[논문 리뷰] Multi-task Learning with Attention for End-to-end Autonomous Driving
1. Introduction
E2E driving에서 Existing method의 한계
- unobserved environment에 대해 정확한 결정을 내리기 어렵다.
- untrained urban area, weather condition, traffic congestion
- Network가 얼마나 safety-critical visual input을 얼마나 잘 인식하는지가 중요하다.
New method
- Visual recognition sub task 또한 학습시키는 것이 unobserved environment에 대해 정확한 결정을 내리도록 한다.
- semantic segmentation, depth estimation, traffic light classification task
- Attention mechanism을 통해 salient region에 focusing 하도록 한다.
Contribution
- E2E driving 기반의 새로운 multi-task attention aware network를 제안했다.
- CARLA에서 기존 SOTA 결과보다 좋은 결과를 냈다.
- Traffic Light Infraction Analysis를 추가로 수행하여 신호등을 처리하는 New Method의 효율성을 정량적으로 보여줬다.
2. Background
Conditional Imitation Learning
- Imitation Learning
- learning policy 를 정해서 expert behavior 을 따라하도록 학습시키는 것
- Conditional Imitation Learning
Multi-task deep learning
-
Multi-task deep learning이란?
-
하나의 모델을 이용해서 다양한 task를 처리하기 위해 사용하는 것
- task들이 모두 개별적으로 동작하지 않음
-
task가 서로 연관되어 있다면, 전체적인 성능이 향상될 수 있음
- 장점
- one forward propagation
- one backpropagation
- lower parameter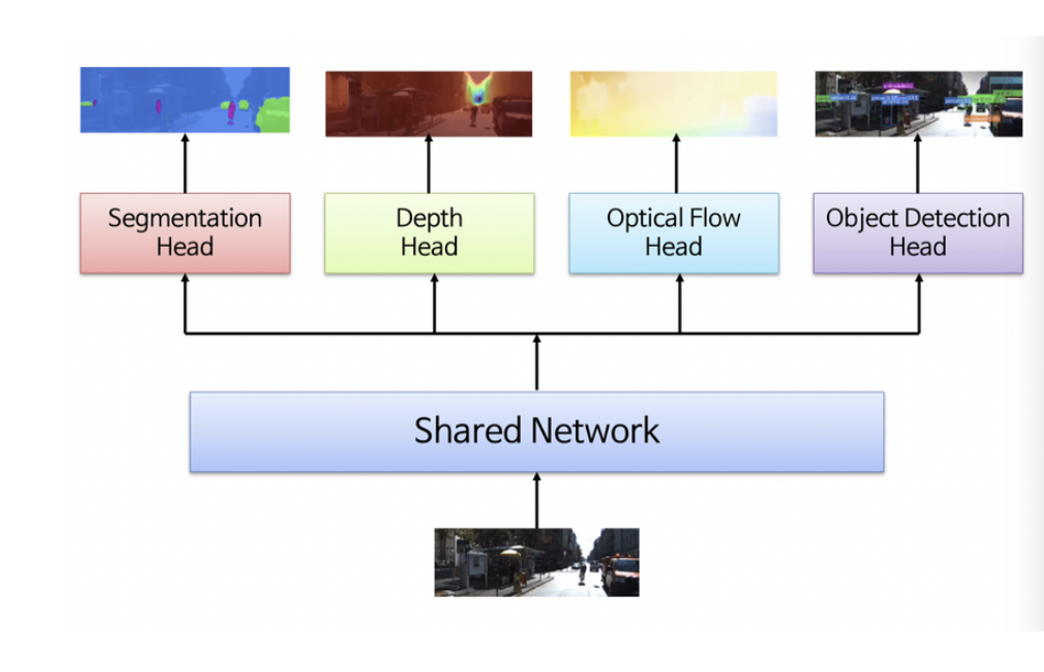
-
그림과 같이 shared network를 통해 공통 feature를 추출하고, 분기별로 각 task를 해결하도록 추가 학습하는 구조를 가짐
-
Challenge
- task별 데이터셋 크기가 다를 때
- task별 학습 난이도가 서로 다를 때
- Loss function 설계가 필요
- Fine Tuning을 할 경우
-
Attention in vision model
- Attention : 인간의 시각적 집중현상을 구현한 mechanism
SENet
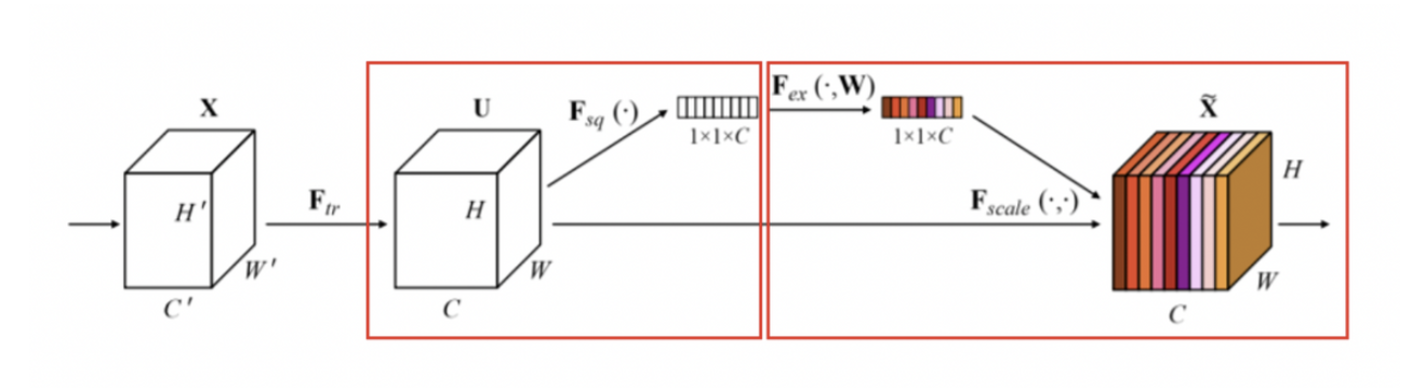
- Squeeze operation
- Feature map 는 각 채널마다 다르게 학습된 filter들로 부터 생성된 feature map이므로, 목표하는 바 가 다르기 때문에 Global Average Pooling(GAP)을 통해 1x1xC로 압축한다. ⇒ feature map을 대표하는 벡터 형태로 변환
- Excitation operation
* Excitation operation을 통해 만들어진 1x1xC 벡터를 원래 feature map 에 곱해 어떤 채널에 집중할지 골라주는 역할을 한다.
