Project
1.Java와 Jdbc 사용해서 RPG 게임 만들어보기 (1일차)

Java 공부를 하고 있지만 "객체 지향 프로그래밍이 좋다.." 라는 말의 의미를 알고있긴 하지만 실제로 개발을 체감해본적은 많이 없다는 생각이 들었다.결국은 SPRING도 객체 지향 설계를 도와준다는점이 큰 장점인 프레임워크이기도하고 여러모로 해당 부분에 대한 공부의
2.당근마켓 프로젝트
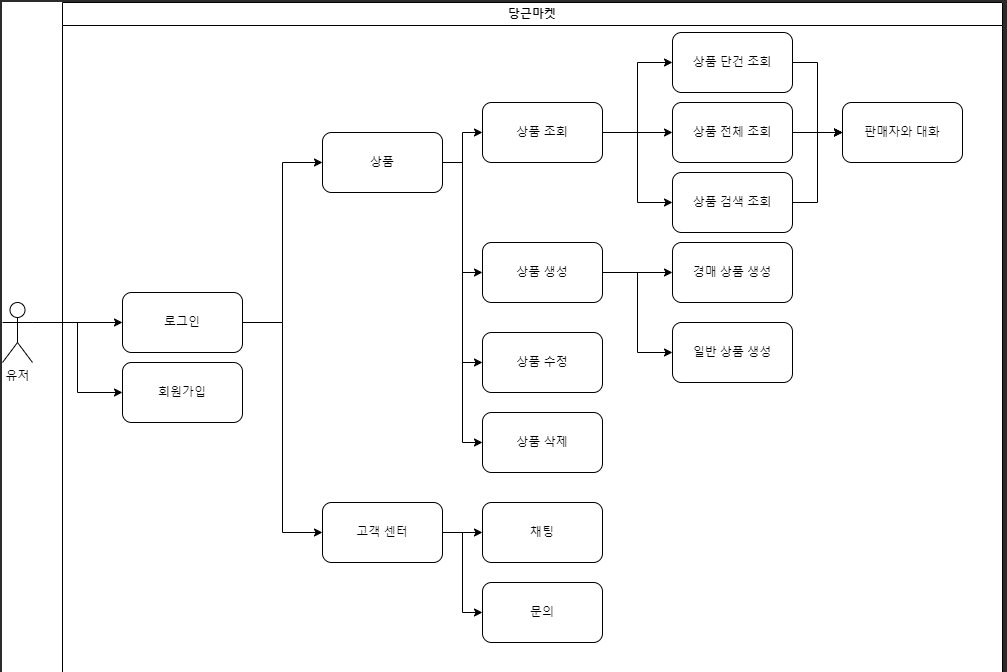
당근 마켓을 구현해보려고한다. 일단 프로젝트 설계와 ERD를 작성했고 유저 인증기능까지만 구현해둔 상태이다. 나는 고객센터와 유저와의 채팅, 문의글 기능을 담당하게 됐다. USE CASEERD이메일 인증, 회원가입 ,로그인 테스트까지 완료
3.당근 마켓 프로젝트2
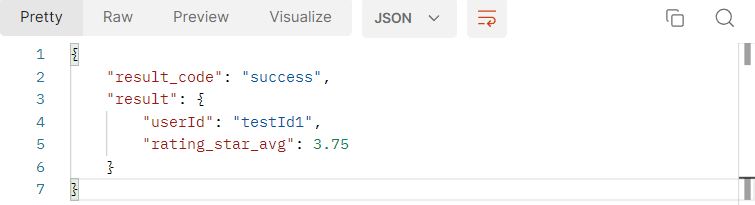
현재 개발된 부분은1\. 유저 로그인 회원가입 및 인가 기능 2\. 고객 문의기능3\. 상담원의 고객 문의에 대한 답변 기능오늘은 상담에 대한 고객의 별점 부여 기능을 구현했다. 유저 엔티티는 위와같이 구성되어 있고 UserRole이 USER일때는 고객이 상담에 대해
4.당근 마켓 프로젝트 (고객센터 채팅 구현 )

당근마켓의 고객센터 관련 기능을 담당해서 1\. 문의 작성2\. 문의에 대한 상담원의 답변 3\. 답변에 대한 유저의 평가 기능을 구현해둔 상태였다. 마지막으로 고객과 상담원 사이의 채팅 기능을 구현하려고 했다. 구체적인 구현 시나리오는 유저가 문의 신청 \-> 상담원
