지난 포스팅을 통해 SSD의 전체 구조를 용어들 위주로 살펴보았다면, 이번엔 SSD의 상세한 conv층 구조와 학습방식에 대해 알아보도록 하겟다.
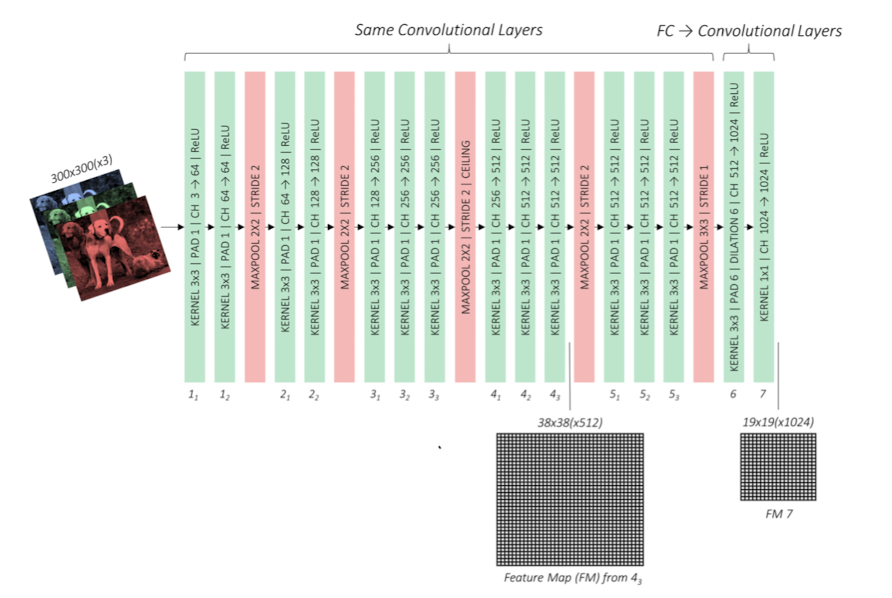
Convolution architecture
SSD는 크게 3가지의 conv층으로 구성이 된다.
- Base convolution 기존의 VGG-16을 사용하였고, 기존 모델의 FC(fully connected)층을 다시 convolution층으로 대체하였다.
- Auxiliary convolution base conv층 이후 추가된 conv층으로, 추가적인 feature map을 얻어낸다.
- Prediction convolution 객체의 위치를 예측하고 class(object type)을 식별한다.
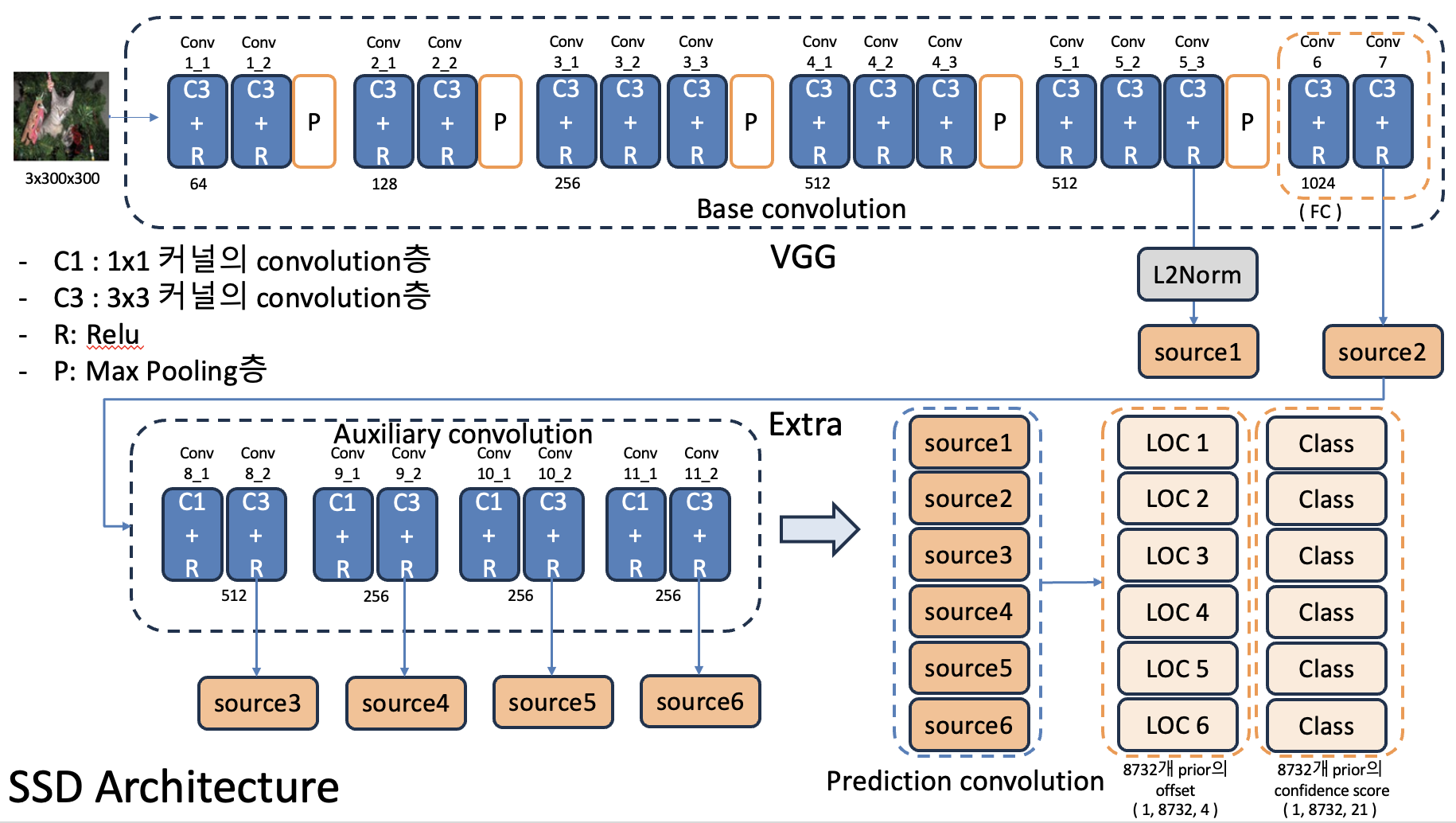 (위 그림은 숭실대학교 한영준 교수님의 강의자료를 참고하여 만들었습니다.)
(위 그림은 숭실대학교 한영준 교수님의 강의자료를 참고하여 만들었습니다.)
Base
SSD는 기존의 VGG-16모델을 사용해서 특징추출을 수행한다. 아래 그림이 기존의 VGG-16모델이 된다.
