Reinforcement Learning
Reinforcement Learning이란?
- Supervised Learning처럼 학습에 있어서 데이터와 라벨이 주어지지 않고, 각 state에 해당하는 action에 reward를 두어 reward를 가장 높게 갖는 방향으로 학습하는 방식이다. 예를 들어, 자전거를 배울 때를 생각해보면, 오른쪽으로 넘어지려 할 경우, 오른쪽으로 핸들을 돌린다면, 넘어지므로, reward가 낮을 것이고, 왼쪽으로 핸들을 돌린다면 넘어지지 않으므로, reward가 높을 것이다. 이러한 방식처럼, reward를 최대화하도록 모델을 학습시키는 방식을 말한다.
Reinforcement Learning Terminology
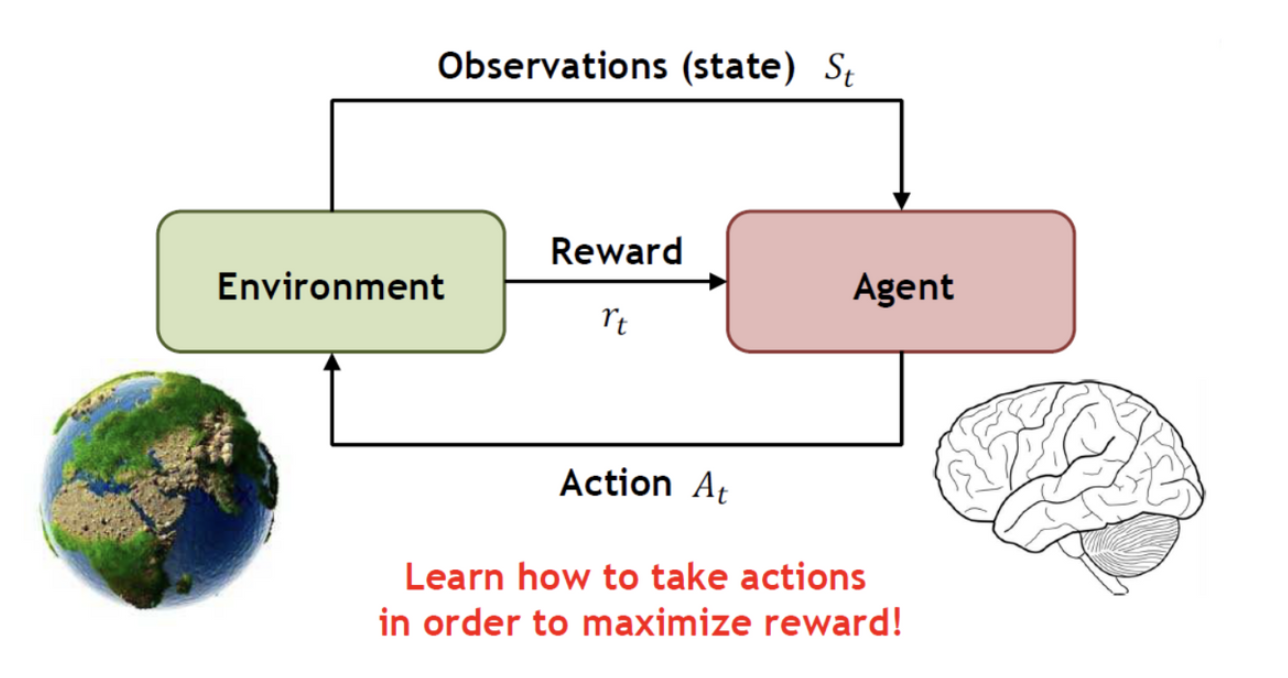
- State : Environment에 해당하는 상태를 의미한다.
- Reward : Agent가 Action 를 취했을 때, 얻을 수 있는 보상을 의미한다.
- Action : Agent가 행하는 행동이다.
- Agent : action을 취하고, 그에 해당하는 reward를 받는 주체이다.
RL Algorithm
Markov Process(MP)
- MP는 현재 발생한 사건은 이전의 사건에만 영향을 받는다는 가정인 Markov Property를 기반으로 한다. 따라서, MP는 다음의 식과 같이 나타내어진다.
- : set of states
- : state transition probability
Markov Reward Process(MRP)
- MP에 Reward가 추가된 개념으로, 앞으로 받을 모든 reward를 계산한 것이 return된다. 같은 reward라도, 현재 받는 경우와, 미래에 받는 경우를 다르게 평가하기 위하여 Discount Factor라는 개념이 도입된다.이렇게 각 State마다, Return의 기댓값을 State-value function으로 정의한다.
- Discounting Factor :
- Return :
- State-value Function
- : set of states
- : state transition probability
- : Reward function
- : Discounting Factor
Markov Decision Process(MDP)
-
MRP에서 Action이 도입된 개념으로, State를 넘어갈 때, 어떤 Action을 수행하느냐에 따라서, reward와 state가 바뀐다.
현재 State에서 어떤 Action을 수행할 것인지를 Policy라 하며, MRP가 각 state 마다 받을 수 있는 return의 기댓값을 계산했다면, MDP는 각 state마다 수행하는 action에 따라 받을 수 있는 return의 기댓값을 Action-value function이라 한다.
- Action

- Policy
- Action-value function
- : set of states
- : set of actions
- : state transition probability
- : Reward function
- : Discounting Factor
- Action
Model-Free vs Model-based
- RL 알고리즘을 분류하는 첫번째 조건은 Model의 존재 여부이다. Model을 갖는다는 것은 장단점을 가지는데, 장점으로는 Planning이 가능하다는 것이다. 즉, agent의 action에 따라서, environment가 어떻게 변할지 안다면, action을 취하기 전에 미리 변화를 예측해, 최적의 action을 계획해서 실행하므로, 훨씬 효율적으로 행동이 가능하다. 하지만, 단점으로는 현실세계에서는 environment의 정확한 model을 알아내기 힘들다는 것이다. Model이 만약 environment를 정확히 반영하지 않는다면, model의 오류가 agent의 오류로 이어지므로, 문제가 발생하기 쉽다. 그래서, 이런 Model을 사용하는 것이 Model-based, Model을 사용하지 않는 방식이 Model-free라고 불린다.
Value-Based vs. Policy-Based
- RL 알고리즘을 분류하는 두번째 조건은 Value function과 Policy의 사용여부이다.
- Value-Based
- Value function이 완벽하다면, 가장 높은 value를 주는 action을 하는 Policy를 가지면 되므로, Value function만 학습하는 알고리즘을 의미한다.
- DQN 등이 여기에 해당한다.
- Policy-Based
- Policy가 완벽하다면, 최적의 policy를 뽑아내기 위한 value function은 필요 없으므로, policy만 학습하는 알고리즘을 의미한다.
- Policy Gradient가 여기에 해당한다.
- Value-Based
