
Github Repo : BE Repo
Notion URL : 노션페이지
❓ 문제점
검색 기능을 개발 하기위해 spring data jpa의 네이밍 컨벤션을 활용하려고 했지만 자세한 상황의 쿼리문을 작성하기엔 무리가 있었고
검색 기능의 고도화를 위해 index를 공부해서 도입해야했다.
그리고 index를 공부하며 Full Text Search를 사용해야겠다고 판단됐다.
🔑 시도 && 해결 방법
처음에 개발한 검색 기능
@Query("select n FROM News n WHERE n.title like %:keyword% or n.content like %:keyword% or n.category like %:keyword%")
Page<News> searchNewsByKeyWord(@Param("keyword") String keyword, Pageable pageable);솔직히 이것도 잘됐다.. 하지만 명색이 프로젝트인데 이대로 검색기능을 끝내는건 아니라는 생각이 들어 index를 사용해서 검색 성능을 향상 시켜보기로 했다.
링크텍스트
위의 블로그를 보고 인덱스의 개념에 대해 많이 이해가 됐다.
DB에 인덱스가 없다면 책에 목차가 없는 것 처럼 특정 조건에 대해 검색을 했을때 모든 데이터 베이스를 뒤져야한다.
그림으로 보자

인덱스를 걸지 않았을때 의 모습이다. 카테고리가 java인 데이터를 찾으려면 10000개의 데이터를 모두 검사해야한다.

하지만 이렇게 인덱스를 걸어주면 내부적으로 데이터를 B-Tree라는 구조에 저장하기 때문에 맨처음부터 java라는 문자열을 순차적으로 조회하지 않아도 된다
그리고 찾아낸 id로 DB에서 조회를 바로하면 되는것
그래서 인덱스를 걸려고 했더니 여기서 문제 ..
내가 하려는 작업은 제목,내용, 카테고리에 검색어가 포함이 되면 해당 뉴스 기사를 조회하려고 하는것인데
인덱스는 정확히 값이 일치해야한다 그래서 숫자, 날짜등의 데이터에 유용하다.
다시 말해서 내가 하려는 텍스트 데이터를 검색하려는데는
full Text Index를 사용해야 한다는것.
그 이유는 아래와 같다.
-
일반적인 B-Tree 인덱스는 값의 전체 일치 또는 값 범위에 기반한 검색에 가장 잘 맞습니다. 이러한 인덱스를 사용하여 텍스트 필드를 검색하려면 'LIKE' 연산자를 사용하고 퍼센트 (%) 와일드카드를 사용해야 하는데, 이는 성능이 느려질 수 있습니다.
-
반면에, 풀 텍스트 인덱스는 텍스트 데이터 내에서 특정 단어 또는 문구를 찾는 데 특화되어 있습니다. 이러한 인덱스는 각 단어의 발생 빈도를 추적하고, 쿼리 시 이 정보를 사용하여 데이터를 빠르게 검색합니다. 풀 텍스트 검색은 또한 부분 일치 검색을 허용하므로, 검색어가 텍스트의 일부분과만 일치하더라도 관련 결과를 반환할 수 있습니다.
즉 index에 like를 걸렴녀 성능이 느려지고
부분 일치 검색등을 지원하는 full text index가 적합하다는것
Full Text Index를 사용하는 방법은 다음과 같다.
ALTER TABLE news ADD FULLTEXT(content, title,category);
content, title, category에 풀텍스트 인덱스를 걸어주고
@Query(
value ="SELECT * FROM news WHERE MATCH(title,content,category) AGAINST (:keyword IN BOOLEAN MODE) "+"LIMIT :limit OFFSET :offset", nativeQuery = true
)MATCH() ... AGAINST 구문을 사용하여 해당 인덱스를 활용하는 쿼리를 정의한다.
여기서 여러가지 문제가 터졌다...