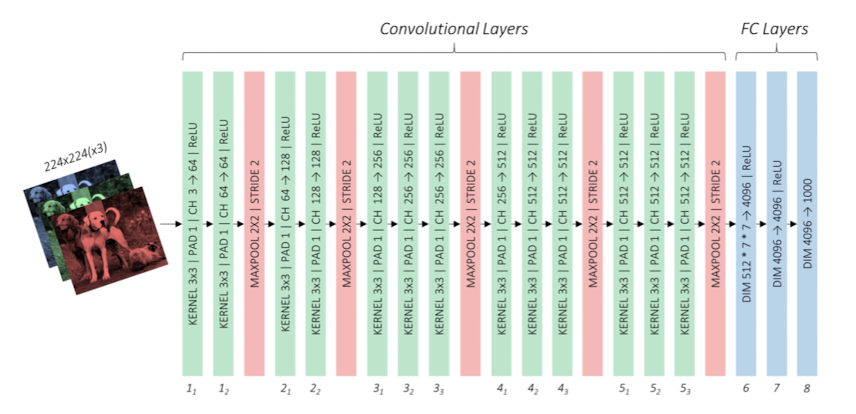
이 모델이 SSD에서 적용될 때는 아래의 내용이 바뀌게 된다.
- input size 300x300크기의 이미지를 입력으로 넣는다.
- pooling conv5층을 거친 후 적용되는 pooling층을 2x2(stride : 2)에서 3x3(stride : 1)로 바꿔주므로 해당 conv층의 입력과 출력 크기를 같게 유지할 수 있도록 바꾸었다.
- FC층 기존의 Fully Connected층을 conv층으로 바꿨다. 바꾼 결과가 conv6, conv7층이 된 것이다.
300x300크기의 입력 이미지가 Base network를 지나면, 4번의 pooling(2x2, stride: 2)과정을 거치므로 38x38크기로 바뀌게 된다.
( 이때의 37x37이 아닌 38x38인 것은 홀수 사용으로 인한 불편함을 배제하기 위함이라고 한다.)
바뀐 마지막 pooling층으로 인해 38x38크기의 feature map이 FC층의 입력으로 들어간다.
SSD에선 이를 conv층으로 바꿔주므로 conv6층으로 들어가는 것이 되겠다.
FC층을 어떻게 conv층으로 바꿀 수 있었을까?
저자는 두 시나리오를 제시한다. 먼저 FC층에서의 연산과정을 살펴보자.
-
FC층의 연산
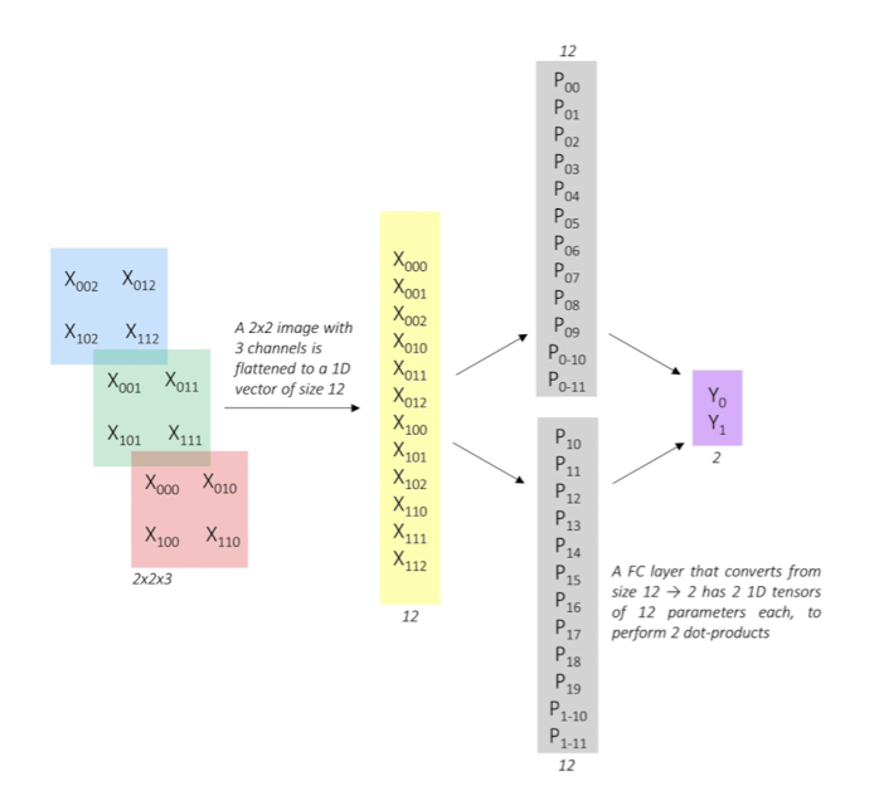
예시 사진에서 입력 이미지에 대해 1차원 벡터로 변환된 후 FC층에서 연산이 이루어지는 과정이다. 입력벡터 ( X000, ..., X112 ), 가중치 ( P0_0, P0_1, ... P0_11 ), ( P1_0, P1_1, ..., P1_11 )에 대하여 Y0과 Y1은 아래와 같이 연산이 이뤄진다.Y0 = X000*P0_0 + X001*P0_1 + ... + X112*P0_11
Y1 = X000*P1_0 + X001*P1_1 + ... + X112*P1_11 -
convolution방식 적용
이러한 연산을 convolution방식으로 수행한 것이 아래와 같다.
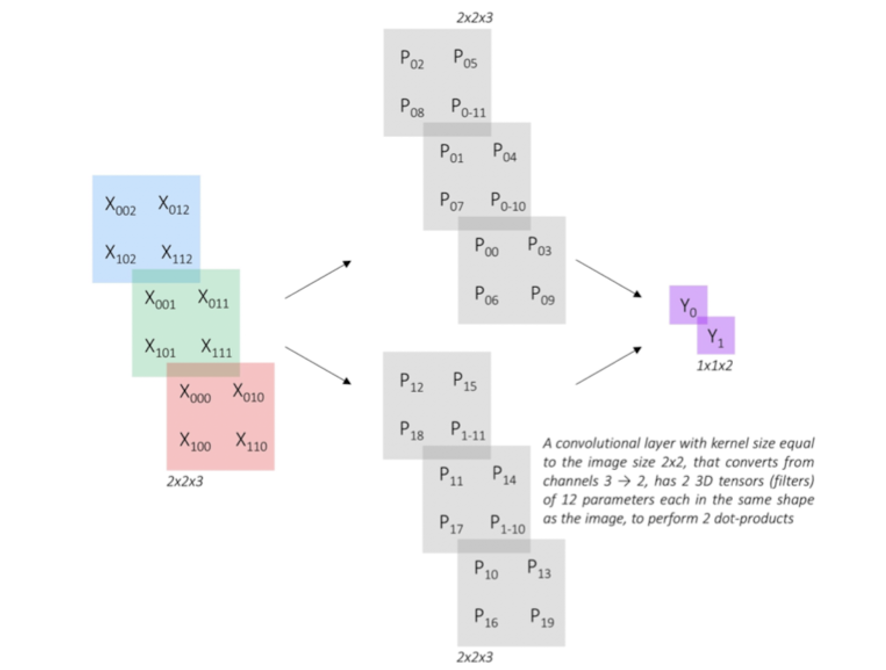
즉, 입력에 대한 직렬화를 시키지 않고, filter를 적용하여 FC층을 거칠 때와 동일한 연산을 취하도록 한 것이다. 위 그림처럼 filter를 적용시킨다면 Y0, Y1이 아까와 동일한 결과값을 가지는 것을 알 수 있을 것이다.