CBAM
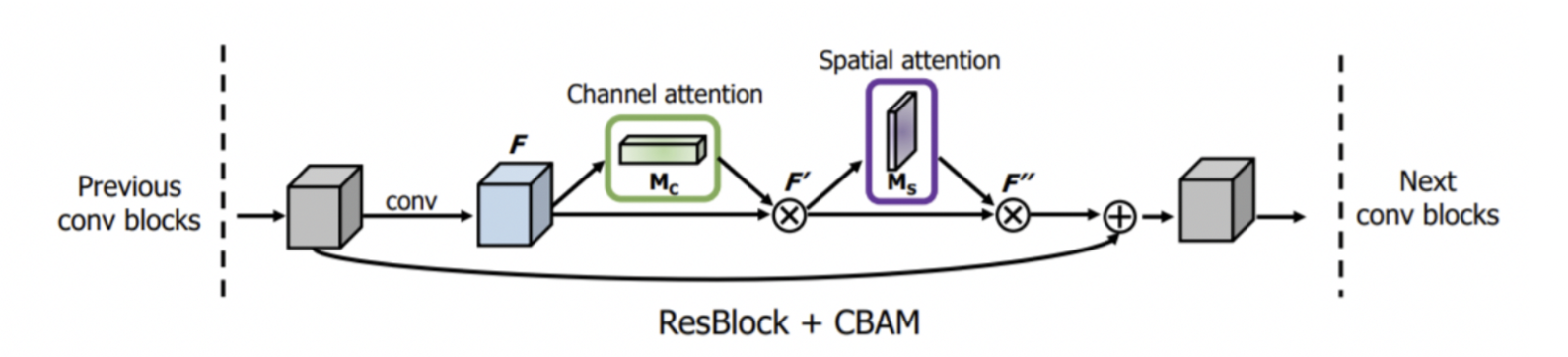
-
Channel Attention
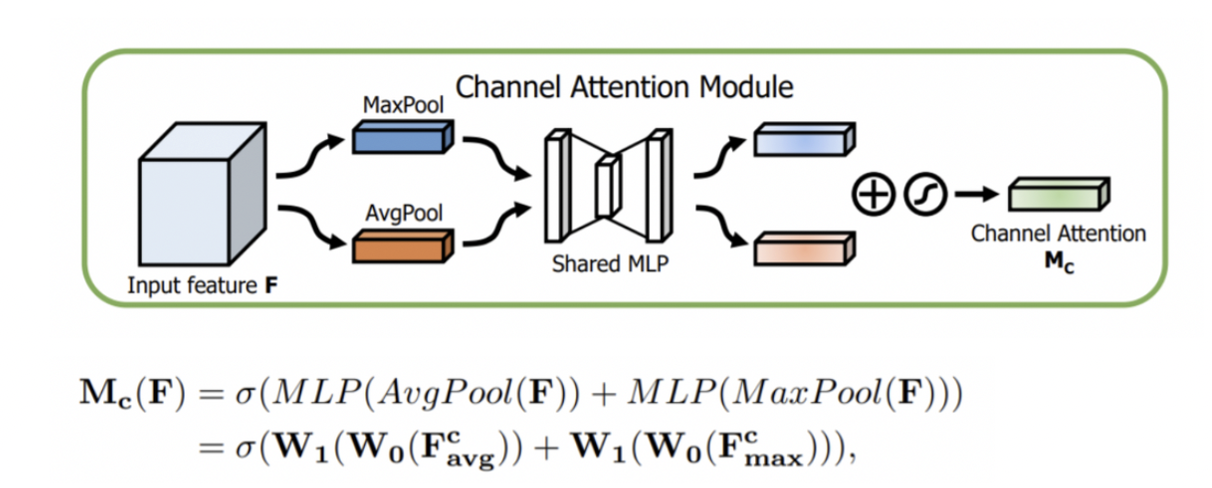
- SENet 처럼 channel간의 관계를 살펴 어떤 channel에 집중할지 판단한다.