첫번쨰 문제: 위의 코드는 완성본이라 boolean mode를 썼는데 원래full text index를 생성할때 ngram 검색 파서를 사용했다.
ALTER TABLE news ADD FULLTEXT(content, title,category) WITH PARSER ngram;
ngram 검색 파서는 특정 문자열을 n개의 연속적인 문자로 나누어 풀 텍스트 인덱스를 생성하고 검색할 수 있다.
예를들어 오마이걸을 검색하면 "오마", "마이","이걸" 이런식으로 검색 대상인 텍스트와 검색어를 쪼개서 일치 여부를 판단하는데 여기서
"오마이걸" 을 검색했는데 "마이"크로소프트 라는 검색어를 반환해왔다..... ㅋㅋㅋㅋㅋㅋㅋㅋ
그래서 ngram 검색파서는 검색에 유연성을 제공하지만 검색 결과에 너무 많은 노이즈가 들어간다고 판단했다
그렇다고 ngram 파서를 떼고 FullText를 적용하면
공백기준 정확한 검색어를 입력해야만 검색이 되었다.
그래서 둘 사이의 절충안을 찾던 중
MySQL의 풀 텍스트 검색에서 BOOLEAN MODE를 사용할 수 있다는걸 알았다.
이는 여러가지 연산자를 사용하여 검색 쿼리를 정밀하게 조정 할 수 있는것인데
+: 단어가 존재해야 합니다. 예를 들어, +apple은 'apple'이라는 단어가 문서에 포함된 경우에만 문서를 반환합니다.
-: 단어가 없어야 합니다. 예를 들어, -apple은 'apple'이라는 단어가 문서에 포함되지 않은 경우에만 문서를 반환합니다.
> 또는 <: 단어의 상대적 중요성(가중치)를 조정합니다. 예를 들어, >apple은 'apple'이라는 단어가 문서에 포함될수록 문서의 관련성 점수를 더 높게 책정합니다.
*: 와일드카드 연산자입니다. 단어의 일부분에 대해 검색하려면 이 연산자를 사용할 수 있습니다. 예를 들어, appl*는 'appl'로 시작하는 단어(예: apple, application 등)를 모두 검색합니다.
"": 정확한 문구를 검색합니다. 예를 들어, "apple tree"는 'apple tree'라는 정확한 문구가 포함된 문서만 반환합니다.
위는 boolean mode의 연산자에 대한 정리이다.
그래서 나는 해당 키워드의 뒷글자를 좀 덜적어도 검색되는 유연한 검색을 원했기 때문에
ex) "오마이걸" 의 "오마이"만 검색해도 검색되길 원함.
List<News> newsListByCategory = newsRepository.fullTextSearchNewsByKeyWordNativeVer(
"+"+keyword+"*",pageable.getPageSize(),(int)pageable.getOffset());"+keyword + "*" 이렇게 검색어 뒤에 와일드 카드를 주었다.
여기서 의문, Like랑 똑같은거 아니야??
그것에 대한 답변을 정리하자면
1.인덱스 활용 : Like 연산자의 경우 와이들 카드가 앞에있을때 즉 , (%keyword) 이면 인덱스를 활용하지 않으므로 성능이 떨어질 수 있다. 반대로 boolean mode는 * 와일드 카드를 앞쪽에 사용해도 풀 텍스트 인덱스를 사용한다.
-
데이터 양: 대량의 데이터를 검색해야 할 때 모든 데이터를 스캔해야 하기때문에 LIKE 연산자는 성능이 떨어질 수 있다. 반면에 BOOLEAN MODE의 '*' 연산자는 풀 텍스트 인덱스를 활용하므로 대량의 데이터를 효율적으로 검색할 수 있다.
-
검색 정밀도 : 접두어 검색이 된다.
like는 무조건 해당 검색어가 문장에 포함되면 가져오지만
boolean mode에서 연산자는 접두어 검색에만 사용된다.
