논문 정보
[cite_start] Title: OpenVLA: An Open-Source Vision-Language-Action Model [cite: 2, 3][cite_start] Authors: Ted Xiao, Moo Jin Kim, et al. [cite: 4, 5][cite_start] Institution: Stanford University, UC Berkeley, Google DeepMind, TRI etc. [cite: 36][cite_start] Topics: Vision-Language-Action (VLA), Robot Learning, Open-Source, Fine-tuning [cite: 10]
1. 개요 (Overview)
[cite_start]OpenVLA는 70억 개(7B)의 파라미터를 가진 오픈소스 VLA(Vision-Language-Action) 모델입니다[cite: 25].
[cite_start]Open X-Embodiment 데이터셋의 97만 개 로봇 에피소드로 학습되었으며, 일반적인 소비자용 GPU에서도 효율적으로 파인튜닝(Fine-tuning)하고 실행할 수 있는 것이 가장 큰 특징입니다[cite: 25, 27]. [cite_start]기존의 SOTA 모델인 RT-2-X(55B)보다 훨씬 작은 크기임에도 불구하고 더 뛰어난 성능을 보여주며, 로봇 제어 분야의 새로운 기준(State-of-the-Art)을 제시합니다[cite: 26, 33].
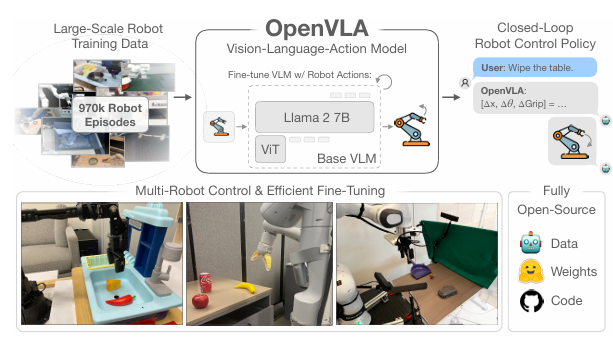
[cite_start]그림 1: OpenVLA는 97만 개의 로봇 에피소드로 학습된 7B 파라미터 모델로, 시각 정보와 자연어 명령어를 입력받아 로봇 액션을 생성합니다[cite: 25].
2. 연구 배경 (Motivation)
기존 연구의 한계
- [cite_start]일반화 부족: 기존 로봇 정책들은 훈련 데이터 이외의 환경(새로운 물체, 배경, 조명 등)에 적응하는 데 어려움을 겪습니다[cite: 41].
- [cite_start]폐쇄적인 생태계: RT-2-X와 같은 고성능 VLA 모델들은 대부분 비공개(Closed)여서, 아키텍처나 데이터셋에 대한 접근이 제한적입니다[cite: 48].
- [cite_start]높은 비용: 거대 모델을 학습하고 새로운 작업에 적용(Fine-tuning)하기 위해서는 대규모 컴퓨팅 자원이 필요하여 접근 장벽이 높았습니다[cite: 49].
OpenVLA의 목표
- [cite_start]강력한 성능을 유지하면서도 완전한 오픈소스 VLA 모델을 제공합니다[cite: 50].
- [cite_start]소비자용 GPU에서도 효율적으로 동작하고 파인튜닝할 수 있는 최적화된 방법을 제시합니다[cite: 61].
3. 모델 구조 (Model Architecture)
[cite_start]OpenVLA는 거대 언어 모델(LLM)을 기반으로 시각 정보를 처리하여 로봇 제어 신호를 생성하는 구조를 가집니다[cite: 104].
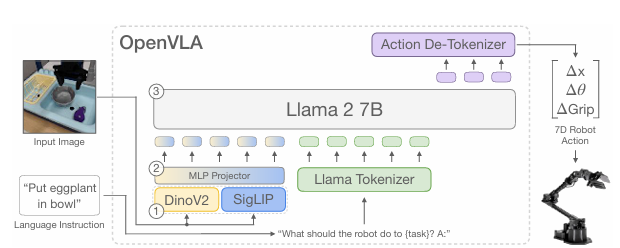
[cite_start]그림 2: OpenVLA는 두 개의 비전 인코더(SigLIP, DinoV2)와 Llama 2 언어 모델을 결합한 구조를 가집니다[cite: 104, 105].
3.1. 아키텍처 핵심 요소
- [cite_start]Visual Encoder (이중 구조): 두 가지 강력한 비전 모델을 융합하여 사용합니다[cite: 56, 121].
