[논문 리뷰] Safety-Enhanced Autonomous Driving Using Interpretable Sensor Fusion Transformer(InterFuser)
Introduction
연구 배경
-
기존 자율주행의 문제 ⇒ safety(High-traffic-density 상황에서 성능 저하)
- Lack of comprehensive scene understanding
- 신호위반 차량, 보행자가 갑자기 등장하는 상황 등에 취약
- Lack of interpretability
- Lack of comprehensive scene understanding
-
InterFuser
- multi-modal, multi-view 센서들로 부터 정보를 혼합해서 comprehensive scene understanding을 해결하였다.
- intermediate interpretable feature를 생성해 interpretability를 해결하였다.
Comprehensive scene understanding
- Single-modal
- Single Image ⇒ 주변의 복잡한 상황을 받아오기 힘듦
- Single LiDAR ⇒ traffic Light와 같은 Semantic Information을 받아오기 힘듦
- Fusing multiple sensors
-
Match geometric features between Image & LiDAR
- By locality assumption
-
Simply concatenate multiple-sensor features
⇒ But, 이러한 multi-modal feature 사이의 interaction은 모델링 되기 어려움
-
- Transformer
- Feature 사이의 interaction을 파악하기는 어려우므로, global context를 고려하기 위해 Attention Mechanism이 사용됨
- Ex) TransFuser : transformer를 통해 Image, LiDAR input을 혼합하는 구조를 설계 ⇒ But, Sensor scalability에 좋지 않고, LiDAR & Single Image 혼합에 한정되어 있다.
- Ex) TransFuser : transformer를 통해 Image, LiDAR input을 혼합하는 구조를 설계 ⇒ But, Sensor scalability에 좋지 않고, LiDAR & Single Image 혼합에 한정되어 있다.
- InterFuser는 one-stage architecture를 통해 Multi-view sensor들의 Input을 혼합했다.
- LiDAR Input & Multi-view Images(Left, Front, Right, Focus)
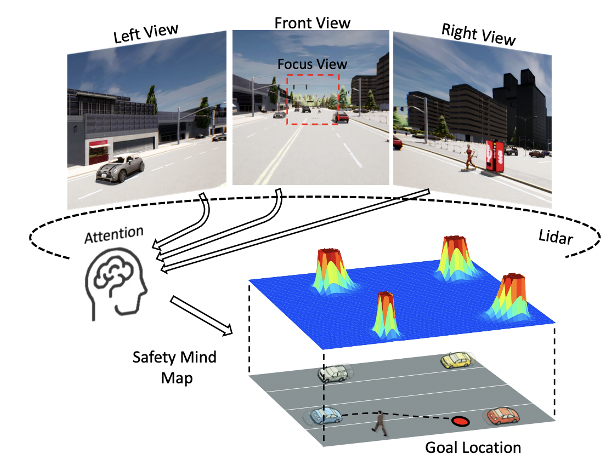
- LiDAR Input & Multi-view Images(Left, Front, Right, Focus)
- Feature 사이의 interaction을 파악하기는 어려우므로, global context를 고려하기 위해 Attention Mechanism이 사용됨
Interpretability
- Existing method
- 실패했을 때, 모델을 직접적으로 이해하기 보다는 neural network가 적용되는 부분을 확인하려 했다. ⇒ Lack feedback from the failure
- 실패했을 때, 모델을 직접적으로 이해하기 보다는 neural network가 적용되는 부분을 확인하려 했다. ⇒ Lack feedback from the failure
- New method
- 사람의 정보 습득 방식에서 착안해서, Generating action 뿐만 아니라, Safety mind map 또한 출력했다.
- Intermediate Interpretable features ⇒ Information on surrounding objects and traffic signs
- Intermediate Interpretable features ⇒ Information on surrounding objects and traffic signs
- 사람의 정보 습득 방식에서 착안해서, Generating action 뿐만 아니라, Safety mind map 또한 출력했다.