이를 토대로 기존의 FC층을 conv층으로 바꾸어 conv6, conv7층으로 대체하였다.
Auxiliary
바꾼 VGG모델 이후에 추가적인 conv층을 말한다.
conv7층에서의 출력값을 추가 conv층의 입력으로 넣는다.
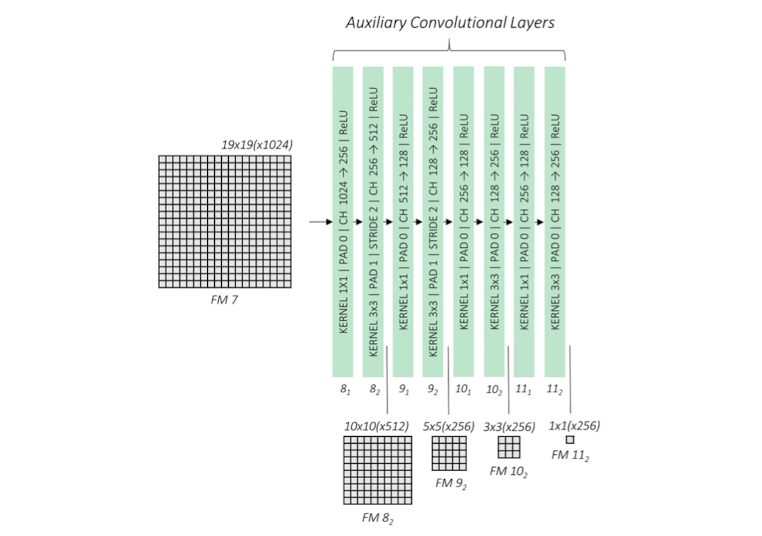
여기까지 봤을 때 총 6곳에서 feature map이 나오게 된다. conv4_3, conv 7, conv 8_2, conv 9_2, conv 10_2, conv11_2 에서 나오는 feature map은 최종 출력과 직결되는 피쳐맵임을 기억해야한다.
base에서 pooling을 통해 feature map크기를 줄였던 것과는 다르게 여기서는 각 층의 두번째 conv연산때 크기를 반으로 줄인다.
이와 같이 여러 feature map을 출력하도록 하는 것은 객체의 위치를 예측(predicting)하기 위함이다.
그렇다면 예측의 역할은 누가 수행할까? 바로 prior이다.
이미지 내 위치한 객체(Ground Truth)를 찾아낼 때, 각 셀별로 prior 개수를 지정하여 찾아내는 방법을 사용하고 있다.(bounding box-free한 방법은 아니다)
층별로 적용되는 prior의 개수와 크기, 종횡비가 모두 제각각인데 아래의 표를 참고하는게 좋을 듯 하다.
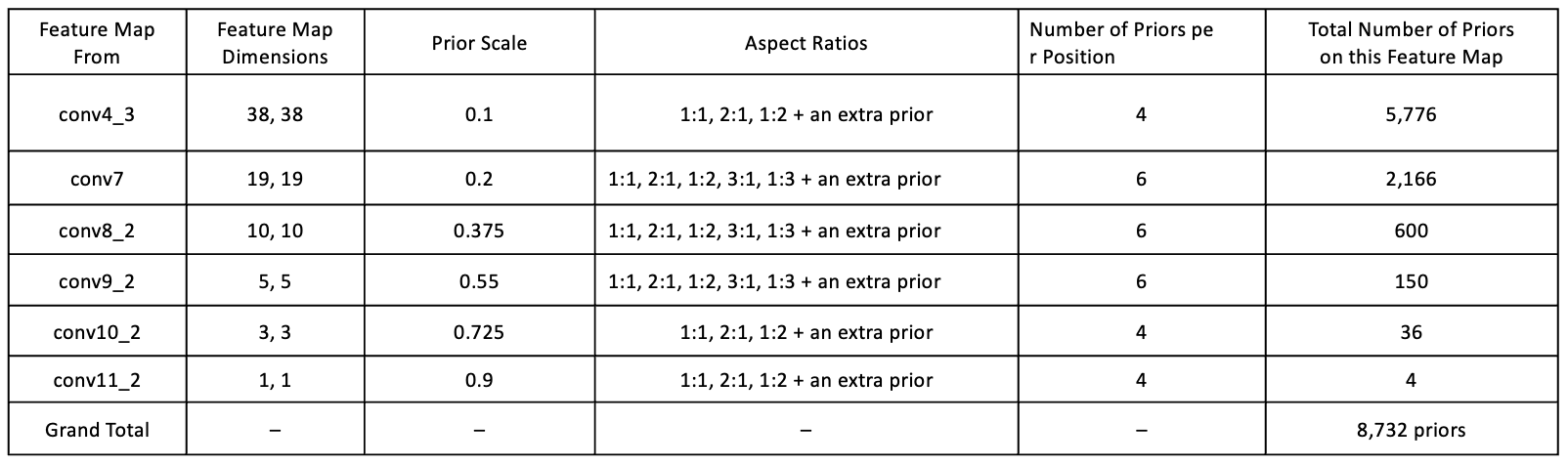
표에 따르면, conv4_3층에선 38x38 feature map에 대해 1/10크기(0.1 scale)의 prior를 하나 두고, 이를 기준으로 1:1, 2:1, 1:2 ... 의 다른 종횡비를 적용하여 총 4개의 prior를 가지도록 정해놓은 것을 볼 수 있다.
conv4_3층 이후 conv층의 scale은 0.2~0.9 사알로 설정된 모습이다. 이렇게 다양한 scale로 적용한 것은, 작은 객체부터 큰 객체까지 탐지할 수 있는 범위를 늘리고자 함이라고 한다.
이때 종횡비 칸의 'an extra prior'는 현재 층의 scale과 다음층의 scale의 평균값으로 결정이 되어 scale책정이 되며, 1:1 종횡비로 적용이 된다고한다.
이러한 prior들의 scale과 종횡비와 개수는 고정되어있으며, 각 conv층에서 사용하는 prior의 개수를 합산하면 SSD에서 사용하는 prior( anchor box )개수는 총 8732개가 된다.
prior는 feature map의 셀별로 적용이 된다.