- Spatial Attention
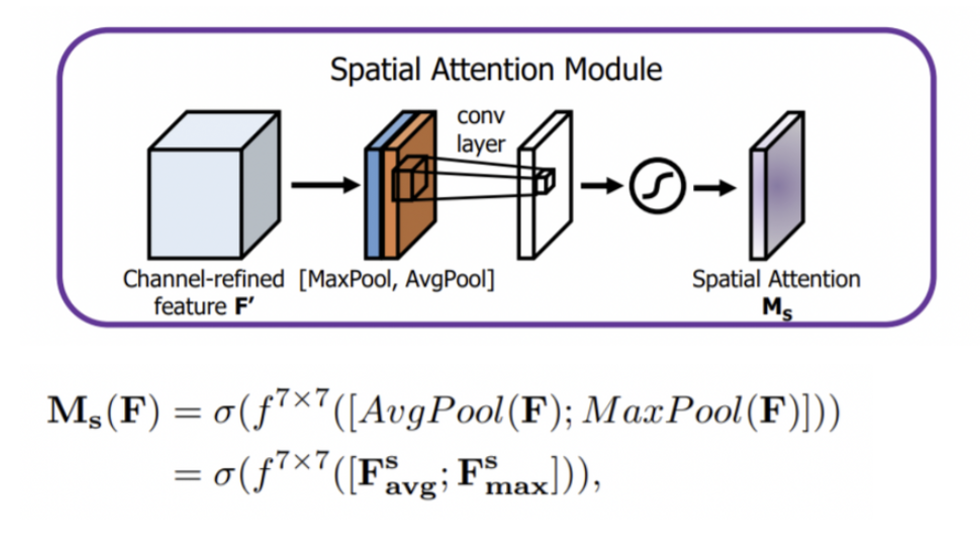
- H X W 개의 픽셀 중 어느 부위에 집중할지 인코딩하는 단계
3. Method
Network Architecture
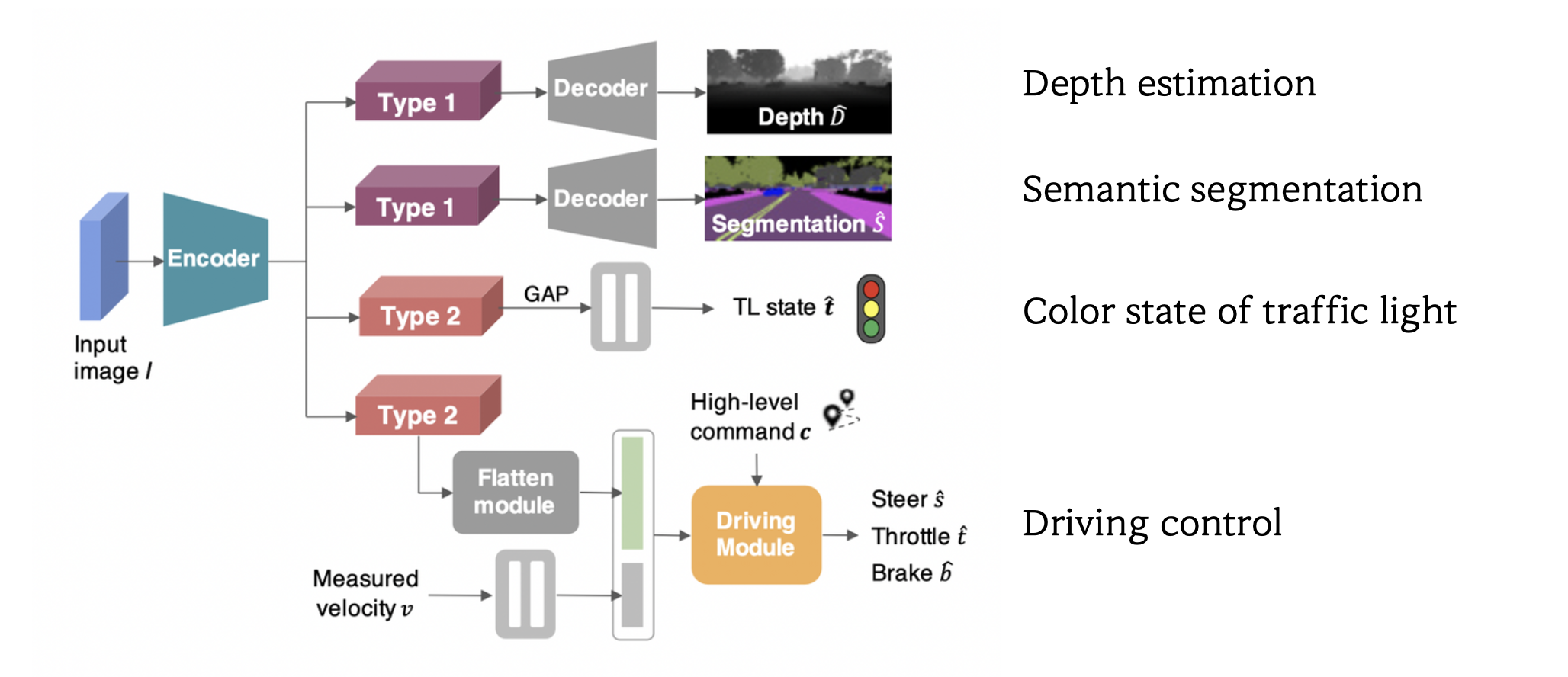
- Input
- Image from front-facing camera
- velocity
- high-level command ⇒ one-hot encoded vector(follow lane, turn left, turn right, go straight)
- Output
- main task
- control signal(steering : , throttle : , brake : )
- sub-task
- semantic segmentation :
- depth estimation :
- classification of the traffic light state : ⇒ one-hot vector(red, yellow, green, none)
- main task
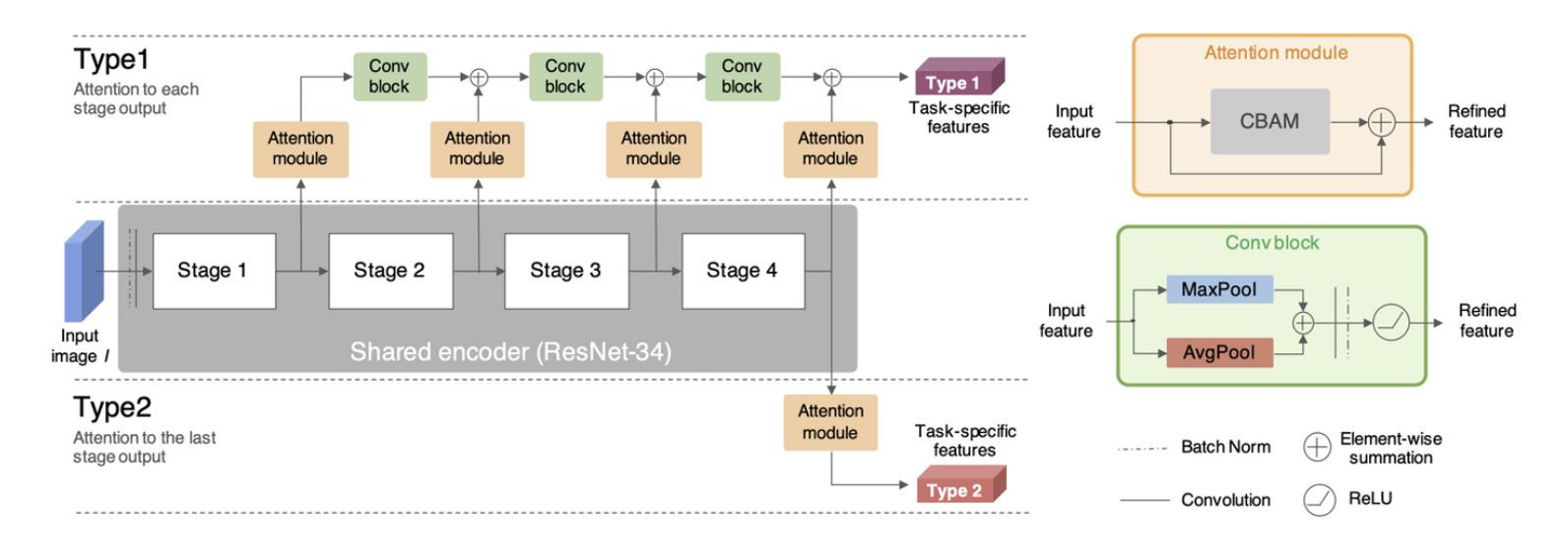
Residual network with attention
-
Type 1
- 각 ResNet stage가 끝날 때마다, feature map을 attention module과 convolution block을 통과시킨다.
