 모든 prior의 개수를 고려했을 때, 4개의 prior가 38x38 각 셀마다 적용이 되므로 38x38x4 = 5,776개가 된다. 이런 방식으로 모든 conv층의 prior개수를 세어 보니 총 8,732개의 prior가 나오게 된 것이다.
YOLO가 98개의 anchor box를 통해 객체 탐지를 하는 것을 고려하면, 월등히 많은 수의 prior로 탐지를 하여 성능 향상을 이뤄낼 수 있었다.
Bounding Box : 경계 상자
- a.k.a BBox ( =Gound Truth )
말 그대로 이미지 내 객체를 표시한 상자이다. anchor box는 이 BBox를 기준으로 삼아 회귀 과정을 통해 이미지 내 객체를 찾아나간다.이 과정을 bounding box를 예측(predicting)한다고도 한다.
따라서 객체 탐지를 위해서는 먼저 이러한 BBox가 만들어져야 한다. 때문에 이러한 객체의 BBox를 ground truth(기준값)라고도 한다.
Mulibox
anchor box내 객체의 bounding box를 찾아가는(predicting) 과정이며 회귀와 분류의 과정을 거친다.
- 회귀 : 좌표 변환
prior에서 객체 검출은 BBox의 좌표를 기준으로 이루어진다.
이 BBox좌표는 두 형태로 표현된다.
- 픽셀 좌표 ( Xmin, Ymin, Xmax, Ymax)
- center-size 좌표 ( Cx, Cy, W, H)
먼저는 BBox의 좌표를 픽셀 좌표로 표현한다.
픽 셀좌표는 좌표값을 이미지 픽셀 수로 나타낸 좌표로서, 아래와 같이 971x547 이미지 내 객체에 대한 BBox를 좌상단과 우하단의 ( x,y ) 좌표로 픽셀좌표를 통해 나타낸 것을 볼 수 있다.
하지만 이보다 효율적이면서도 명확한 형식의 좌표 표현으로 변환을 해주어야한다. 해서 아래와 같은 과정을 거친다.
-
픽셀좌표 정규화
이미지 크기가 제 각각임을 고려하면 픽셀 좌표로 표현 시, 서로 다른 이미지 내 객체들 사이에서 명확한 표현이 되지 않을 수 있다. 따라서 이미지 내 객체 위치를 좀 더 명확한 좌표 형태로 나타내기 위해 상대적 위치로 표현할 수 있으며, 0~1 사이의 정규화된 좌표값으로 적용할 수 있다. -
center size
또한 위와 같은 방법으로는 이미지 전체의 실제 치수를 알 수 없다.
이미지 내 객체의 왜곡 을 방지하려면 객체의 종횡비(너비와 높이)를 유지해야 한다. 해서 좀 더 안정적인 정보 전달을 위해 아래와 같은 형태로 변환하게 된다

이렇게 BBox를 위 그림처럼 상대좌표로 변환한 후 prior와 BBox사이의 IOU값을 계산한다.
- 회귀 : offset 업데이트
이후 각 prior의 offset정보를 업데이트한다. 이는 ground truth 대비 prior의 좌표를 나타낸다.
다시말해, prior가 객체의 진짜 위치쪽으로 얼만큼 이동해야 하는지 나타낸다.  convolution층을 거듭할 때마다 이러한 offset정보들이 출력값으로 나오게된다.
convolution층을 거듭할 때마다 이러한 offset정보들이 출력값으로 나오게된다.
상세한 내용은 prediction convolution층을 볼 때 다시 살펴보자!
- 분류
감지된 객체에 대한 종류(object type)을 분류하는 과정을 거친다. 이는 class별로 confidence score를 적용시킨다.