아래 예시는 conv9_2층에서 priors
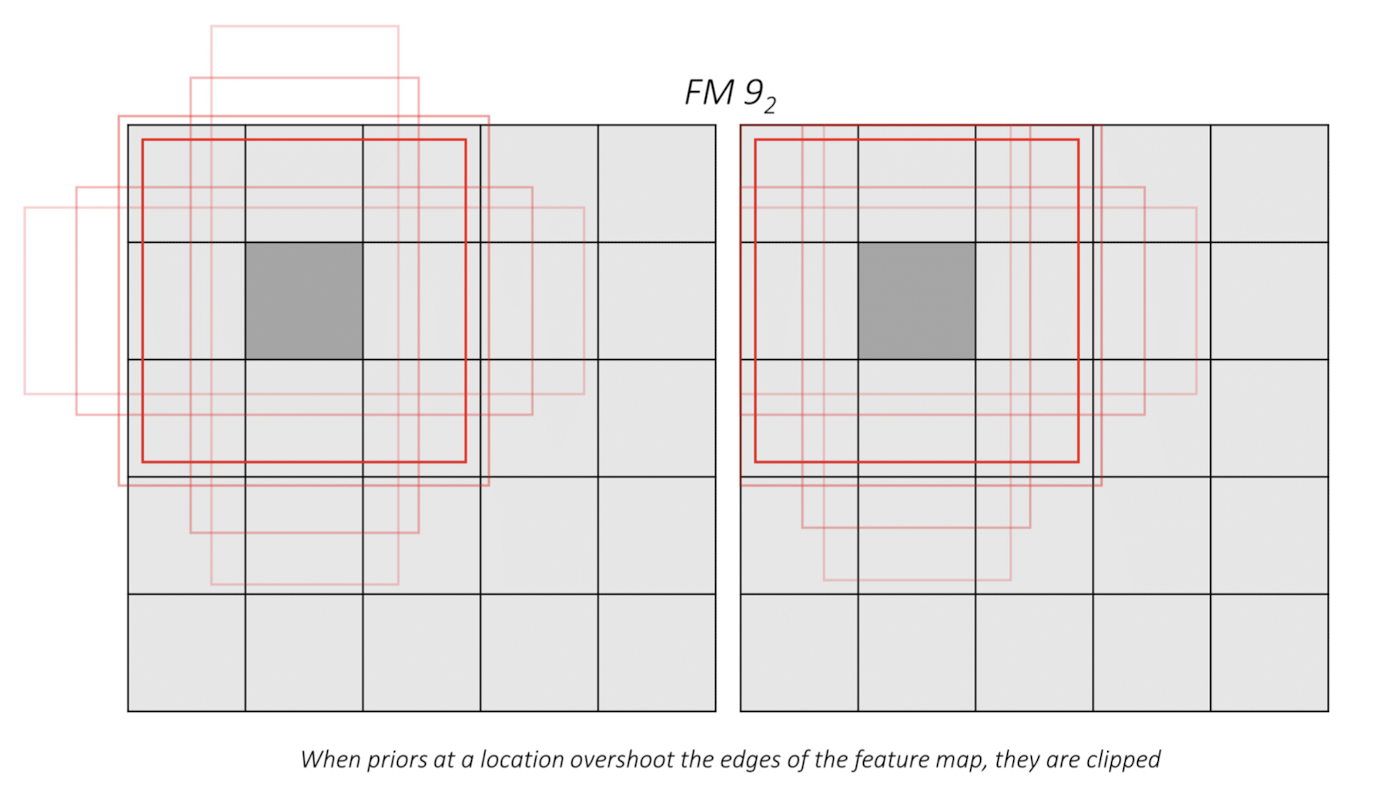
그렇게되면 위 그림처럼 가장자리 셀들에 대해선 prior가 feature map경계를 넘어가게 되는 경우도 발생하는데, 이때는 clipping을 적용한다.
이 prior로 최대한 객체의 bounding box( Ground Truth )와 가깝게 표현하는 것이다. 즉, prior의 크기와 위치값을 bounding box의 크기와 위치로 근사화하기 위한 작업이 시행된다.
이때 근사화를 위한 prior의 offset개념을 사용한다.
- offset priorr가 ground truth쪽을 얼마나 이동해야 하는지를 나타낸다. 이는 둘다 center size 좌표들 사이에서 값을 연산하여 (Gcx, Gcy, Gw, Gh)형태의 좌표를 얻어낸다.

위 그림을 참고하면 offset의 각 좌표값은 모두 prior의 종횡비로 정규화 된 모습을 볼 수 있다. 이를 통해 prior가 bounding box쪽으로 얼마나 이동해야 하는지 알 수 있으며, 객체 탐지 시 더 정확한 객체 위치쪽으로 탐지하도록 한다.
결국 SSD모델은 이러한 offset을 얼마나 잘 예측하냐가 관건이기도 하다.
Prediction
conv4_3 , conv7 , conv8_2 , conv9_2 , conv10_2 , conv11_2 층에서 출력된 피쳐맵을 얻어낸 것은, 이미지 내 객체의 위치를 파악하고 class를 분류하기 위함이었다. 여기서는 명칭 그대로 이미지 내 객체의 위치(Loc)와 객체 type(class)를 예측하는 과정을 거친다. 즉, 각각의 feature map에서 셀별로 예측한 offset과 21개의 class 확률값들을 출력하게 된다. 아래의 예시를 살펴보자
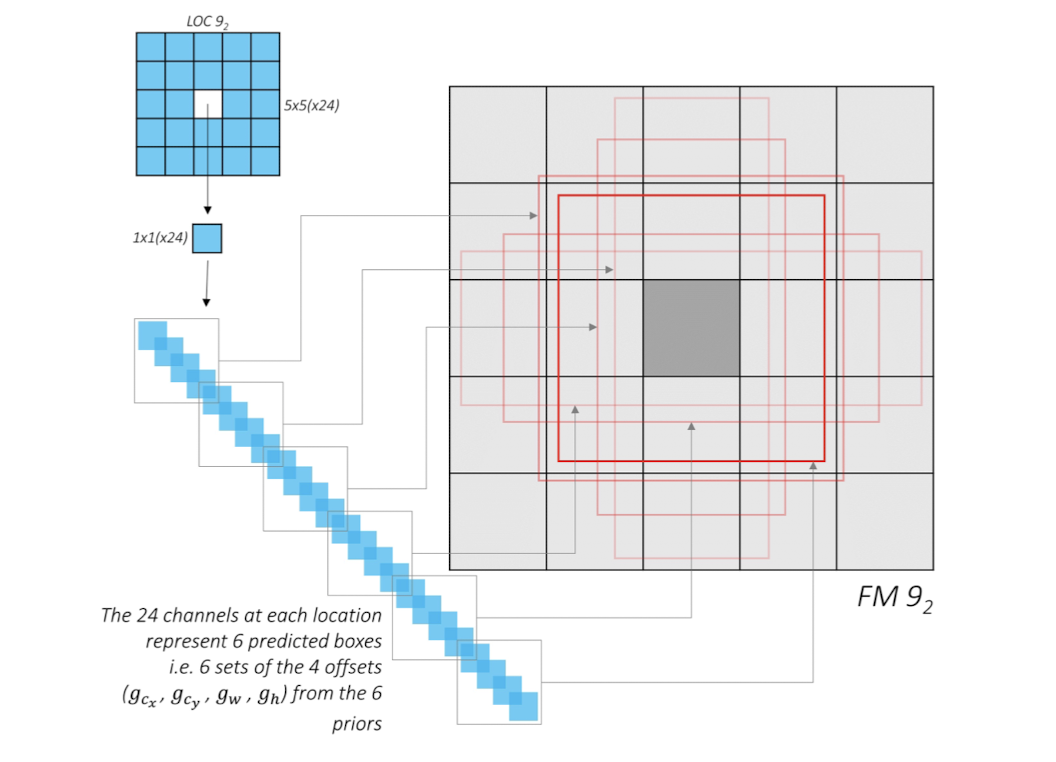
conv9_2층의 경우 5x5 feature map에 셀당 6개의 prior가 적용이 된다. 그림에선 가운데 셀에 대해, 6개 prior에 대한 각각의 offset을 예측하여 총 24개의 채널이 나옴을 설명하고있다. 이는 Location에 대한 정보, 즉 offset을 예측하기 위한 연산이며 prediction convolution층에서는 이와 같은 연산을 통해 offset과 class를 예측하는 과정을 먼저 수행한다.