- Attention module은 CBAM을 통해 생성된 attention value를 더해줘서 global feature map을 emphasize한다.
- For segmentation & depth estimation
- segmentation & depth estimation은 high resolution feature map에 접근하는 것이 필요하기 때문이다. ⇒ Like U-Net
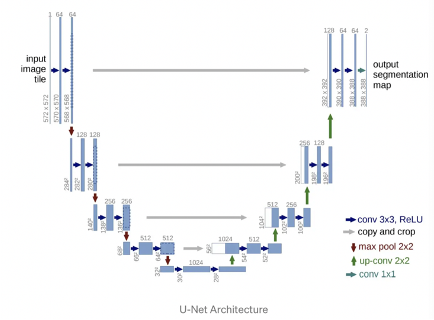
- segmentation & depth estimation은 high resolution feature map에 접근하는 것이 필요하기 때문이다. ⇒ Like U-Net
- 각 ResNet stage가 끝날 때마다, feature map을 attention module과 convolution block을 통과시킨다.
-
Type 2
- ResNet의 last layer로 부터 나온 feature map을 attention module을 통과시킨다.
- For traffic light classification & control command prediction
- require more abstract features in the hidden representation
Decoder Network
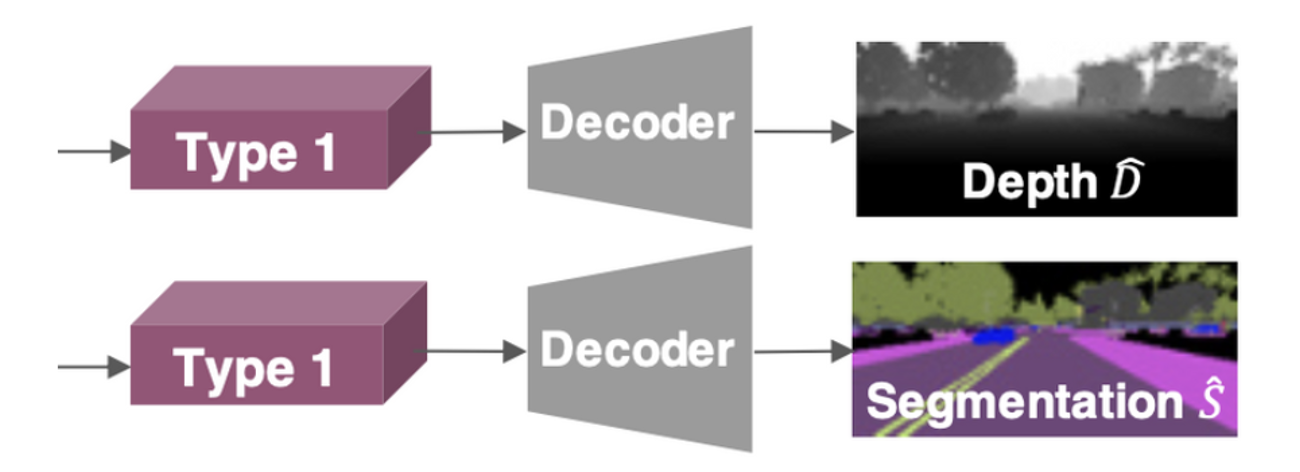
- Goal : control prediction을 위한 generalizable latent representation을 학습하는 것
- encoder가 feature map에 what, where, how far에 관한 정보를 담을 수 있도록 한다.
- Output : 384 x 160 resolution image (same with input)
Traffic Light classifier
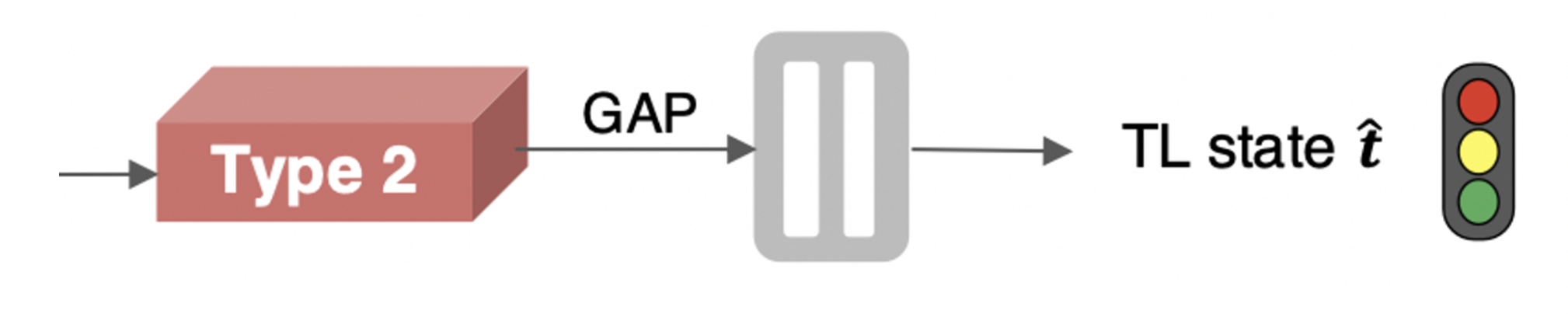
- Vision-based e2e driving approach로 traffic light에 반응하는 것은 아직 부족하다.