5.항구 Log 프로젝트 - 설계
BE 2명 , FE 1명이 배정된 주특기 프로젝트 주차가 시작되었다. 사전 프로젝트에 이어서 팀장을 맡게 되었는데 첫날은프로젝트 주제선정 - 와이어프레임 작성 - API 문서 작성 - ERD 설계 를 진행했다. notion 주소 : 노션 링크BE Github Repo
6.항구 Log 프로젝트 - Github Actions를 사용한 CI/CD 구축
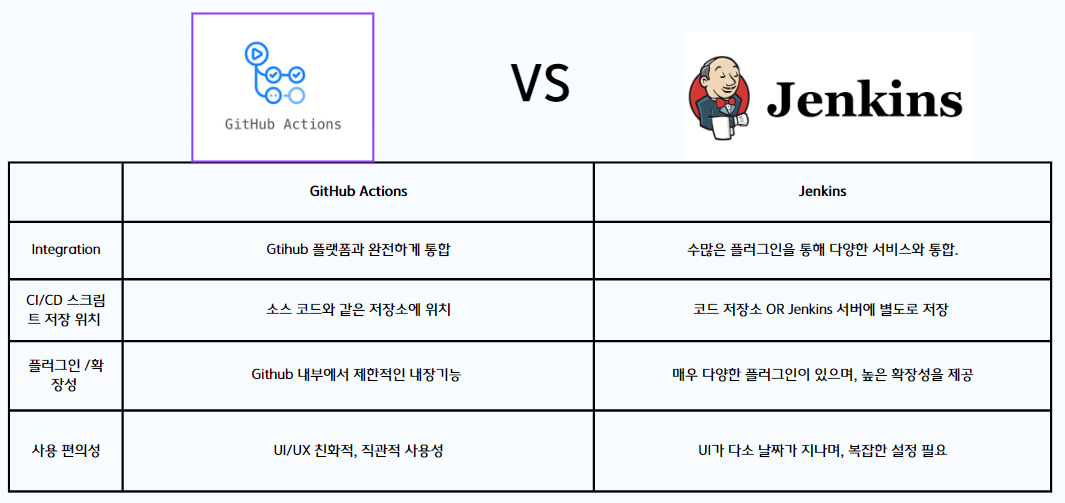
CI/CD Pipeline을 결정할 때 Github Actions와 Jenkins두가지 파이프라인에 대한 특징들을 비교해 보았습니다. Jenkins와 다르게 Github Action은 스크립트가 github 소스코드 내에서 관리되고 직관적인 UI를 가진다는 특징이
7.항구 Log 프로젝트 - Spring-boot에 Https 적용
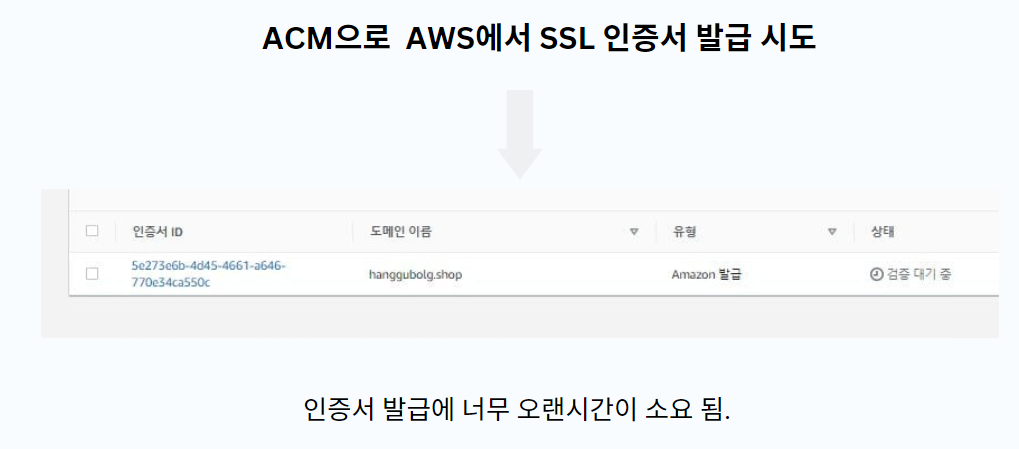
우선 HTTPS에 대한 개념을 확실하게 잡았다. HTTPS 의 어떻게 요청되는가를 공부해보았는데 client가 Https 요청 server에서 ssl 인증서와 public key를 제공올바른 CA에서 발급한 인증서인지 확인제공받은 public key로 데이터를 암호화
8.항구 Log 프로젝트 - 테스트 단계

프로젝트를 완성하고 실제 항해 99 인원들에게 테스트를 부탁했다 ㅎㅎ 구현한 서비스의 목적성을 달성하려면 직접 테스트를 부탁드려서 데이터를 만드는 것 까지가 진정한 프로젝트의 완성이라고 생각이 들었다 .다들 테스트를 본인의 책상을 업로드해주신 모습 ㅜㅜ 내 책상은 이렇