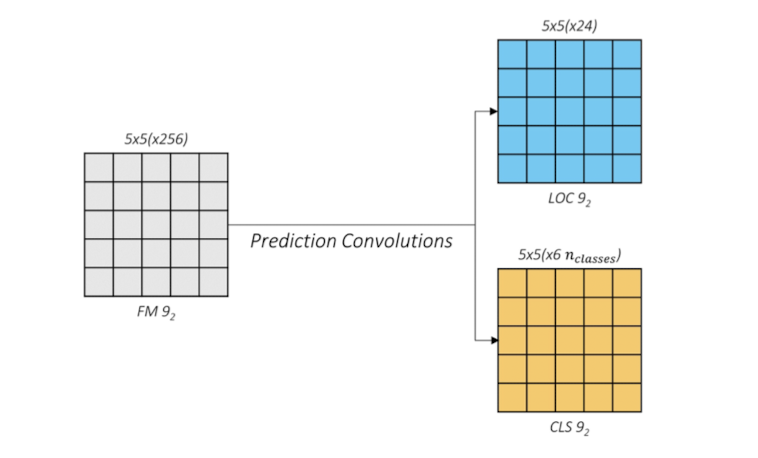
offset을 예측할 때와 마찬가지로 class score( 확률값 )을 예측할 때도 셀 단위로 진행을 한다. 즉, 위의 그림의 내용은 셀별로 각 prior들의 offset과 class 예측값들을 직렬화하여 나타낸 것임을 알 수 있다.
아래 그림 첫번째 셀처럼 말이다.
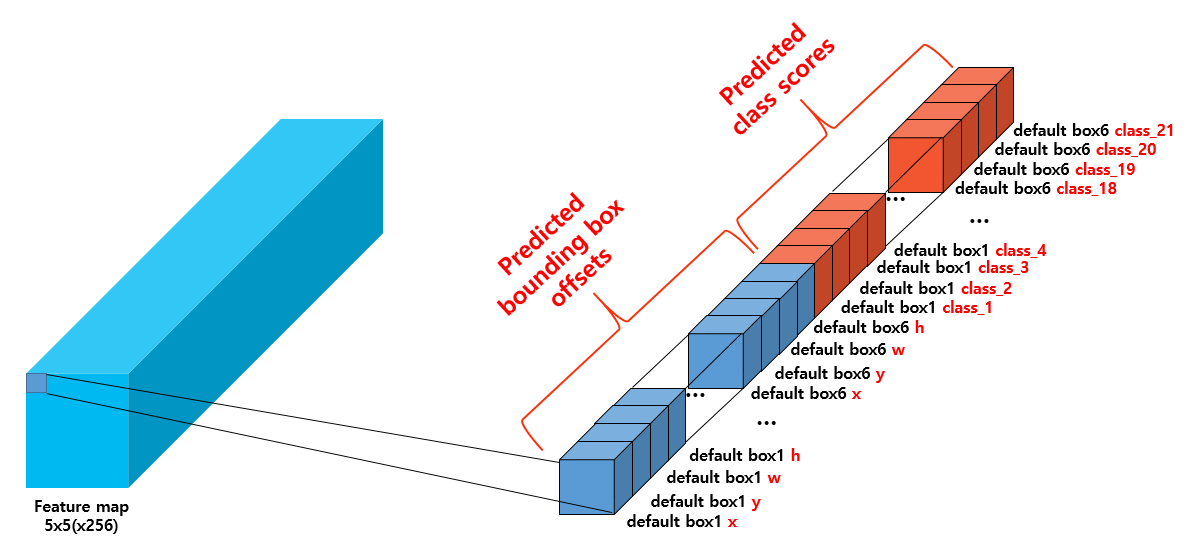
직렬화된 텐서는 각 prior( =default box )의 offset값들로 나열된 후, 각 prior들의 class score ( 객체가 어떤 class에 속하는지에 대한 확률값 )들이 나열된다. 기본적인 SSD기준 class가 21개이므로, prior별로 21개 class에 대한 각각의 score값이 존재한다.
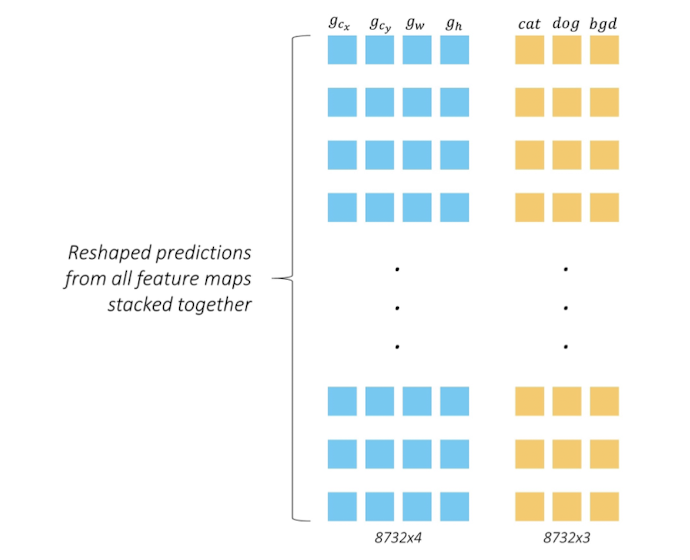
그 결과 5x5x150( 6x4(offset) + 6x21(class score) ) 의 텐서가 얻어질 것이다. 이제 이 텐서를 아래 그림과 같은 형태로 1x150x25의 형태로 reshape한다.