- traffic light를 보고 있는 상황에서, traffic light가 어떤 state인지 파악하는 sub-task가 필요하다. ⇒ Frame마다 traffic light state를 4가지 class로 분류한다.
- traffic light를 보고 있는 상황에서, traffic light가 어떤 state인지 파악하는 sub-task가 필요하다. ⇒ Frame마다 traffic light state를 4가지 class로 분류한다.
Driving module
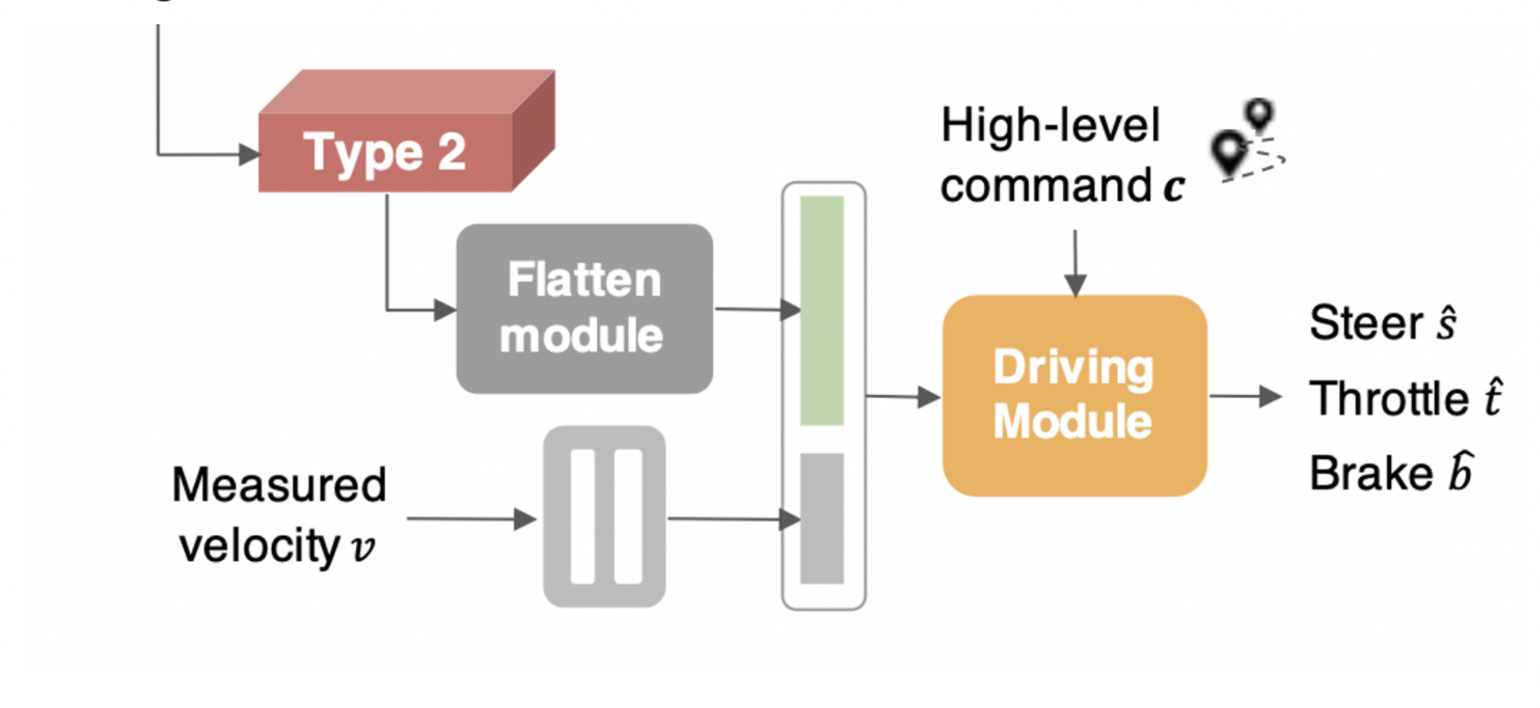
- Input
- Flattened feature map
- encoded velocity input
- high-level command
- Output
- control signal
-
⇒ by regression task
-
- control signal
- Branched prediction head
- Command input 에 따라서, control command를 예측할 때 필요한 branch가 결정된다.
Loss Function
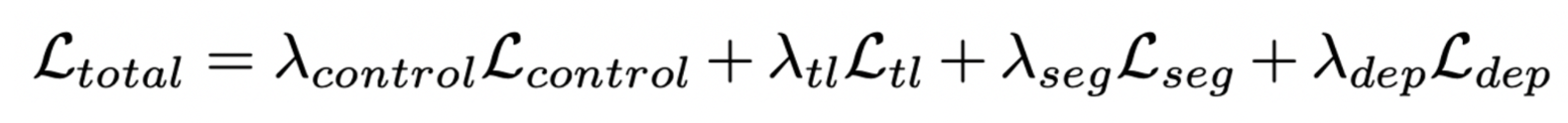
- Control regression loss
- c =1, 2, 3 ⇒ steering, throttle, brake
- Loss for traffic light classification
- class-weighted categorical cross-entropy losses
- Loss for traffic light classification
- Loss for segmentation
- class-weighted categorical cross-entropy losses
- Loss for segmentation
- Loss for depth estimation
- mean squared error
- Loss for depth estimation
4. Experiment
Environment and Dataset
- CARLA simulator ver 0.84
- Town01 for training, Town02 for testing
Dataset collection
- CARLA simulator ver 0.84
- Town01 for training, Town02 for testing
- Town01로 부터 466,000 frame
- 372,000 ⇒ training set
- 94,000 ⇒ validation set
- 각 frame마다 여러 input, output들이 포함되어 있다.
