Initialization
zero initialization
- 문제점 : row symmetric, vanishing gradient
- 해결 : np.random.randn*0.01
random initialization
- 문제점 :
1> fan-in이 길수록 출력되는 fan-out의 값이 커진다 -> gradient exploding
2> fan-in이 짧을 수록 출력되는 fan-out의 값이 작아진다. -> gradient vanishing - 해결 : fan-in에 반비례한 초기화 상수(이전에는 0.01)를 사용해야 한다.
Xavier initialization
- glorot initialization 이라고도 부름
- 현재는 fan-in과 fan-out을 모두 고려하는 방식을 선택
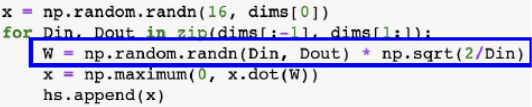
He Initialization
- fan-in 만 고려하는 방식
- ReLU 계열에 특화
Optimizer
SGD
- random 하게 추출한 mini-batch 씩 gradient descent 진행.
- batch_size = mini-batch size(default = None = 32)
+ Momentum
- v_(t-1)에 이전 속도가 저장되어 있다.
- Y를 곱해 이전 속도를 얼마나 반영할 지 결정
NAG
Adagrad
Mini-Batch
- mini-batch : 단일 train iteration에서 gradient descent하는데 사용하는 data의 총 개수
- epoch : data 전체를 train한 횟수

vis ta vie