만약 21개의 class가 존재한다고 하면, 21개 class에 대한 confidence score 중 제일 높은 값을 골라 분류하게 된다.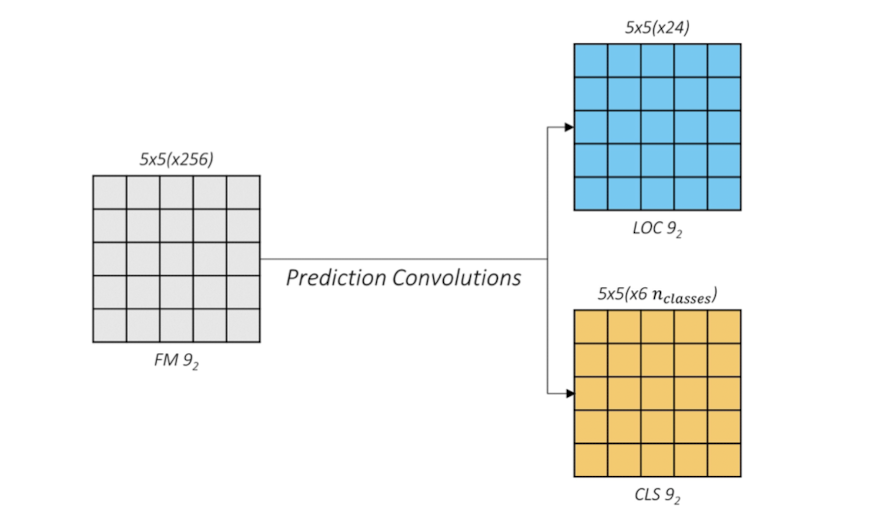
위의 그림에서 location정보와 class 분류를 어떻게 진행하는지 살펴보자.
conv9_2층의 prior 수는 6개이므로, 각각의 prior에 대한 4개의 offset을 직렬화하여 나타내어 24개의 열로 표현하였다.
마찬가지로 class 분류시에도 6개의 prior에 대해 모든 클래스 별로 confidence score를 매겨 표기하였다. SSD에서 기본적으로 두는 class수는 21개임을 고려하여 보면 되겠다.
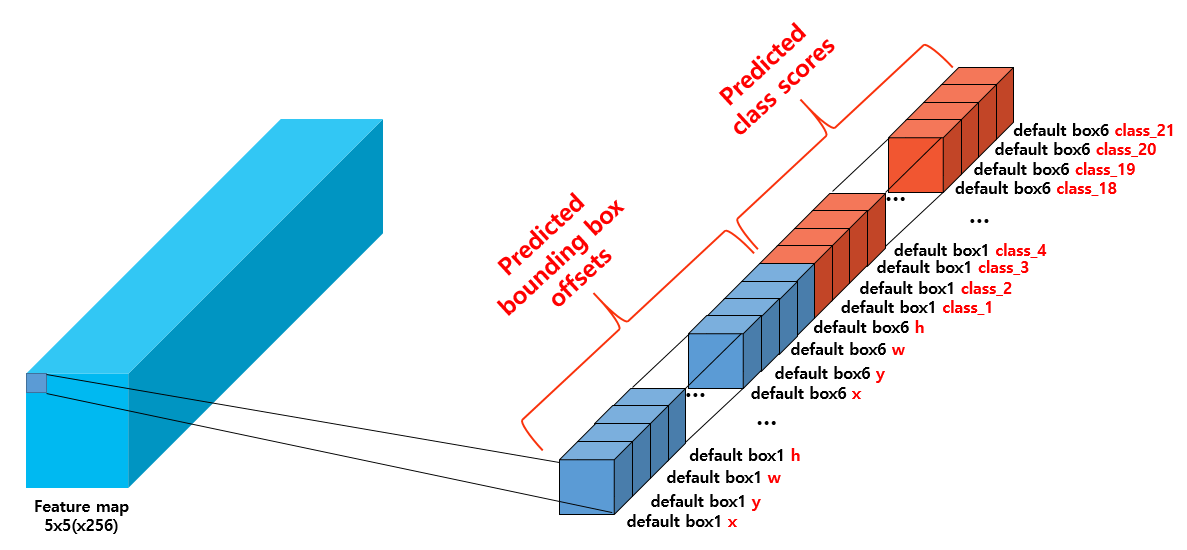
다시말해, 그림과 같은 5x5(x24) 와 5x5(x(6x21))의 표현은 한 픽셀에 대한 6개의 prior의 offset과 class confidence score를 직렬화하여 표현한 것이다.