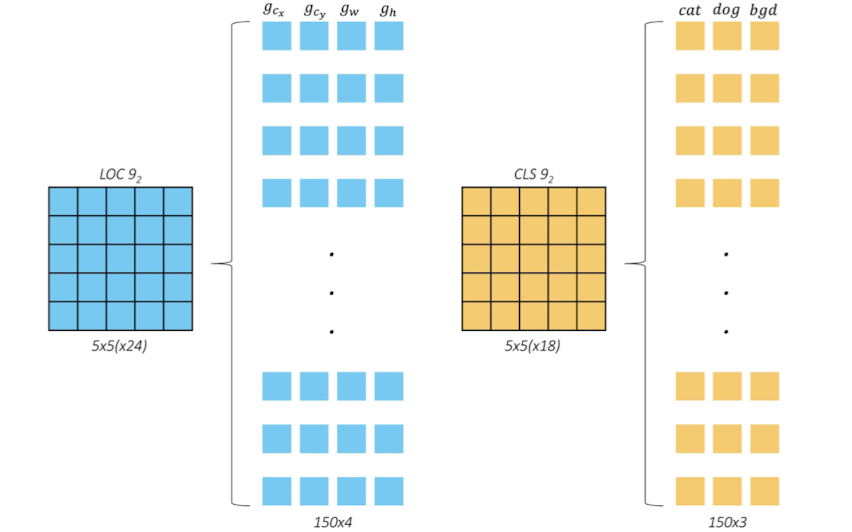 (그림에서는 예시 차원에서 3개의 클래스만 고려하여 나와있다.)
(그림에서는 예시 차원에서 3개의 클래스만 고려하여 나와있다.)
지금껏의 예시는 conv9_2층에 대해서였는데, 이 층에서 prior개수는 총 몇개였을까? 150 ( 5x5x6 ) 개였다.
즉, reshape된 텐서의 한 행은 하나의 prior의 예측된 offset과 class확률값으로 표현된 것이다.
이처럼 6개의 feature map을 통해 나온 최종출력 1x8732x25 크기의 텐서는 SSD내 모~든 prior별 예측된 offset과 class확률값이며, 이것이 최종 출력값의 의미이다.
이제, 이 예측값들을 토대로 학습을 하게 된다.
𝓛 : Multibox loss
두가지 loss값을 구하는데, Location에 대한 loss( 𝓛loc )와 Class에 대한 loss( 𝓛conf )를 구하여 이 둘을 합해 total loss를 구한다.
이 과정에서는 아래의 요건을 관건으로 하여 진행한다.
- 어떤 loss함수를 사용할 지
- 두 loss값을 어떤 비율로 합하여 total loss를 구할 것인지
- prediction conv층에서 최종출력으로 뽑아낸 예측값( prediction )과 ground truth를 어떻게 매칭시킬지
matching
loss값을 계산 하기 전, prediction의 offset값이 어느 ground truth에 해당하는지 알아야 한다.
이는 IOU( = Jaccard overlaps )값으로 결정하며, 특정값( ex. 0.5)을 정하여 판단한다.
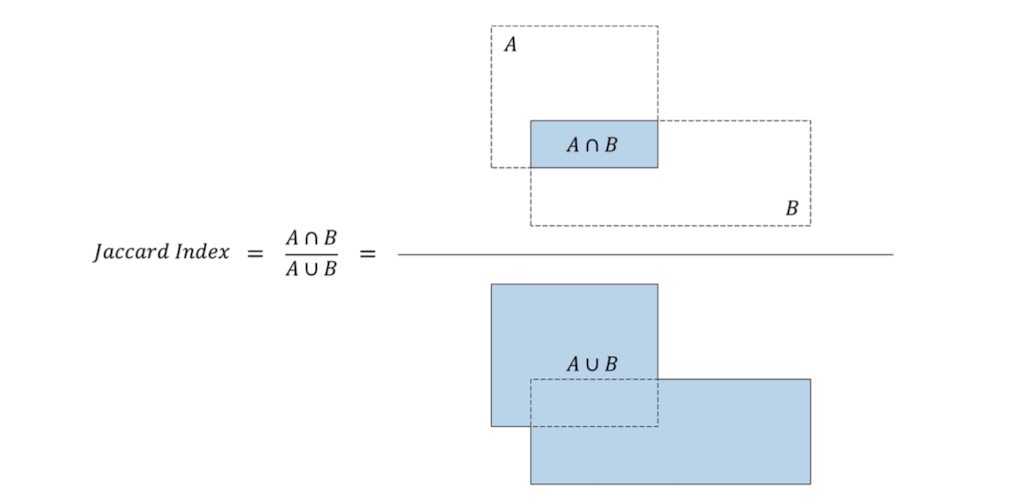
이 척도는 bounding box와 prior 사이에서 위 그림처럼 연산을 하여 값을 추출한다. 이 값이 1에 가까울수록 서로 겹치는 영역이 많아진다는 것을 알 수 있다.
기본적인 모델에서는 IOU값이 0.5 ( 특정값을 0.5로 설정 ) 이상인 값들은 prior내 객체가 있다고 판정하여 positive matching,
0.5이하의 값들은 prior내 객체가 없다고 판정하여 negative matching을 하게 된다.
- 예시

그림처럼 7개의 prior와 3개의 ground truth(GT)가 존재할 때, 매칭 결과는 아래처럼 진행될 것이다.
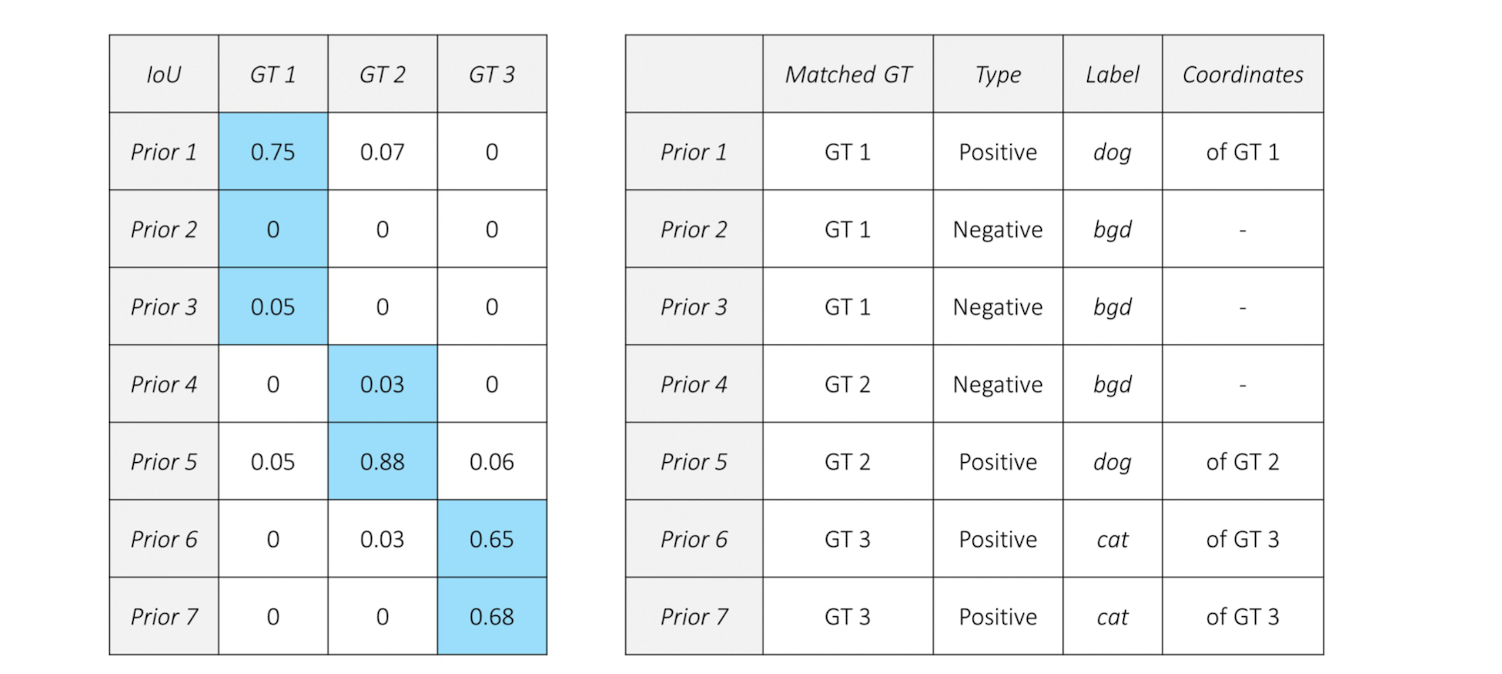
먼저, prior마다 모든 GT와의 matching을 진행한다. 각 prior들은 가장 큰 IOU값을 가지는 GT와 matching되게 된다.