- Dataset은 4가지 다른 날씨 조건에서 수집되었다.
- ClearNoon, WetNoon, Hard Rain Noon, Clear Sunset
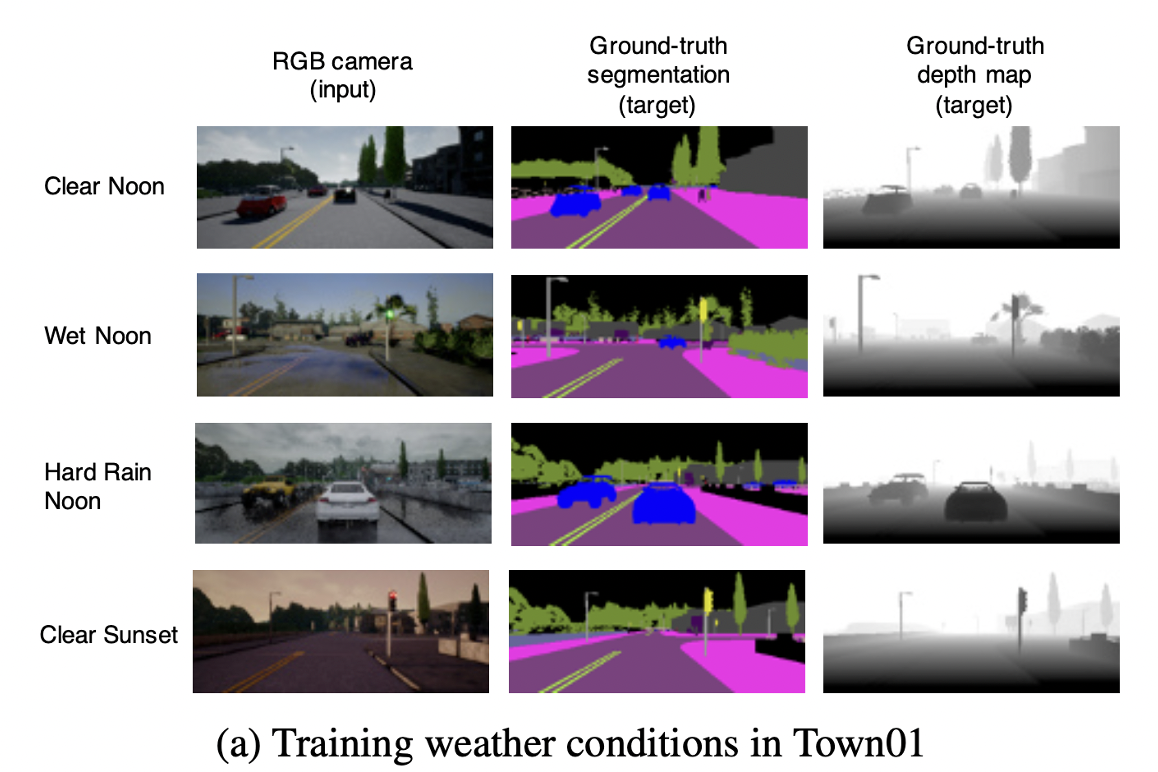
- ClearNoon, WetNoon, Hard Rain Noon, Clear Sunset
Data augmentation and balancing
- Augmentation
- Gaussian noise, blur, pixel dropout, contrast normalization
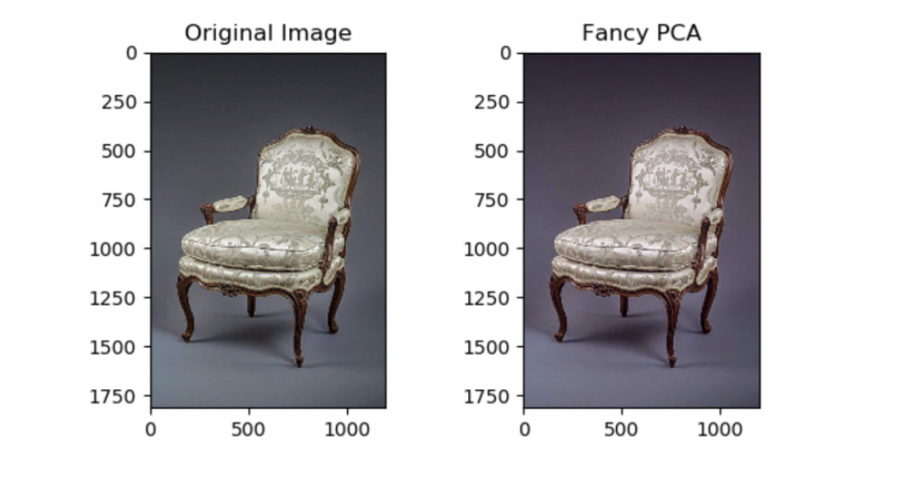
- PCA color augmentation
- PCA를 통해서 Color 채널을 변경한다. ⇒ 이미지의 중요한 특성은 유지하고, 학습하고자 하는 물체의 조명 강도나 색상을 변화시킨다.
- Balancing
- Driving dataset은 unbalanced distribution을 가진다.
- 예를 들어, dataset에서 직진 control이 대부분인 경우
- 이 unbalance를 해결하기 위해, steering value에 따라 undersampling을 했다. ⇒ 같은 제어 신호가 너무 많을 경우, training 때 skip 됨.
- Driving dataset은 unbalanced distribution을 가진다.