Contribution
- Transformer를 통해 different modalities and views에서 global contextual perception을 가능하게 했다.
- Safety and Interpretability 향상
- intermediate feature of the model
- constraining actions within safe sets
- CARLA benchmark에서 SOTA를 달성
Method
Architecture
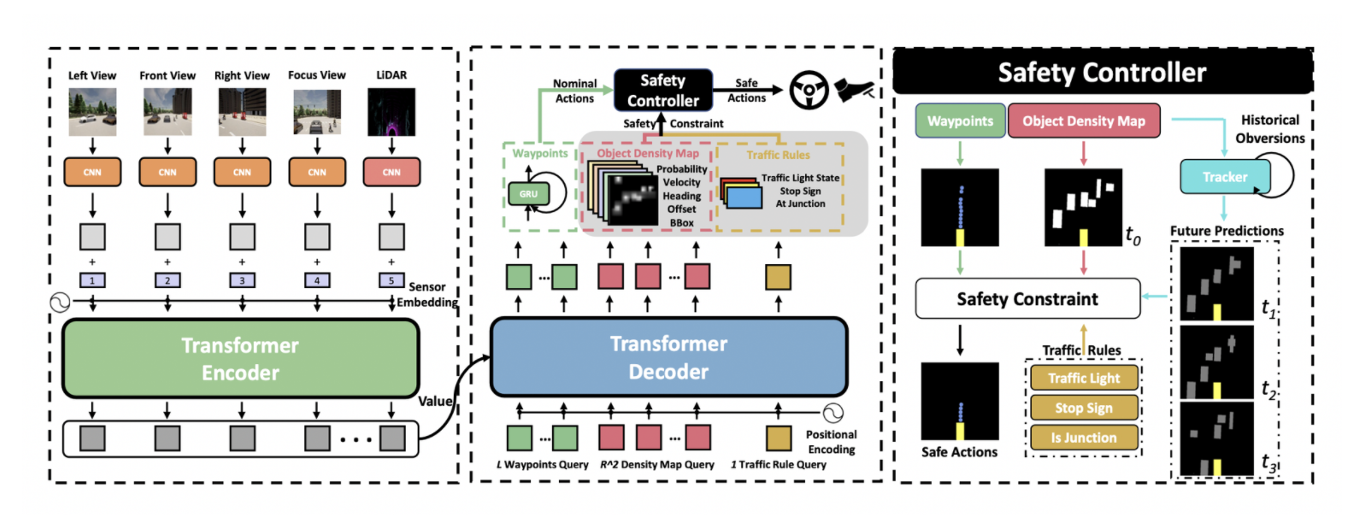
- Transformer encoder
- integrates the signals from multiple RGB cameras and LiDAR
- transformer decoder
- low level action
- intermediate feature ⇒ ego vehicle’s future trajectory, object density map, traffic rule signal
- safety controller
- utilize the interpretable features to constrain the low-level control within the safe set
Input and Output Representations
Input representations
-
Four image inputs
-
{}
- 3개의 RGB camera로 부터 left, front, right image input을 받아온다.

- 3개의 RGB camera로 부터 left, front, right image input을 받아온다.
-
- traffic light의 상태를 받아오기 위해 front RGB image에서 center 부분을 crop해서 받아온다.