이후, matcing된 GT에 대해 positive인지 negative인지 결정할 수 있게된다.
positive인 prior는 해당 GT의 label로 할당을 받으며, negative인 prior는 객체가 존재하지 않음으로 '배경'(bgd) label로 할당을 받는다.
이 때 배경(bgd) 또한 class의 일부임을 알 수 있다.
이 예시에서 주목할 것은 positive matching된 prior가 얻은 gound truth 좌표와 matching시 얻게 된 label 정보이다.
- label의 정보를 target값으로 삼아 prediction conv층에서 나온 class score과 비교하여 나온 loss값을 통해 분류 작업을 수행한다.
- ground truth 좌표를 target으로 하여 prediction에서 추정된 offset과의 loss( Location )값을 구할 수 있게 된다. 즉, 회귀 작업을 수행한다.
Location Loss
positive matching된 prior들만 groud truth 좌표를 할당받았다.
다시 말해, positive matching된 prior들과 ground truth 사이에서 loss값을 구하는 것이다.
prediction conv층에서 예측한 offset ( Gcx, Gcy Gw, Gh )의 형태에 맞게 ground truth 좌표도 바꿔준다.
아래 수식처럼 평균 smooth L1 loss를 적용하여 계산한다.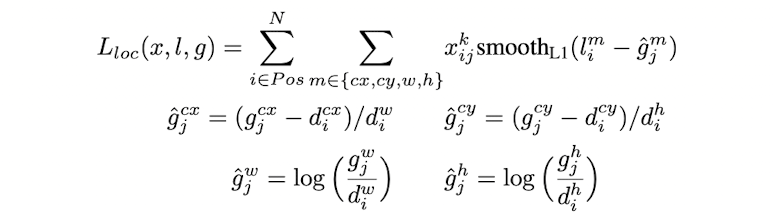
- 𝑙 : predicted box parameters
- ɡ : ground truth box parameters
ground truth와 predicted offset 사이에서 ĝ을 구한다. 이 과정에서 scale이 prediction에서의 offset과 같아질 것이다.
이후, 𝑙 ( predicted )와 ĝ( target )사이의 smooth L1 loss를 적용시킨다. smooth L1 loss는 아래와 같다
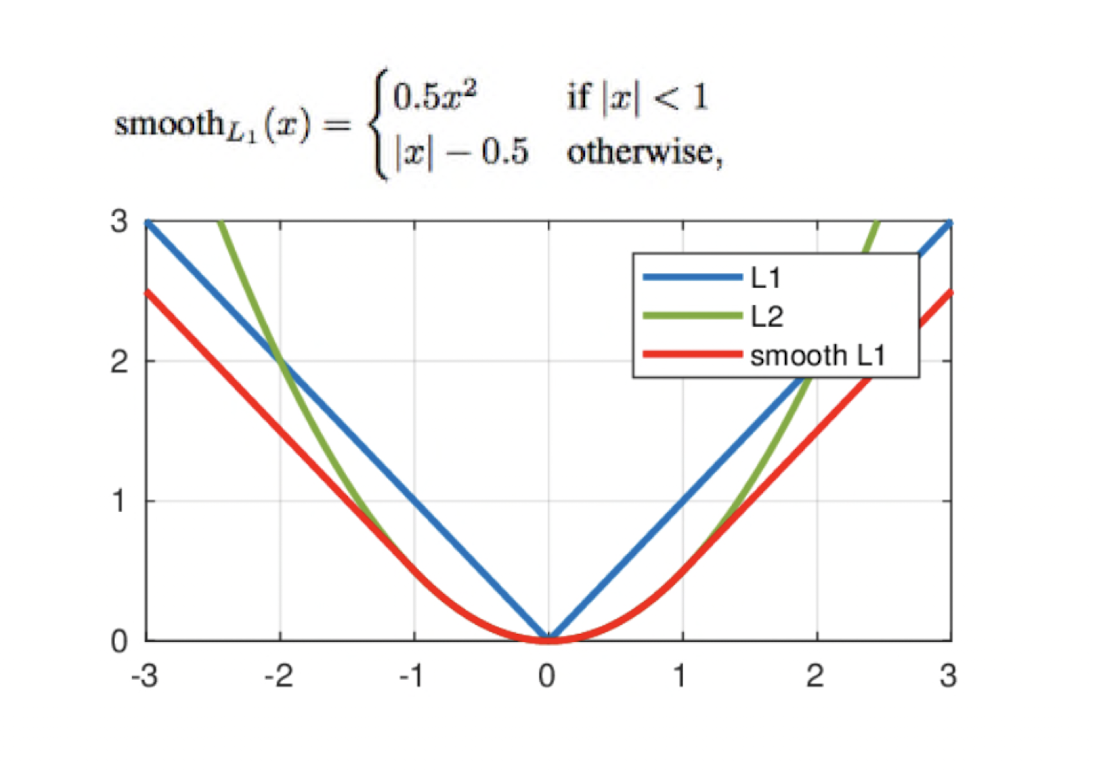 예를 들면,실제 값이 10이고 예측이 8이라고 하자.
예를 들면,실제 값이 10이고 예측이 8이라고 하자.
x ( error 값 ) = | 8 - 10 | = 2 이고, x가 1보다 크므로,
loss값은 smooth L1 loss = |2| - 0.5 = 1.5 이다.
smooth L1 loss는 이처럼 에러값이 특정 범위 이내( -1 <= x <= 1 )에서는 거의 맞는 것으로 취급을 하며, 큰 gradient값을 부여하여 빠르게 loss값이 감소하는 것을 볼 수 있다.