두번째 문제 : mysql의 기본설정 값에
'innodb_ft_min_token_size'가 3으로 설정 되어있어 3글자 보다 적은 단어에 대해서는 검색이 되지않았다.
이를 AWS RDS 파라미터 그룹 설정에 들어가서
따로 설정을 해주었다.
세번째 문제 : Full text Index는 JPQL에서 지원하지 않고 때문에 native query를 사용해야 했다.
그말은 JPA가 지원하는 PAGE 기능을 사용할 수 없다는 말이된다.
java @Query( value ="SELECT * FROM news WHERE MATCH(title,content,category) AGAINST (:keyword IN BOOLEAN MODE) "+"LIMIT :limit OFFSET :offset", nativeQuery = true )
그래서 limit와 offset을 직접 쿼리문을 작성해서 페이징 처리를 해주었다.
테스트 결과.
-
테스트 결과
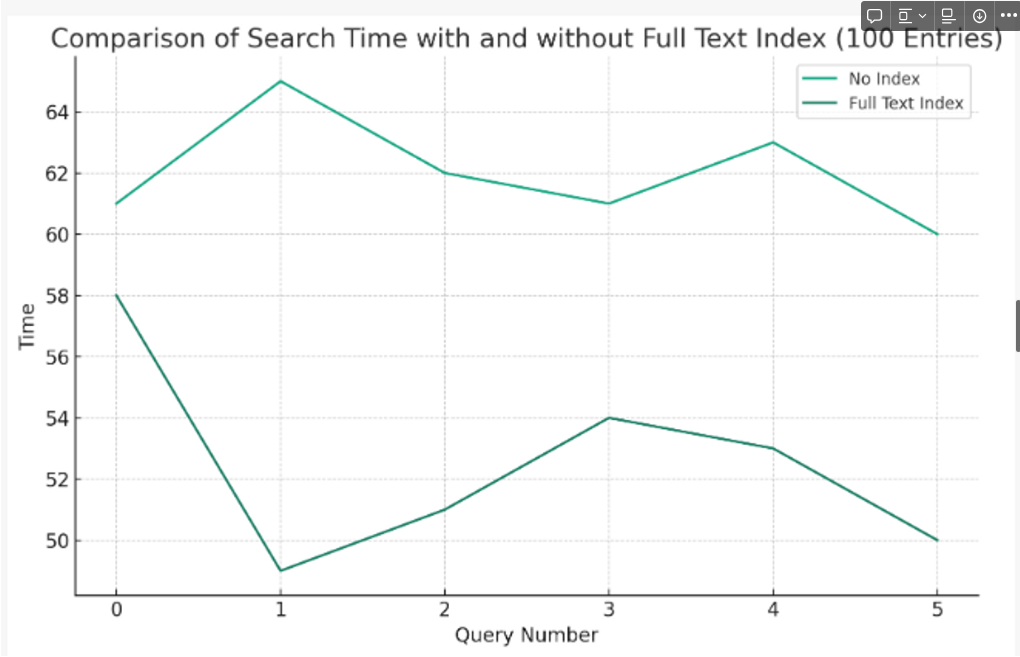
100개
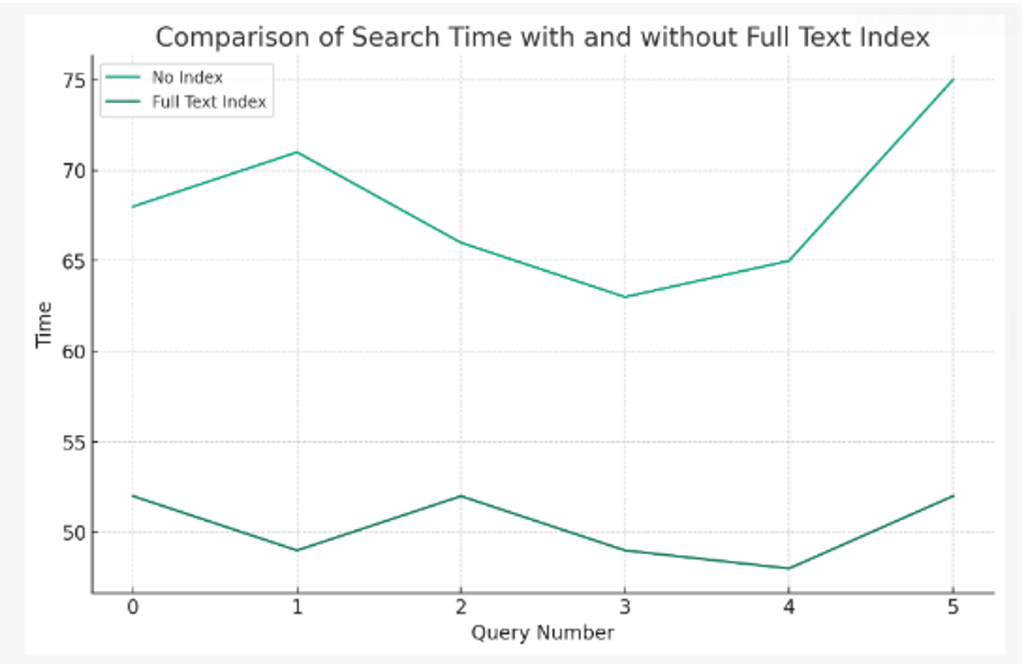
700개
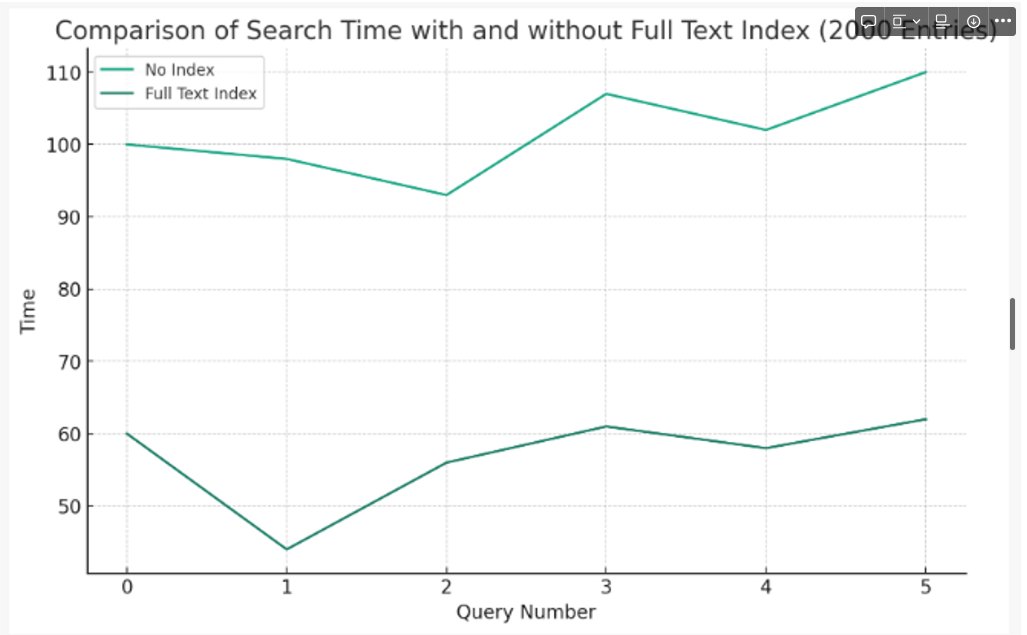
2000개
데이터를 2000개로 늘리니까 검색속도가 2배정도 차이나는 나름 유의미한 결과를 보였다.
데이터를 추가로 수집하는데 어려움이 있어 추가 테스트는 할 수 없었지만
확실히 데이터가 늘어날때마다 full text index를 사용한 검색의 성능이 좋다는 것을 확인 할 수 있다.