-
-
LiDAR point clouds
- TransFuser 논문과 같은 방법으로 point cloud data를 two-channel bird-eye view projection image로 나타낸다. ⇒
 => TransFuser 논문의 그림
=> TransFuser 논문의 그림
- TransFuser 논문과 같은 방법으로 point cloud data를 two-channel bird-eye view projection image로 나타낸다. ⇒
Output representations
-
safety-insensitive output
- ego vehicle이 이동하려는 waypoints
-
safety-sensitive output
-
object density map
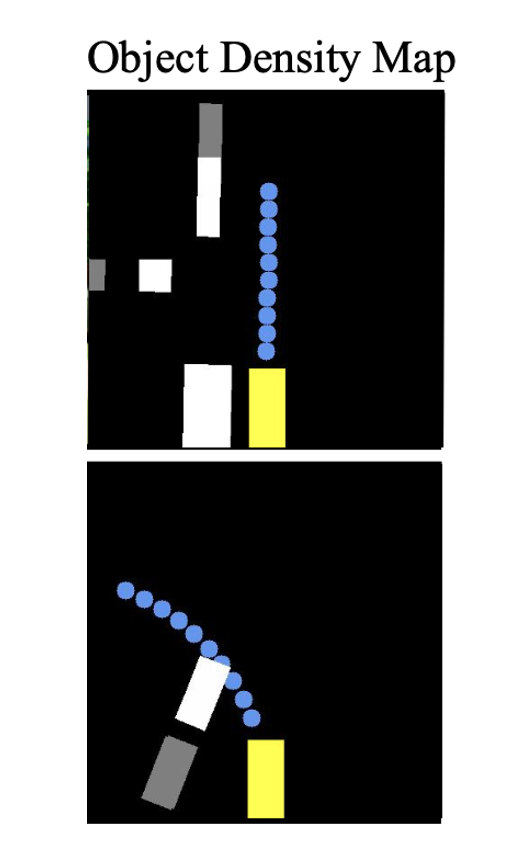
- ⇒ 7 features for potential objects in each grid cell
- ego vehicle로 부터 meter, 좌우로 각각 meter씩 나타낸다.
- 7 channel
- 각 grid cell에 object가 존재할 확률
- 2-dimensional offset from the center of the grid
- 2-dimensional bounding box
- object heading
- object velocity
-
traffic rule information
- traffic light status
- stop sign
- intersection
-
Model architecture
Backbone
- Input :
- ResNet Backbone ⇒ ( → )
- C = 2048
- (H, W) = ()
Transformer encoder
- Feature map 에 대해 1x1 convolution을 수행해 low-channel feature map 를 얻는다.
- 의 spatial dimension을 one dimension으로 나타내어 로 나타낸다.
- Fixed 2D sinusoidal positional encoding 를 더해 각 token이 positional information을 갖도록 한다.
- 학습가능한 sensor embedding 을 더해 각 token이 N개의 sensor들을 구분하도록 한다.
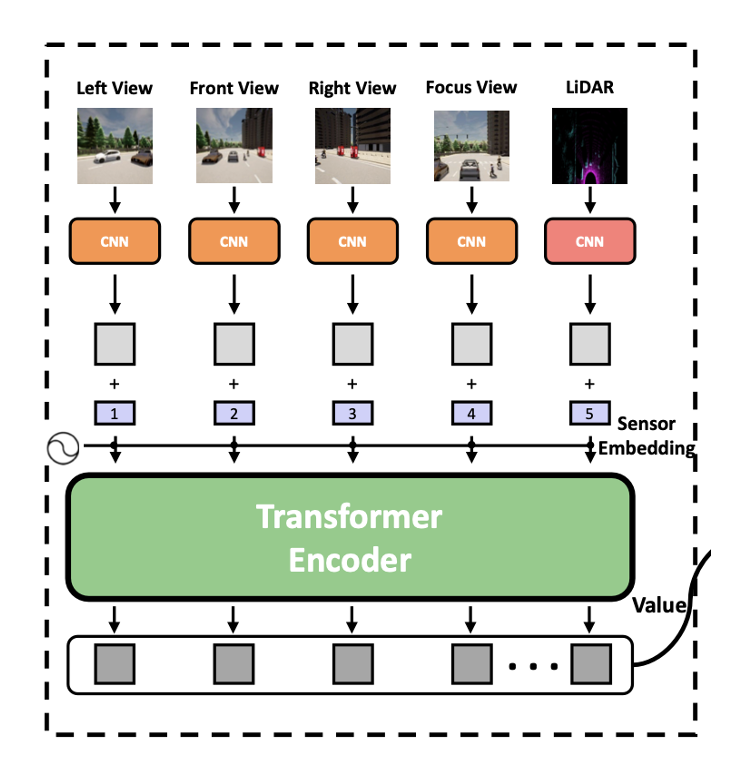
- 각 sensor에 대해 다음의 과정을 거친 후에, 각 sensor들의 output을 concat하고, 개의 transformer layer를 거친다.