Experimental setup
- Starting point, Goal point를 정해 놓고 route planner로 global path를 계산
- 이 planner로 부터 high level command 를 매 frame마다 받아서 현재 position에서 어떻게 진행할지 예측
- 모든 evaluation trials은 다음 네가지의 상황에서 시행
- Training condition ⇒ 4 weathers, Town01
- New weather ⇒ 2 weathers, Town01
- New town ⇒ 4 weathers, Town02
- New town & weather ⇒ 2 weathers, Town02

Benchmark
- CoRL2017
- 4가지 driving condition으로 구성
- driving straight
- driving with one turn at an intersection
- full navigation with multiple turns at intersections
- The same full navigation but with dynamic obstacles
- But, 빨간불 신호등을 지나치는 것은 실패로 처리하지 않는다.
- lane-keeping과 목표지점에 도달하는 것에만 중점을 두고 디자인되었기 때문이다.
- 4가지 driving condition으로 구성
- NoCrash
- more complex scenario
- under 6 weather scenario
- difficulty level ⇒ full navigation with 3 traffic congestion
- empty town
- regular traffic
- dense traffic
- collision이 일정 threshold 이상이면 실패로 간주한다.
- 현실과 비슷하게 평가하기 위함
- traffic light violation도 평가에 포함되지만, 실패로 처리하지는 않는다.
- more complex scenario
Result(CoRL2017, success rate)
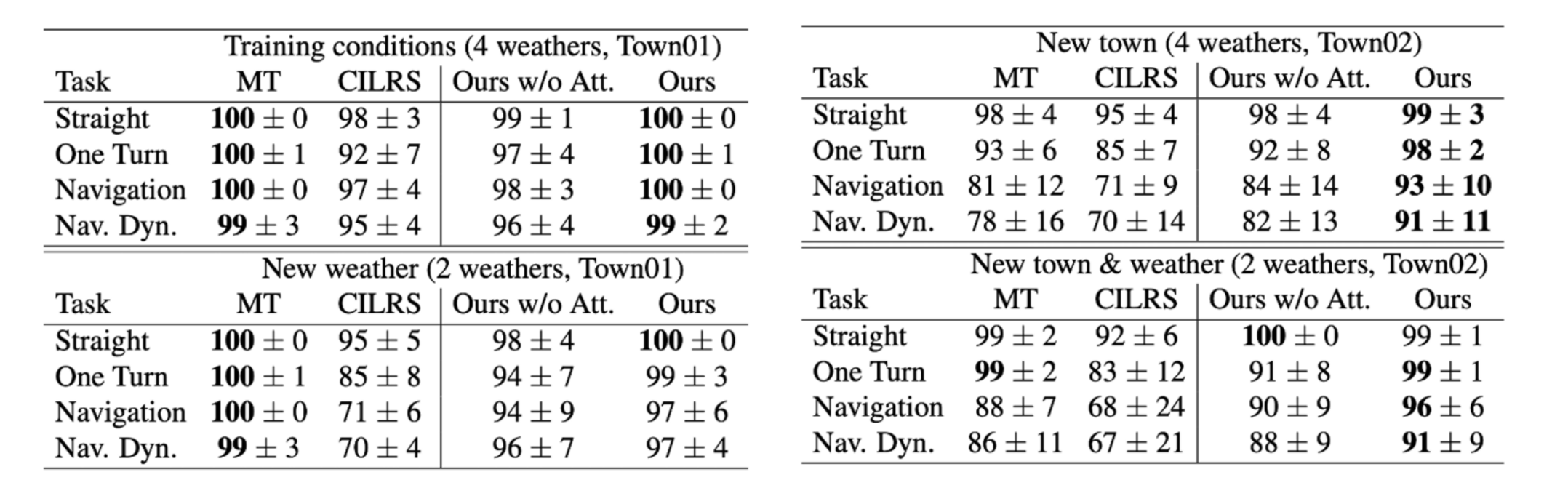
- 특히, New town, New town & weather과 같은 새로운 환경에서 좋은 성능을 보인다.
Result(CoRL2017, traffic light infraction)
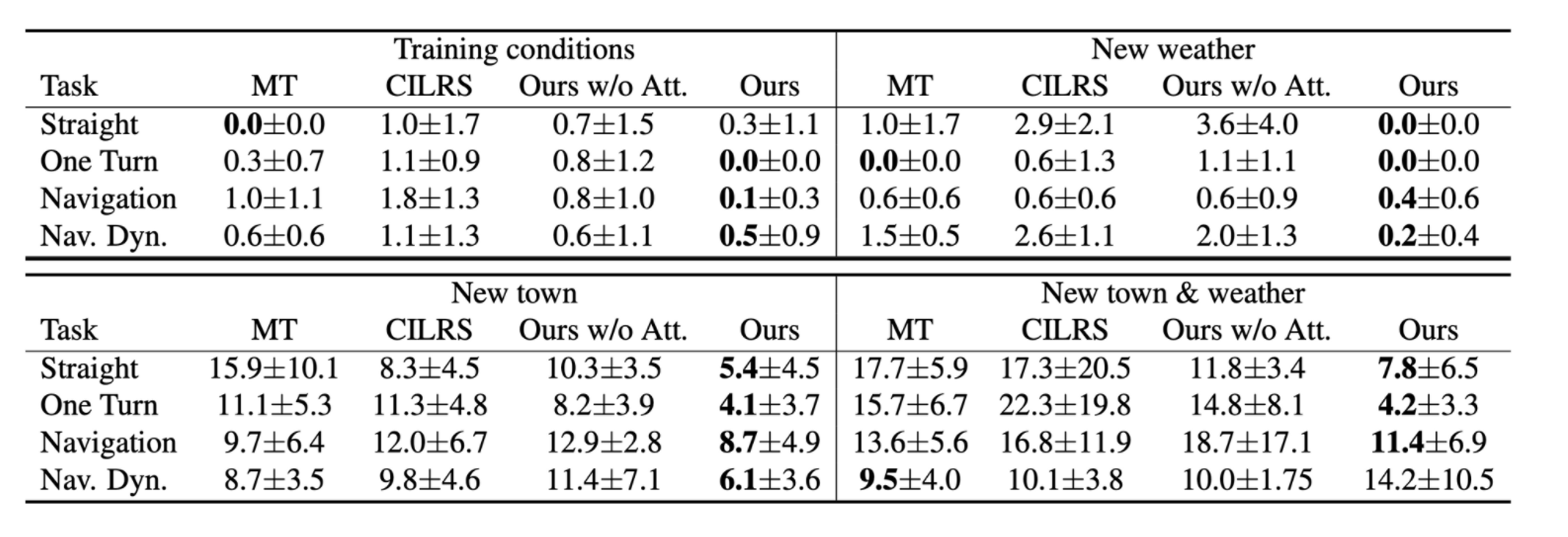
- 모든 조건에서 traffic light infraction에 관한 성능이 좋다.