9.뉴닉 클론코딩 프로젝트- 설계
항해99 클론코딩 프로젝트 주차가 시작됐다. 우리팀은 뉴닉 이라는 사이트를 클론 코딩하는것으로 정해졌다!!뉴스를 볼 수 있고 email을 적으면 email 주인에게 뉴스레터를 보낼 수 있는 사이트이다. 와이어 프레임 설계 와이어프레임FE 분들과 함께 와이퍼 프레임을 작
10.뉴닉 클론코딩 프로젝트 - 웹 크롤링
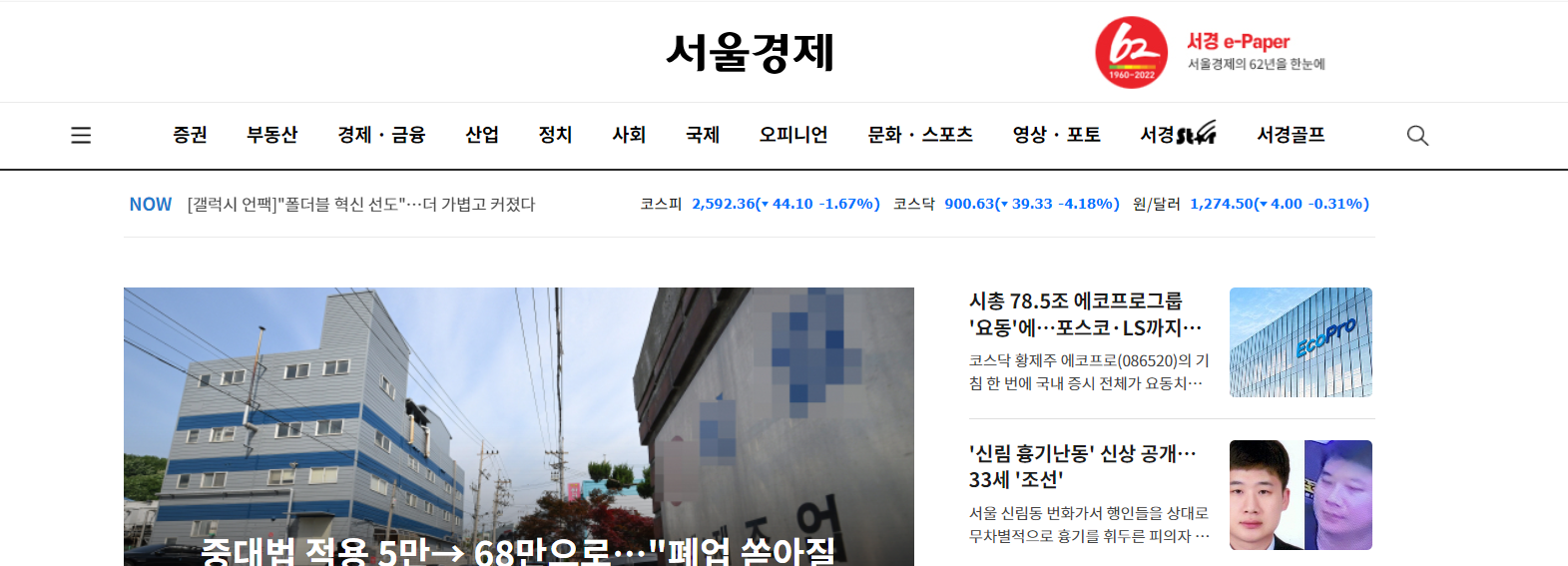
Github Repo : BE RepoNotion URL : 노션페이지 뉴닉이라는 사이트를 클론 코딩하기 위해 다른 사이트에서 기사를 긁어오기로 결정했다. 서울경제 가 카테고리별로 잘 나뉜것 같아. 해당 사이트를 크롤링 해오기로 했다. 그런데 내가 지금까지 해본 크롤링
11.뉴닉 클론 코딩 프로젝트 - 검색 기능 개발

Github Repo : BE RepoNotion URL : 노션페이지 검색 기능을 개발 하기위해 spring data jpa의 네이밍 컨벤션을 활용하려고 했지만 자세한 상황의 쿼리문을 작성하기엔 무리가 있었고 검색 기능의 고도화를 위해 index를 공부해서 도입해야했
12.OpenRun Project Project - 설계
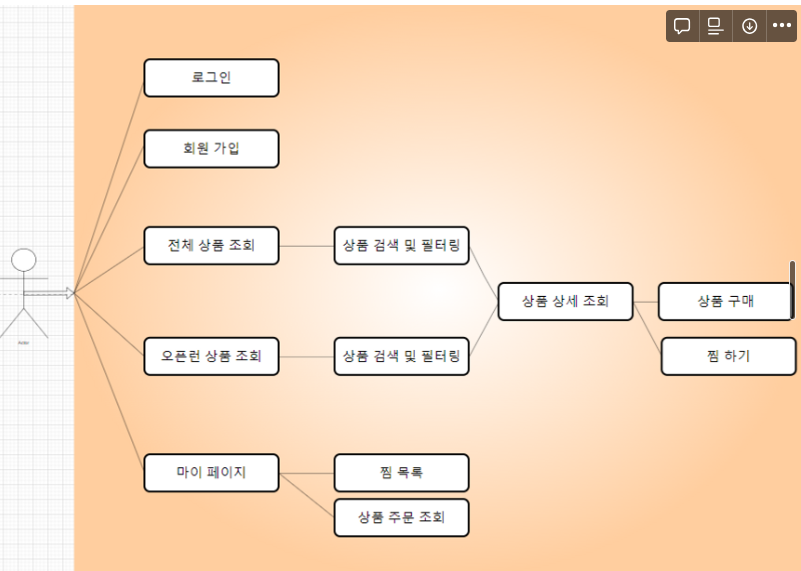
github Repo 주소Notion 주소오픈런 (예약시스템)주제 선정 이유 : 대용량 트래픽 처리를 할 수 있다 생각했고 추가로 상품 검색과 관련해서 대용량 데이터 처리에 대한 부분까지도 도전해볼 수 있는 주제라서 스코프 조절에 용이하다고 생각했음. 메인페이지로그인