- Each layer 는 MSA, MLP, LM으로 구성되어 있다.
Transformer decoder
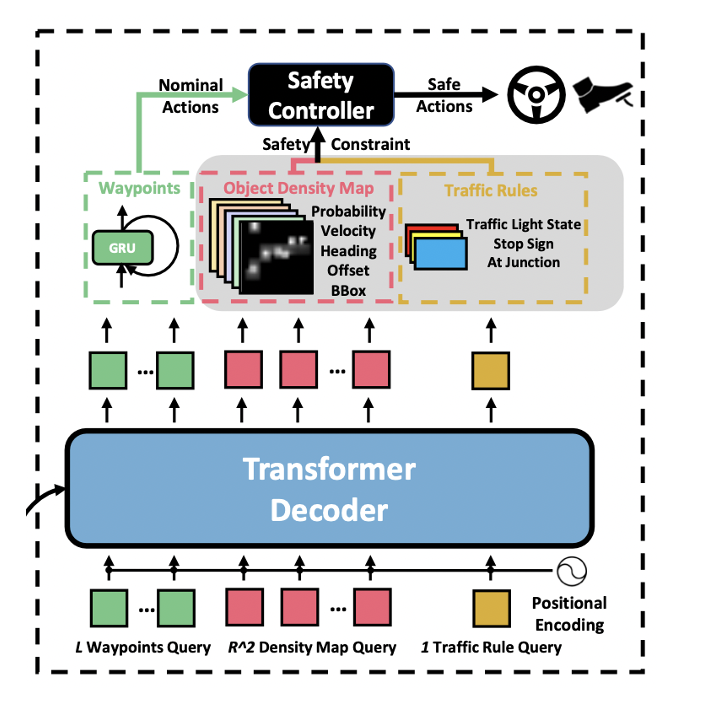
- standard transformer architecture
- Three types of queries
- waypoints queries
- density map queries
- one traffic rule query
- Transformer decoder는 permutation-invariant하므로, query embedding이 decoder마다 동일하다.
- permutation-invariant ⇒ 입력 벡터 요소의 순서와 상관없이 같은 출력을 생성하는 모델
- learnable positional embedding이 이 query embedding에 더해진다.
Prediction headers
- Three parallel prediction modules
- Waypoints prediction
- single layer GRU ⇒ auto-regressively predict waypoints
- GPS 좌표로 생성된 goal location을 64-dimensional vector로 만들어 초기 hidden state를 초기화 한다.
- Object density map prediction
- 3-layer MLP를 거쳐 ( ⇒ )의 형태로 feature map을 변화시키고, 의 형태로 reshape 한다.
- 3-layer MLP를 거쳐 ( ⇒ )의 형태로 feature map을 변화시키고, 의 형태로 reshape 한다.
- Traffic rule prediction
- single linear layer를 통해 traffic light, stop sign, intersection을 예측한다.
