Github Repo : BE Repo
Notion URL : 노션페이지
❓ 문제점
뉴닉이라는 사이트를 클론 코딩하기 위해 다른 사이트에서 기사를 긁어오기로 결정했다.
서울경제 가 카테고리별로 잘 나뉜것 같아. 해당 사이트를 크롤링 해오기로 했다.
그런데 내가 지금까지 해본 크롤링은 단순히 URL이 주어지고 해당 URL에 대한 내용을 크롤링 해오는 정도였는데
"매일 특정 시간에 오늘 올라온 기사를 크롤링" 하는 것을 목표로 하고 시작해서 처음부터 막막함이 있었다.
🔑 시도 && 해결 방법
1. 스케줄러 사용
@Scheduled(cron = "0 0 3 * * ?")
public void updateNews() throws InterruptedException {
log.info("오늘의 뉴스 업데이트 ");
// 크롤링 시작
try {
// 원하는 뉴스 사이트의 URL을 지정
String url = "https://www.sedaily.com/";
// ....
}
}
매일 특정시간에 뉴스기사를 크롤링 하기 위해 "스케쥴러"를 사용했다.
배포환경인 ubuntu 서버 시간이랑 달라서(12시간 차이) 이 부분을 코드를 수정하던 서버 시간을 조정하던 둘중 하나를 할듯.
2. 각각 카테고리 링크로 접속
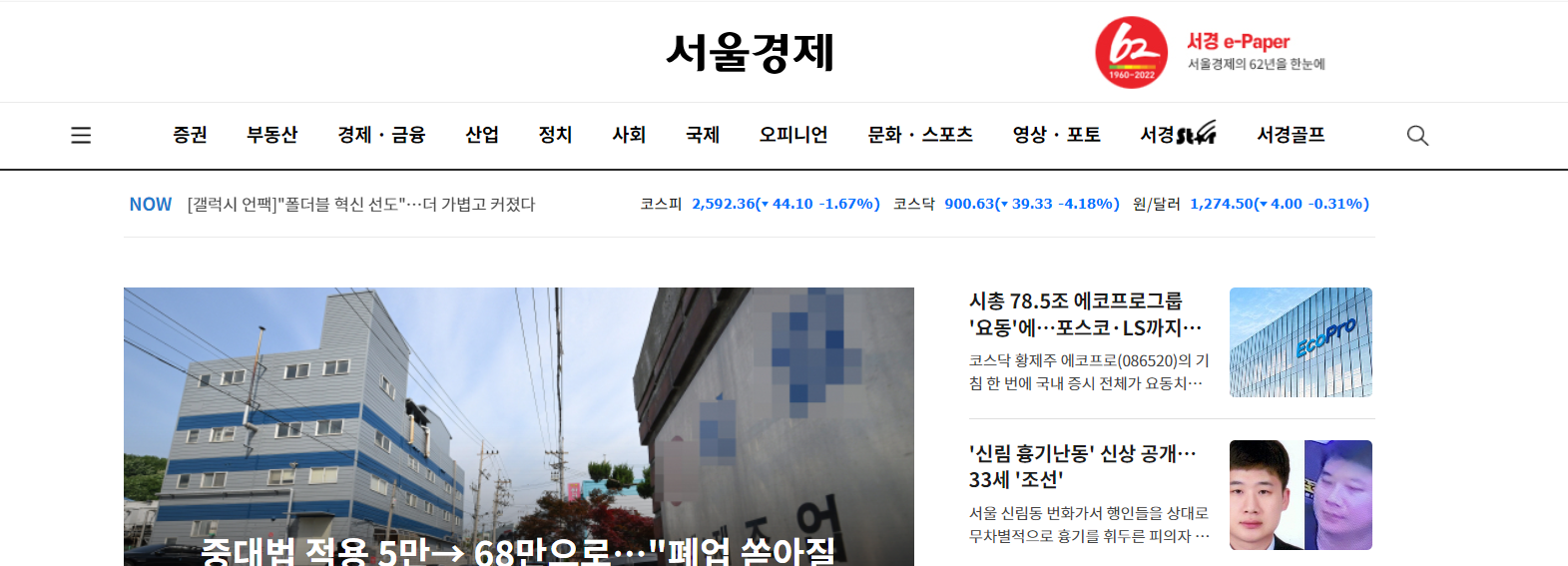
사진에서 볼 수 있듯이 증권, 부동산, 경제 등등 여러가지 카테고리로 나뉘는데 각각의 카테고리로 가서 뉴스 기사의 링크를 추출해야 했다.