13.Jmeter 사용법 정리
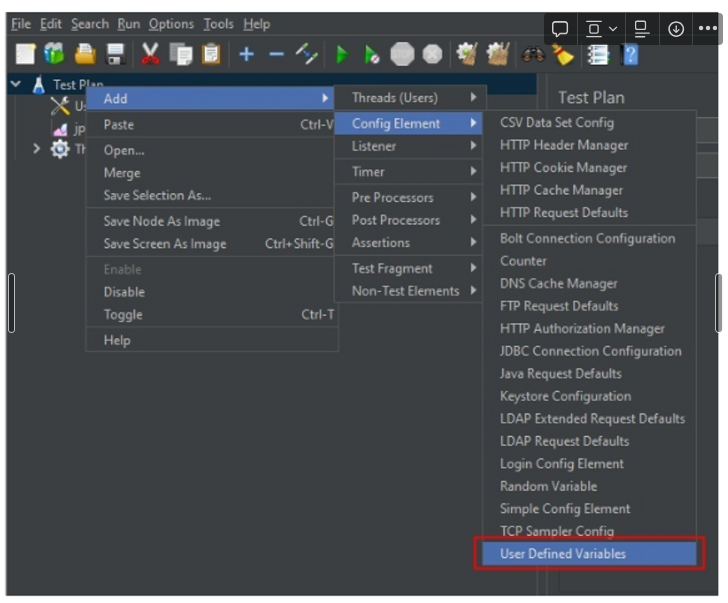
JMeter를 사용하기 전에 알아야 하는 개념에 대해 살펴보자.Thread Group: 몇 개의 쓰레드가 동시에 요청을 보내는 지Sampler: 어떤 유저가 해야 하는 액션Listener: 응답을 받았을 때 어떤 동작을 취하는 지 (검증, 리포트, 그래프 그리기 등)C
14.OpenRun Project - 비관적 락 적용해서 동시성 문제 해결 하기
비관적 락 적용 전 ** 50개 요청중 47개 성공 (Error : 6%) 초기 재고 624 주문 후 579 재고 45개 빠짐 ⇒ 동시성
15.OpenRun Project - Querydsl 사용해서 검색 쿼리 작성하기
QueryDsl 적용 이유 동적 쿼리 작성에 유용함 Complile time에 query error 검증 설정한 검색 조건 키워드 검색(일반적인 검색어) => 지금은 Like 문을 활용했는데 이후 검색 성능 향상을 위해 index나 full Text Index를
16.OpenRun Project - Redis를 사용해서 대용량 데이터의 조회 성능 향상 시키기(count query 개선)

약 500만건의 데이터에 대해서 페이징 처리 된 페이지를 조회해오는데 너무 오랜 시간이 걸리는 문제가 발생했다.전체 상품 조회에 대한 페이징 처리라 index도 많은 도움이 되지 않았다. 그래서 발견한 문제점이 select 쿼리는 크게 시간이 소요되지는 않지만count