- Waypoints prediction
Loss Function
-
-
⇒ Waypoint prediction loss function
- ⇒ by L1 loss
-
⇒ Object density map prediction loss function
-
-
⇒ Traffic rule prediction loss function
- ⇒ by cross-entropy loss
- : traffic light status
- : stop sign
- : junction of roads(intersection)
- ⇒ by cross-entropy loss
-
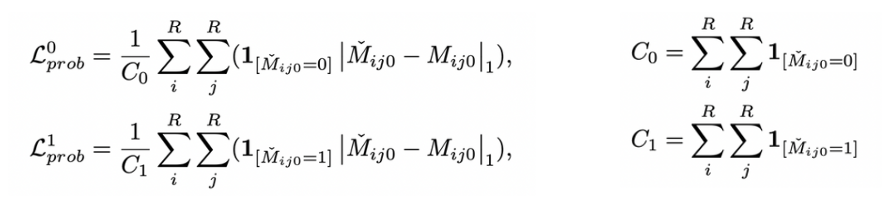
Safety Controller
Low-level action
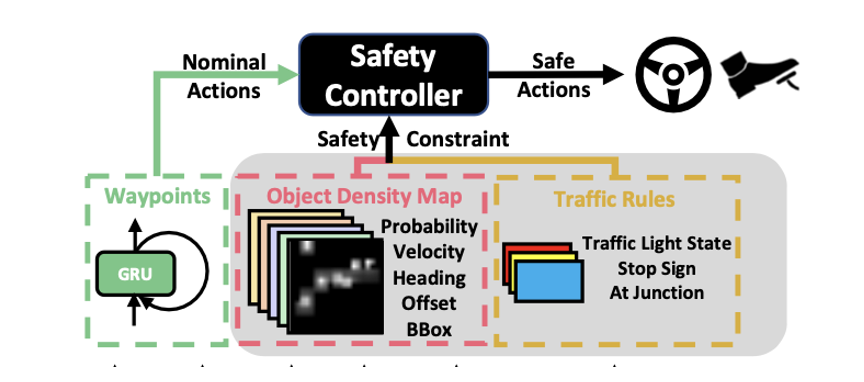
- Transformer decoder와 waypoint predictor로 부터 생성된 waypoints는 PID controller에 의해 two low-level action으로 변환된다.
- lateral steering action
- ⇒ ego vehicle’s desired heading
- longitudinal acceleration action
- ⇒ desired speed
- lateral steering action
- Low-level actions는 interpretable feature(object density map, traffic rule)에 의해 safe set에 부합하도록 조정된다.
Object density map
-
Object existence probability
- surrounding grid에서 existence probability의 local maximum이 threshold보다 높은 경우 object가 있다고 판단한다.