Result(NoCrash, success rate)
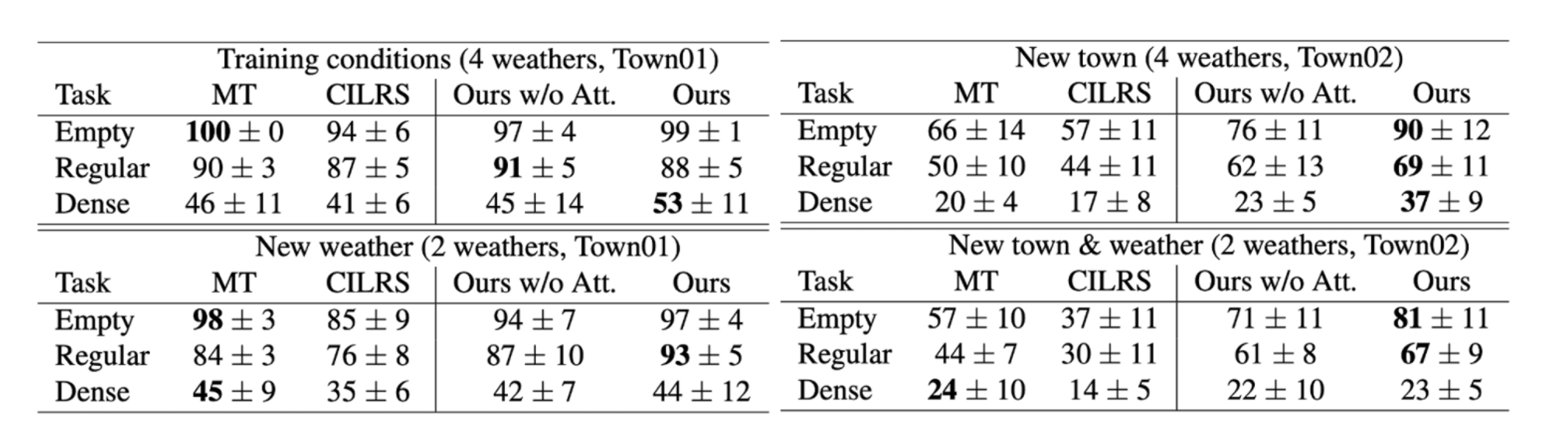
- CoRL2017과 마찬가지로 New town에서 성능이 다른 모델에 비해 좋다.
Result(NoCrash, traffic light infraction)
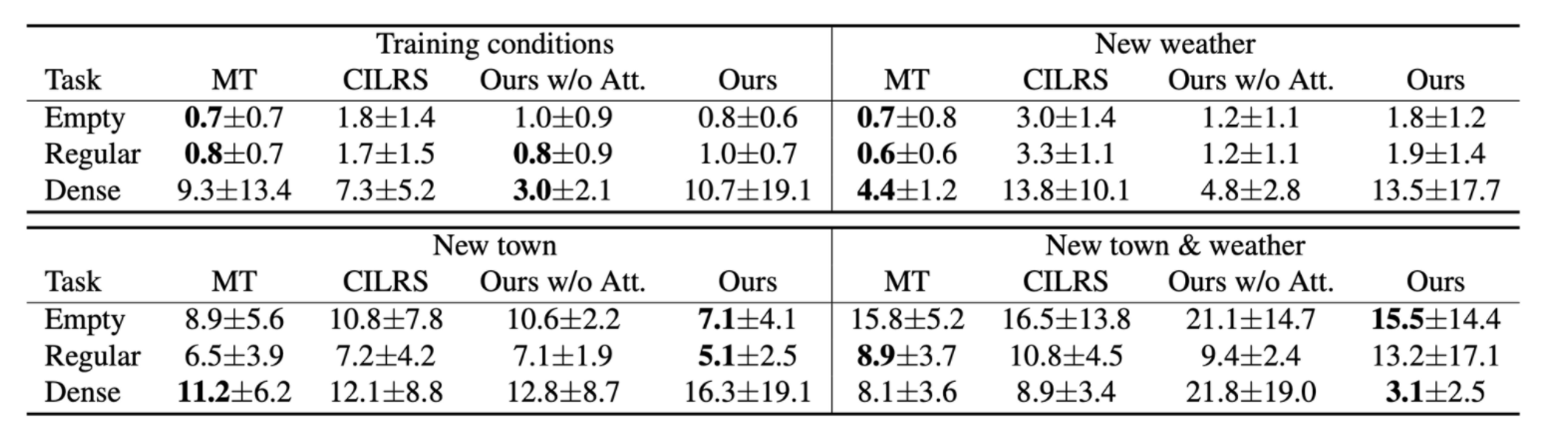
- NoCrash에는 New weather로 Wet Sunset과 같은 weather condition이 존재하기 때문에, New weather 상황에서 햇빛에 의해 input image가 가려지는 현상이 발생해 성능이 좋지 않다.