Confidence Loss
전에도 언급했듯, 이 때는 positive나 negative 여부와 관계없이 모든 prior에 부여된 label과 예측된 class score 사이에서 loss값을 얻어낸다.
prior내에 객체가 없다면, 객체가 없다고도 인식할 수 있어야 한다.( negative -> 배경:bgd 으로 인식해야 함)
하지만 한 이미지에 대해 수천개 ( 8,732개 )의 prior가 존재하는 것에 비해 객체의 수는 몇 개에 불과함을 고려해보자.
negative matching이 대다수일 것이며 positive matching된 prior 수는 극히 드물 것이다. 이러한 불균형 문제로 인해 false positive ( 객체가 없는데 객체로 인지한 경우 )가 다수 발생하게 되는데, 이는 모델의 성능에 꽤나 큰 악영향을 미친다.
따라서 모델이 이와 같이 배경을 객체로 학습 및 인지하는 과정을 보완하고자 hard negative mining 과정을 진행한다.
👉 hard negative mining
hard negative는 실제론 negative인데 positive라고 잘못 예측한 것이다. 즉, 객체가 존재하지 않는데 존재한다고 예측한 것을 말한다.
이처럼 negative라고 예측하기 어려운 데이터들을 모아 학습에 포함시키는 것을 hard negative mining이라고 하는 것이다. 모델은 이를 통해 false positive 오류를 보완할 수 있게된다.
- 예시 : 사람 얼굴 탐지
적용 전
초록색 실선 - ground truth, 초록색 점선 - True positive, 빨간색 실선 : False positive
 배경에서 사람얼굴로 인식한 부분이 많았다. false positive가 다수 발생한 모습.
배경에서 사람얼굴로 인식한 부분이 많았다. false positive가 다수 발생한 모습.
적용 후 : 학습 적용 결과 false positive 수가 현저히 줄어든 모습.

SSD 구현 과정에서 이를 사용하는 데이터의 수를 한 이미지에 대해 positive matching된 수의 3배만큼만을 학습에 사용하였다고 한다. 따라서 여기 loss를 구할 땐 negative matching도 포함이 된다.
모델에서 hard negative는 negative matching중 가장 높은 cross entrophy loss 값을 가지는 예측값을 선택하여 찾아낸다. ( 틀려도 제대로 틀린 것들을 택하는 것! )
mining된 hard negative들을 confidence loss를 구하는 과정에서 아래와 같이 반영하여 학습에 포함시킨다. 모두 cross Entrophy loss를 통해 진행된다.
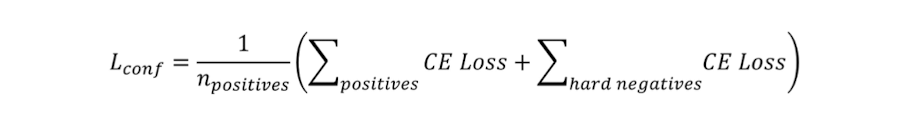
위 식을 다시 표현하면 아래와 같다.
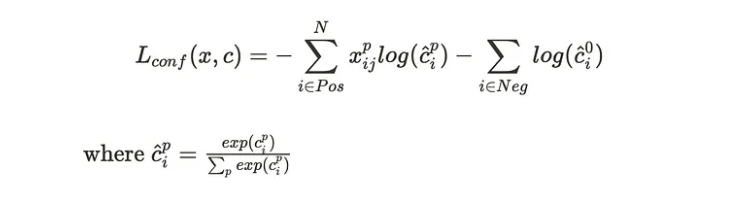
변수 설명
- N : 전체 prior( = default box ) 개수
- 𝒳 𝑖𝒿 ᴾ : i번째 prior와 j라는 ground truth 사이간의 매칭 이후 가지는 IOU값
- č 𝑖 : 객체의 type( class ) p에 대해 softmax함수가 적용된 class score
즉 positive matching과 hard negative에서 모두 softmax함수를 적용한 후 Cross Entrophy가 적용되어 학습이 진행된다.
hard negative에 대해선 객체가 없다고 인식하려면 '배경'으로 인지해야 하므로, 배경 class ( 0 )에 대한 class score를 넣는 것을 볼 수 있다.
Total loss
지금까지 구한 Location Loss와 conf Loss를 합산하여 Total Loss를 구한다. 이 때 특정 비율 𝛼를 곱하여 더한다.
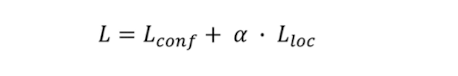
하나의 하이퍼 파라미터로 쓸 수 있으나, 그저 단순 합산을 하려고 저자는 𝛼 = 1로 설정하였다고 한다.
여기까지가 학습 시 loss값을 구하는 매커니즘이다.
NMS
이제 마지막 단계이다!
모델이 prior를 통해 객체를 탐지하고 나면, 한 객체에 대해 여러 predicted box( prior )가 겹쳐있을 수 있겠다. 아래처럼 말이다.
 가운데 개와 고양이를 예시로 참고해보자.
가운데 개와 고양이를 예시로 참고해보자.
사람이 보기 용이하도록 이 중에서 하나의 box를 각각 골라주는 것이다. 이 때 사용되는 것이 비최대억제( Non-Maximum Suppression ) 알고리즘이다.
이는 이름에서도 감을 잡을 수 있듯, 최대값이 아닌 것들은 무시한다는 것이다.
이를 판단하는 기준은 prior들끼리의 IOU값을 체크해 0.5 이상인 것들은 같은 객체를 가리키고 있다고 판단한다.
그리고 이들의 class score를 비교하여 최대값이 아닌 것들은 모두 지운다.
즉, 이 과정에서 객체별로 class score값이 가장 높은 predictd box만을 남겨 결과값으로 내놓게된다.

이러한 모습이 최종적으로 우리가 보게되는 출력값이 되겠다.
후기
여기까지 SSD의 구조를 딥다이브해서 알아보았다.
정리해보면서 느낀 바로는 기존 FC을 conv층으로 대체하면서 연산량이 대폭 줄어 속도 향상을 이뤄냈다는 것, conv층 별 다양한 feature 맵에서 각기 다른 prior 수, 다른 종횡비들을 적용하여 더 작은 객체까지도 탐지하는데 어느 정도 보완을 이루어낸 점을 장점으로 삼을만 하다는 것이다.
하지만 한계로서 뽑을 수 있는 점은 이러한 prior들보다 더 길~쭉하거나 정형화되지 않는 크기의 객체는 탐지하기 어려워 보인다.
기존에 YOLO의 fixed된 anchor box에 비해 다양하고 더 융통성 있는 탐지가 가능해졌으나, 아직까지 특정 'box'에 한정되어 이례적인 객체엔 대처가 어려워 보였다.
출처
- 본문
SSD 논문 : https://arxiv.org/pdf/1512.02325.pdf- 이미지
https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Object-Detection- loss function
https://ichi.pro/ko/modeun-gigye-hagseubjaga-al-aya-hal-5-gaji-hoegwi-sonsil-hamsu-87622716871856- smooth L1 loss
https://ganghee-lee.tistory.com/33
https://www.researchgate.net/figure/Plots-of-the-L1-L2-and-smooth-L1-loss-functions_fig4_321180616- Hard negative mining
https://blog.naver.com/sogangori/221073537958- confidence loss
https://towardsdatascience.com/implementing-single-shot-detector-ssd-in-keras-part-ii-loss-functions-4f43c292ad2a