-
Tracker
- historical dynamic을 기록해서 future trajectory를 moving average로 판단한다.
⇒ 주변 환경과 object가 어떻게 이동할지 예측해서 ego-vehicle이 이동 가능한 safe distance()를 구한다.
Traffic rule
- 예측된 traffic rule 또한 safe driving에 이용된다.
- traffic light not green, stop sign ⇒ emergency stop
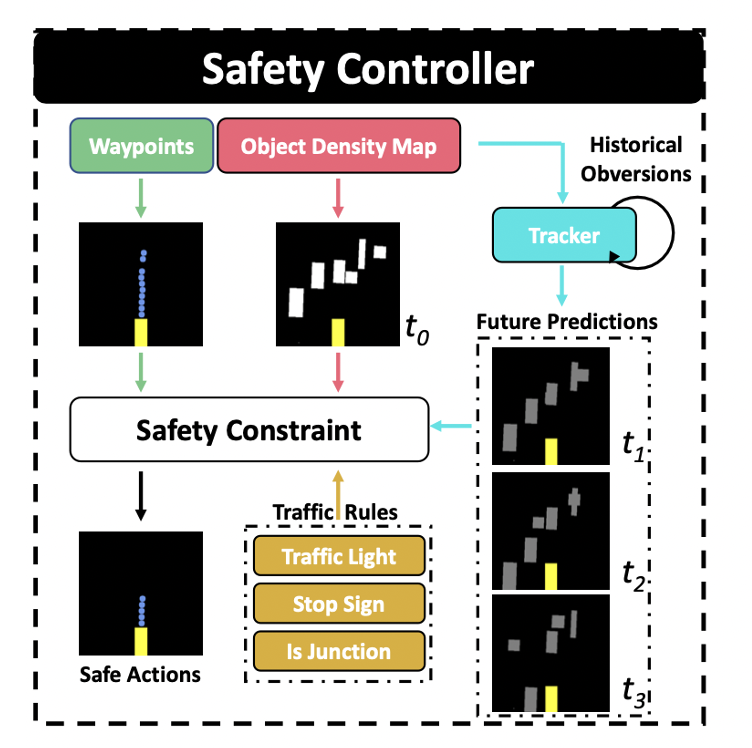
- traffic light not green, stop sign ⇒ emergency stop
Experiments
Experiment Setup
- CARLA simulator (8 towns and 21 kinds of weather)
Data collection
- 8 kinds of towns and weather
- Randomly generated different routes, dynamic objects, adversarial scenarios ⇒ for the diversity of the dataset
Metrics
- RC ⇒ Route completion ratio
- IS ⇒ Infraction score
- DS ⇒ Driving score
Comparison to the state of the art
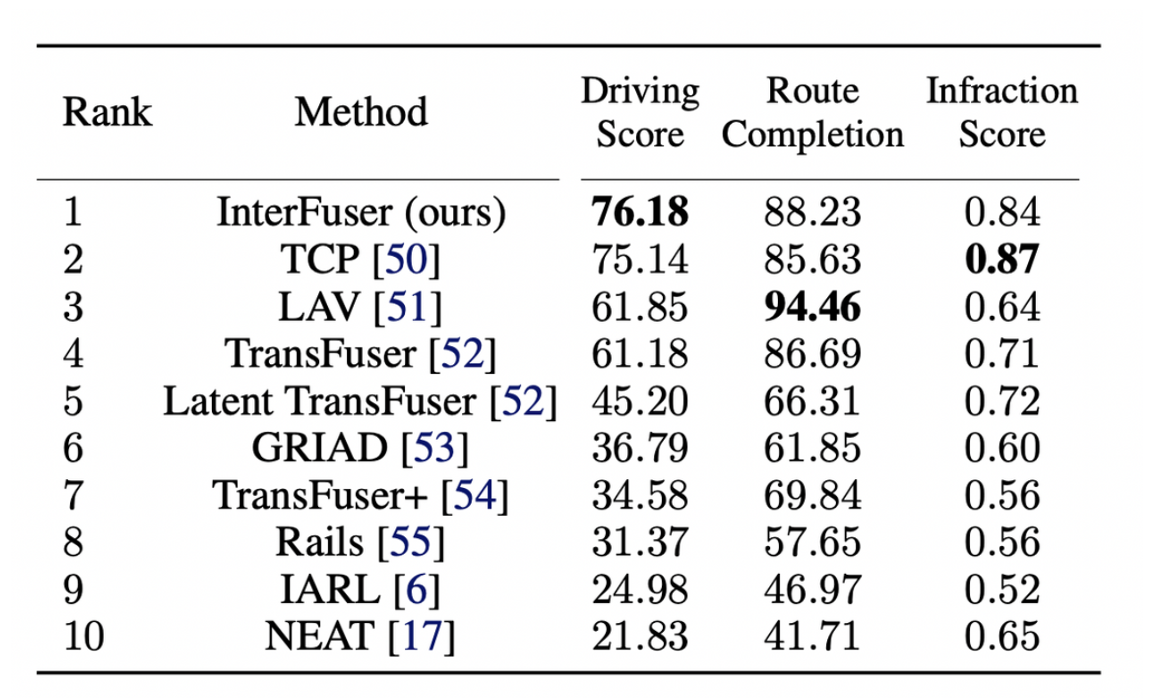
- TCP : integrate trajectory planning and direct control
- Use one camera
- LAV : dataset collected from all the vehicles that it observes
