Series 01에서 무엇이 남았는가?
Series 01에서 살펴본 OpenVLA는 Vision-Language-Action(VLA) 패러다임을 오픈소스로 제시한 기준 모델이다. 그러나 OpenVLA는 구조적으로 강력함에도 불구하고, 실제 로봇 제어(real-world control) 관점에서는 치명적인 한계를 가지고 있다.
- Autoregressive decoding으로 인한 느린 추론 속도
- Discrete action 토큰화로 인한 미세 진동(jitter)
- 20~30Hz 수준의 고주파 제어 불가
OpenVLA-OFT(Optimized Fine-Tuning)는 이러한 문제를 해결하기 위해 제안된 실전 로봇 적용용 fine-tuning 레시피다.
핵심 키워드
- Optimized Fine-Tuning (OFT)
- Parallel Decoding
- Action Chunking
- Continuous Action Regression
- High-Frequency Robot Control
연구 문제 (Why OFT?)
OpenVLA는 로봇 action을 언어 토큰처럼 하나씩 생성하는 autoregressive 구조를 사용한다. 이 방식은 언어 생성에는 적합하지만,
- 실시간 제어에는 지나치게 느리고
- discretization으로 인해 제어가 불안정하다
OFT의 질문은 명확하다.
“OpenVLA의 표현력은 유지하면서, 실제 로봇이 부드럽고 빠르게 움직이게 할 수는 없을까?”
핵심 아이디어 (What & How)
OpenVLA-OFT의 핵심은 ‘언어 모델은 유지하되, action 생성 방식을 바꾼다’는 점이다.
- Action을 하나씩 생성하지 않고 chunk 단위로 병렬 생성
- Discrete token 대신 continuous action regression
- Fine-tuning 단계에서만 구조 변경
이를 통해 OpenVLA의 범용성은 유지하면서, 실제 로봇 제어에 필요한 속도와 안정성을 확보한다.
OpenVLA-OFT 구조
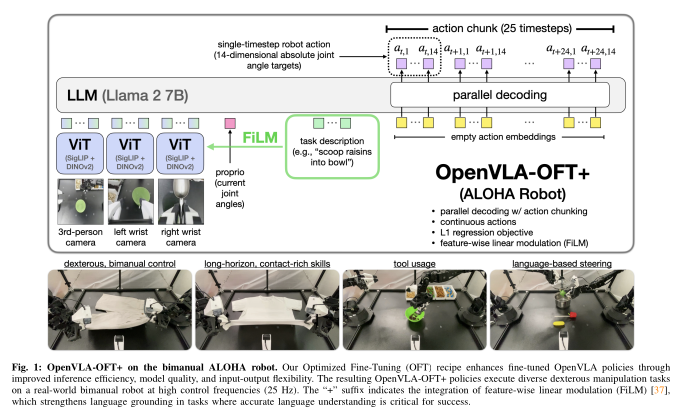
OpenVLA-OFT는 기존 OpenVLA backbone을 그대로 사용한다. 차이점은 action head에 있다.
- 여러 step의 action을 하나의 chunk로 묶어 출력
- 각 action은 연속값으로 직접 예측
즉, 언어 모델은 여전히 Vision + Language를 이해하지만, 출력은 로봇 친화적인 형태로 바뀐다.
Parallel Decoding과 Action Chunking
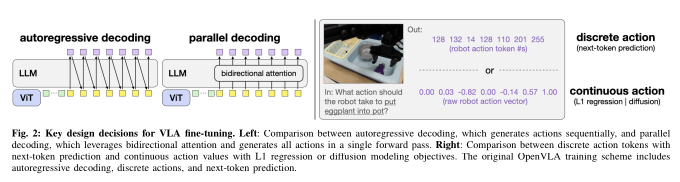
기존 autoregressive 방식은 다음과 같다.
a1 → a2 → a3 → …
반면 OFT는 한 번의 forward pass로 여러 step의 action을 동시에 예측한다.
이 차이가 곧 추론 속도의 차이다.
핵심 수식
OFT에서는 discrete classification loss 대신, 연속 action regression을 위한 L1 loss를 사용한다.
Loss Function
L = || a − â ||1
이 단순한 변화가 action jitter를 크게 줄이고, 부드러운 로봇 제어를 가능하게 한다.
실험 설정
- Benchmark: LIBERO (Spatial / Object / Goal)
- Robot: Franka Panda
- Evaluation: Task success rate
실험 결과 (Results)
- LIBERO 평균 성공률: 76.5% → 97.1%
- Action throughput: 26× 증가
- 실제 로봇 제어 주파수: 25Hz
이는 OFT가 단순한 최적화가 아니라, 실로봇 적용 가능성을 결정짓는 핵심 요소임을 보여준다.
해석 및 의미
OpenVLA-OFT는 새로운 모델이 아니다.
“VLA를 어떻게 써야 현실 세계에서 통하는가?” 에 대한 명확한 해답이다.
- Foundation Model의 표현력은 유지
- 제어는 로봇 친화적으로 변환
이 접근은 이후 등장하는 LIBERO-Plus, dVLA, Hybrid Training 논문들의 출발점이 된다.
한 줄 요약
OpenVLA-OFT는 OpenVLA를 연구용 모델에서 실제 로봇 정책으로 바꾼다.
👉 다음 글: [VLA Series 03] LIBERO-Plus – 성공률의 착시와 진짜 일반화