- [cite_start]SigLIP: 이미지의 의미론적(Semantic) 정보를 파악합니다[cite: 121].
- [cite_start]DINOv2: 공간적(Spatial) 정보와 세밀한 디테일을 파악하여 로봇 제어의 정밀도를 높입니다[cite: 123].
- [cite_start]Projector: 시각 특징(Feature)을 언어 모델이 이해할 수 있는 토큰 공간으로 매핑하는 MLP 레이어입니다[cite: 105].
- [cite_start]LLM Backbone: Llama 2 (7B) 모델을 기반으로 하여 강력한 추론 능력을 활용합니다[cite: 105, 120].
3.2. 액션 토큰화 (Action Tokenization)
- [cite_start]로봇의 연속적인 움직임(7-DoF Action)을 256개의 이산적인(Discrete) 토큰으로 변환합니다[cite: 131].
- [cite_start]이를 통해 언어 모델이 텍스트를 생성하듯이 로봇의 행동을 예측하도록 학습시킵니다[cite: 139].
4. 실험 결과 (Experiments)
4.1. 일반화 성능 (General Performance)
[cite_start]OpenVLA는 BridgeData V2 및 Google Robot 평가에서 기존 모델들을 압도했습니다[cite: 259, 262].
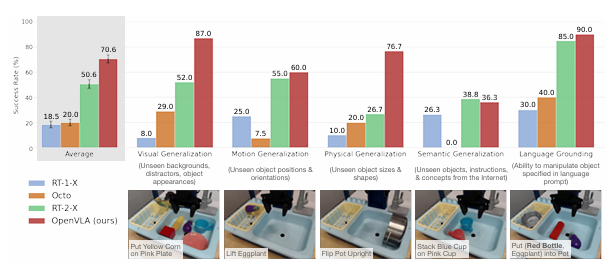
[cite_start]그림 3: OpenVLA(빨간색)는 55B 파라미터의 RT-2-X(초록색)보다 7배 작지만, 시각, 동작, 물리적 일반화 등 대부분의 지표에서 더 높은 성공률을 기록했습니다[cite: 52, 237].
- [cite_start]성능 우위: RT-2-X 대비 16.5% 더 높은 작업 성공률을 달성했습니다[cite: 52].
- [cite_start]강건함: 훈련 데이터에 없는 새로운 배경, 방해 물체(Distractor), 물체 위치 변화 등에 대해 뛰어난 일반화 성능을 보였습니다[cite: 251, 268].
4.2. 효율성 및 파인튜닝 (Efficiency & Fine-tuning)
[cite_start]이 논문의 또 다른 핵심 기여는 효율적인 파인튜닝 및 추론 전략입니다[cite: 53].
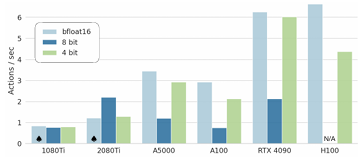
- [cite_start]LoRA (Low-Rank Adaptation): 모델 전체를 재학습하지 않고 일부 파라미터만 학습하는 LoRA 기법을 통해, 소비자용 GPU 하나로도 새로운 로봇 태스크를 빠르게 학습시킬 수 있습니다[cite: 370, 374].
- [cite_start]4-bit Quantization (양자화): 모델을 4비트로 양자화하여 메모리 사용량을 절반 이하로 줄였습니다[cite: 395].
- [cite_start]결과: 성능 저하 없이 RTX 4090 같은 일반 GPU에서도 실시간 제어(약 7Hz 이상)가 가능함을 입증했습니다[cite: 184, 409].
5. 결론 (Conclusion)
[cite_start]OpenVLA는 로봇 학습 분야의 "Llama"와 같은 역할을 목표로 합니다[cite: 49].
[cite_start]강력한 성능의 7B VLA 모델을 오픈소스로 공개했을 뿐만 아니라, LoRA 파인튜닝과 양자화 기술을 통해 누구나 쉽게 자신만의 로봇 제어 모델을 만들고 실험할 수 있는 환경을 제공합니다[cite: 60, 61].
- [cite_start]GitHub: https://openvla.github.io [cite: 8]
- [cite_start]Hugging Face: 모델 체크포인트와 코드가 모두 공개되어 있어 즉시 사용 가능합니다[cite: 28].