이렇게 직렬화한 벡터를 ( 1, feature map 픽셀 수 x prior 수 , ( offset + class 개수 )) 로 reshape하여 최종 출력을 하게된다.
conv9_2층의 경우 5x5의 feature맵과 6개의 prior로 구성되므로 출력 텐서는 ( 1, 150, 25)이다.
이러한 과정을 거치고 나니, 위에서 언급된 25라는 숫자도 한 prior에 대한 offset(4)과 class의 confidence score들(21)로 나오게 된 것을 알 수 있게된다.
이 내용도 predicton convolution층에 대해 살펴볼 때 다시 다루도록 하겟다.
IOU( = Jaccard Index )
IOU란 Intersection-Over-Union의 줄임말로, anchor box와 BBox 두 영역에 대한 교집합 영역을 합집합의 영역으로 나눠준 값을 말한다.
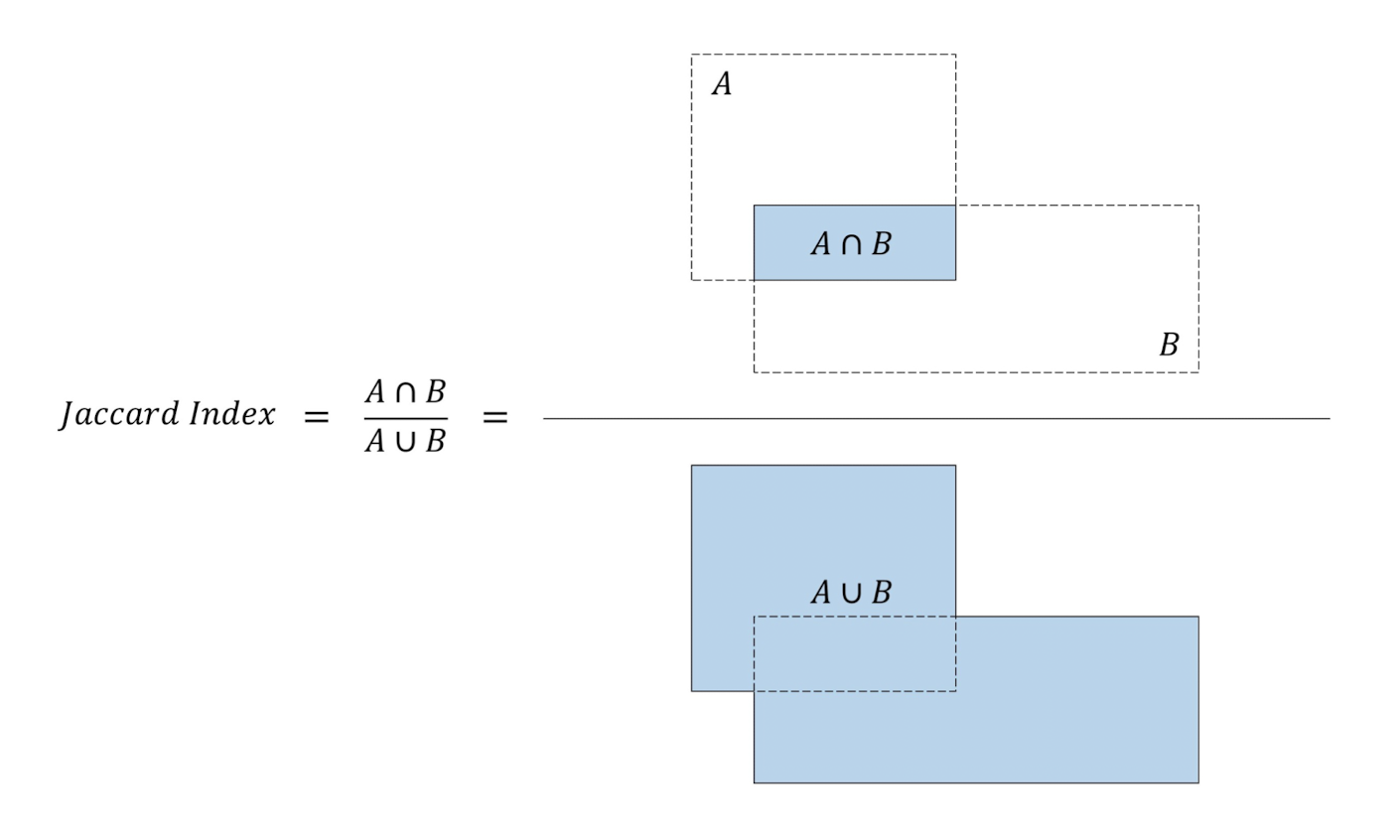 이 값은 0~1 사이의 값을 가지는데, 1이면 두 박스가 같은 영역을 가지고 있으며 0이면 서로 다른 영역을 포함하고 있음을 나타내게 된다.