우선 링크를 뽑을 수 있는 방법은
// 원하는 카테고리 목록을 감싸고 있는 ul 태그 선택
Element ulCategory = doc.select("ul.dep1").first();
List<Category>categoryLinkList = new ArrayList<>();
if (ulCategory != null) {
// li 태그들 선택
Elements categoryList = ulCategory.select("li");
// 각 li 태그에 대해 a 태그의 href 속성 값을 가져와 출력
for (Element category : categoryList) {
Element aTag = category.selectFirst("a");
if (aTag != null) {
String categoryName = aTag.text();
// 대표적인 카테고리 목록에 해당하는 경우에만 출력
if (mainCategories.contains(categoryName)) {
String categoryLink = aTag.attr("href");
categoryLinkList.add(new Category(categoryName,categoryLink));
// 각 카테고리 링크 리스트에 추가
System.out.println("Category: " + categoryName);
System.out.println("Link: " + categoryLink);
System.out.println();
}
}
}
// 카테고리들 링크 수집
}
원하는 구역으로 가서 Element를 추출하고 html 파일에서 어떤 속성에 원하는 링크가 있는지 파악해야한다.
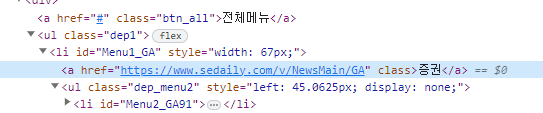
위를 보면 ul 태그의 depl -> 각각의 카테고리가 li 태그로 나뉨
-> a태그의 href 요소에 링크존재 !!
여기서 주의할점은 각 카테고리마다 하위 카테고리가 있는데 나는 굵은글씨로 표시된 대표적인 10가지의 카테고리만의 분류를 원해서 해당부분을 판별하는 로직을 추가해야한다는 것이다.
3. 오늘 올라온 기사 판별하기
위에서 수집한 카테고리 별 링크를 뽑아서 상세조회를 할 오늘 날짜의 뉴스 기사의 링크를 수집하는 과정이다.
//오늘 뉴스 기사 링크
List<Category> todaysNewsLinkList = new ArrayList<>();
//수집한 카테고리 링크로 들어가서 오늘 올라온 기사 링크 수집
for(Category categoryLinkPair : categoryLinkList) {
Document category_doc = Jsoup.connect(categoryLinkPair.getLink()).get();
Element ulNews = category_doc.select("ul.sub_news_list").first();
log.info("지금 카테고리는 "+ categoryLinkPair.getCategory());
Elements newsList = ulNews.select("li");
//각 카테고리 중 오늘 기사만 뽑아서 링크 뽑자.
if (newsList != null) {
for (Element news : newsList) {
Element textAreaDiv = news.select("div.text_area").first();
if (textAreaDiv != null) {
Element aTag = textAreaDiv.select("a").first();
Element dateSpan = textAreaDiv.select("span.date").first();
if (aTag != null && dateSpan != null) {
String date = dateSpan.text();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy.MM.dd");
LocalDate newsDate = LocalDate.parse(date, formatter);
// LocalDate targetDate = LocalDate.parse("2023.07.18", formatter);
// If the news was posted today
if (newsDate.equals(LocalDate.now())) {
String newsLink = aTag.attr("href");
todaysNewsLinkList.add(new Category(categoryLinkPair.getCategory(),newsLink));
System.out.println(newsLink);
}else{
break;
}
}
}
}
}
}서울 경제에서 날짜 형식이 yyyy.MM.dd 형식이어서 해당 패턴을 포맷으로 만들고 나중에 최신순으로 기사를 정렬 할 것이므로 LocalDate 타입으로 파싱해주었다.
그리고 해당 날짜가 오늘 날짜인 LocalDate.now()와 겹치면 상세 조회할 뉴스기사의 리스트에 추가한다.
4. 기사 상세 조회 페이지에서 이미지 , 내용 따로 분류하기

서울 경제 기사를 보면 내용 중간중간에 이미지가 포함되어 있다.
하지만 뉴닉을 보니 전부 상단에 이미지 1개를 두고 내용을 기입하는 형식이라 나도 기사의 첫 이미지만 가져온 뒤 내용과 따로 저장하기로 했다.
String firstImageUrl = "";
if(imgs.first() != null) {
firstImageUrl = imgs.first().absUrl("src"); // 첫 번째 이미지 URL을 가져옵니다.
}
// 이미지와 관련된 모든 요소를 제거합니다.
Elements figureElements = newsDetails_doc.select("figure");
Elements imgElements = newsDetails_doc.select("img");
Elements scriptElements = newsDetails_doc.select("script");
for (Element element : figureElements) {
element.remove();
}
for (Element element : imgElements) {
element.remove();
}
for (Element element : scriptElements) {
element.remove();
}
Elements content_html = texts;// 본문 내용을 가져옵니다.
String content = content_html.toString();figure, img,script 태그에 이미지가 속해있어서 해당 태그들을 만나면 본문에서 제외 해주었다.
- 기사별 태그 추출

뉴닉 웹 사이트를 보면 이렇게 기사마다 관련된 내용의 태그가 존재한다.
이 부분을 구현하기 위해 내가 택한 방법은
- 카테고리 별 태그 후보들을 미리 지정해둠.
- 크롤링 할때 상세 기사 내용을 확인하며 가장 빈출된 단어 2가지를 추가로 tag로 공백 기준으로 저장
if(newsDetailsLinkPair.getCategory().equals("증권")) {
db_category = newsDetailsLinkPair.getCategory();
tags += db_category;
List<String> targetTagList = Arrays.asList("주식","상장", "투자", "증시","브로커","주가","포트폴리오","경제","국내증시","해외증시","채권","투자전략","종목");
tags = selectTagsForCategory(content_html.text(), tags, targetTagList);
}
만약 증권 카테고리라면 위와 같이 태그 후보들을 설정하고
selectTagsForCategory() 매서드로 태그를 공백 기준으로 저장했다.
private String selectTagsForCategory(String content, String tags, List<String> targetTagList) {
PriorityQueue<Map.Entry<String, Integer>> pq = new PriorityQueue<>(
(a, b) -> a.getValue().equals(b.getValue()) ? b.getKey().compareTo(a.getKey()) : a.getValue() - b.getValue());
for (String tag : targetTagList) {
int count = countOccurrences(content, tag);
if (count > 0) {
pq.offer(new AbstractMap.SimpleEntry<>(tag, count));
if (pq.size() > 2) {
pq.poll();
}
}
}
// Extract the top 2 tags and add them to the 'tags' string
while (!pq.isEmpty()) {
tags += " " + pq.poll().getKey();
}
return tags;
}빈도순으로 정렬할 목적으로 priority queue를 사용했고 본문에 1번이상 등장했다면 그 횟수를 세어서 pq에 넣어주었다.
public int countOccurrences(String text, String word) {
int count = 0;
int index = 0;
while ((index = text.indexOf(word, index)) != -1) {
count++;
index += word.length();
}
return count;
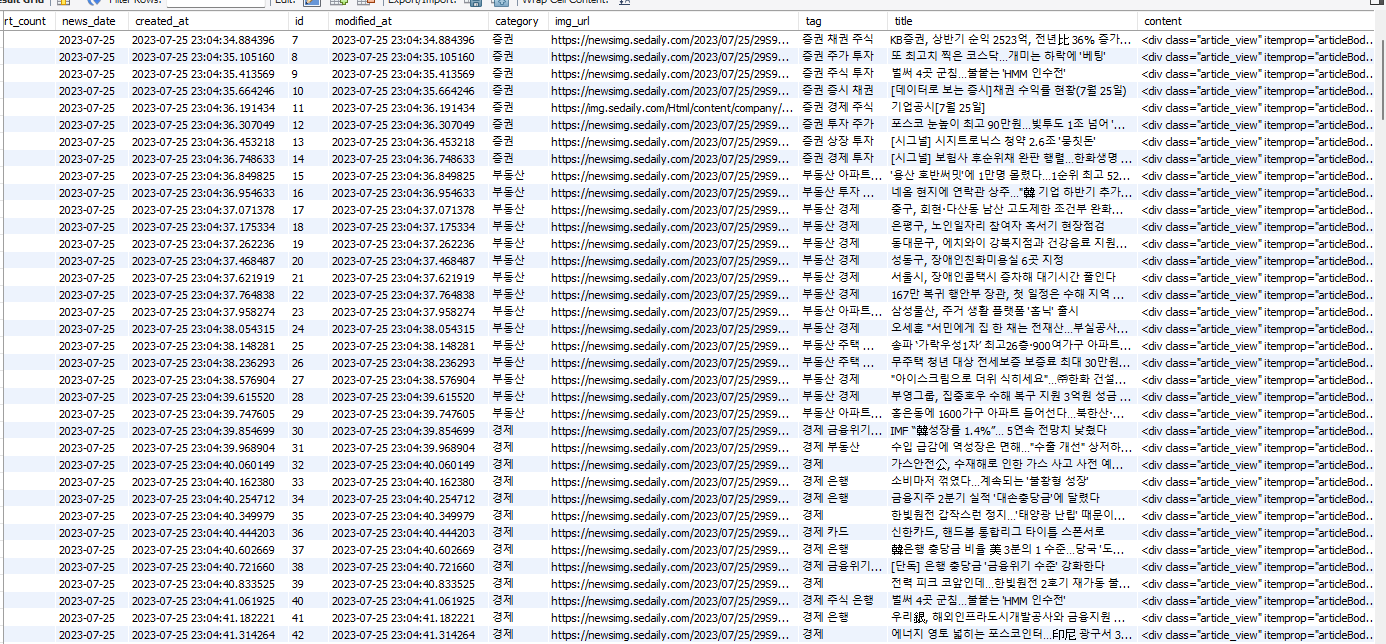
}크롤링 결과
💡 알게 된 점
java가 아니라 html파일을 계속 보려니 너무 힘들었다. ㅎㅎ 그래도 스케줄러도 활용해보고 원하는 구현을 위해 많은 시도를 해보았다.
(ex) tag 뽑을 때 pq사용, 이미지 제거, 카테고리 추출을 위해 pair calss)
크롤링을 성공하면서 뉴닉 클론코딩 프로젝트의 큰 고비를 넘긴 것 같다!