이 값은 0~1 사이의 값을 가지는데, 1이면 두 박스가 같은 영역을 가지고 있으며 0이면 서로 다른 영역을 포함하고 있음을 나타내게 된다.
IOU를 통해 특정값(ex. =0.5)을 기준으로 각 anchor box가 positive matching인지 negative matching인지 판단할 수 있게된다.
positive matching으로 간주할 땐 IOU가 특정값 이상이며, anchor box내에 객체가 존재한다고 판단할 수 있게된다.
negative matching일 때는 IOU가 특정값 이하일 때이며, anchor box가 객체 존재하지 않는다고 판단한다.
이는 anchor box에 label을 부여할 때 사용하며, matching 유형에 맞게 class가 분류된다.
적용 예시
 이미지 내 3개의 객체에 대한 Ground Truth(GT = Bounding Box)와 7개의 anchor box( =Prior)가 존재하고 있다.
이미지 내 3개의 객체에 대한 Ground Truth(GT = Bounding Box)와 7개의 anchor box( =Prior)가 존재하고 있다.
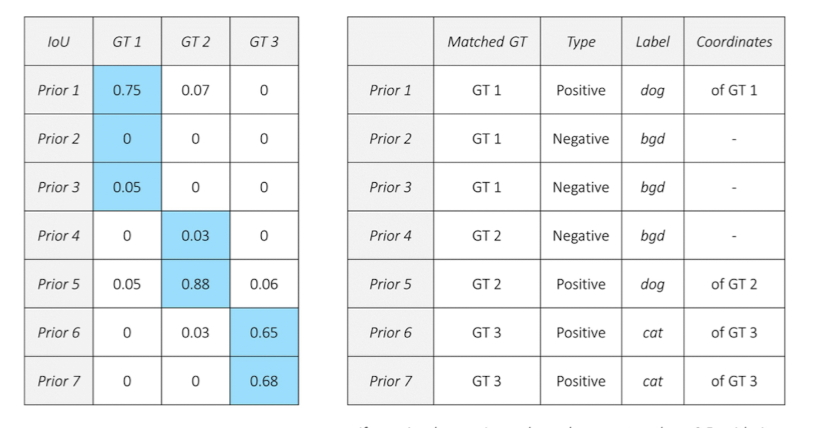 좌측 표를 참고하면, 각 prior에 대해 객체 별로 IOU값이 나타나있다. 이때 prior들은 각자의 IOU 값들 중 가장 높은 값을 선택한다. 그 결과로 prior별 매칭된 Ground Truth 결과를 볼 수 있다.
좌측 표를 참고하면, 각 prior에 대해 객체 별로 IOU값이 나타나있다. 이때 prior들은 각자의 IOU 값들 중 가장 높은 값을 선택한다. 그 결과로 prior별 매칭된 Ground Truth 결과를 볼 수 있다.
positive matching된 anchor box는 매칭되었던 Ground Truth의 class를 label로 삼고,
negative matching땐 매칭된 ground truth가 없으므로 bgd( 배경 )을 label로 삼는다. 이를 통해 보면 bgd도 객체의 class에 속한다는 것을 알 수 있다.
이는 multibox loss를 계산할 때 수행하는 과정이며 해당 내용을 살펴볼 때 다시 언급하겟다.
마무리
이번 포스팅은 객체 탐지에서 SSD알고리즘의 전체 구조를 대략적으로 알아보기위해 관련 용어들을 통해 전체적인 구조를 훑어보았다.
다음 포스팅에서 SSD의 conv층의 구체적인 기능들과 loss function적용 방식에 대해 다시한번 살펴보도록 하겠다
