[논문 리뷰] A Simple Framework for Contrastive Learning of Visual Representations (SimCLR)
Introduction
SimCLR는 contrastive learning으로 visual representation을 학습하기 위한 simple framework를 제안했다.
이 논문에서는 기존의 성능을 뛰어넘었을 뿐만 아니라, memory bank나 아키텍쳐를 특별히 변형시키지 않고, 좋은 성능을 냈다는 점이 중요하다.
논문의 contribution은 다음과 같다.
Contribution
- Composition of multiple data augmentation operations is crucial in defining the contrastive prediction tasks
⇒ data augmenation을 여러개 섞어서 하면 좋다.
- Introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations
⇒ representation을 non-linear projection을 통과시킨 후에 contrastive loss를 구하면 성능이 더 좋다.
- Representation learning with contrastive cross entropy loss benefits from normalized embeddings and an appropriately temperature parameter
⇒ loss를 구할때 l2 norm을 적용하고, 적절한 temperature parameter를 적용하면 좋다.
- Contrastive learning benefits from larger batch sizes and longer training
⇒ batch size와 training epoch을 크게하면 좋다.
Method
1. Contrastive Learning Framework
먼저 SimCLR에서 제시한 framework는 다음과 같다.
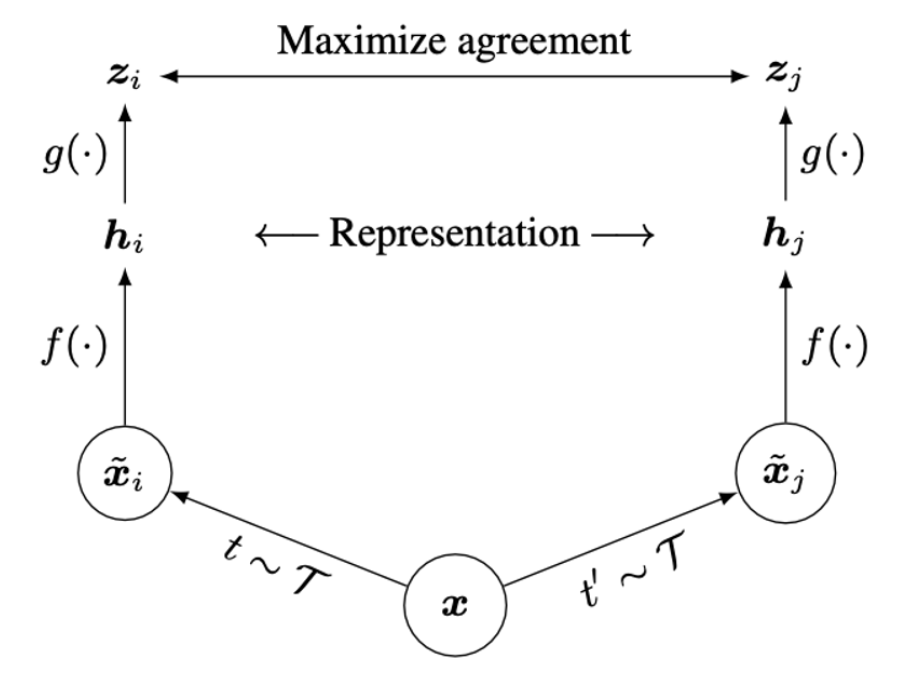
논문의 제목대로 상당히 simple한데, 말로 풀어서 설명하면,
이미지에 서로 다른 data augmentation 을 적용한 후에 각각을 encoder () 을 적용하면 각각 representation 를 얻을 수 있다.
그 이후에 representation을 projection ( ) 시켜서 사이의 contrastive loss를 통해 network를 학습하게 되는 것이다.
여기서 loss function은 논문에서 NT-Xent 라고 칭하는 loss를 사용하는데, 아래와 같다.
⇒ infoNCE loss와 다른 점은 모르겠는데, 왜 이름을 다르게 지은지는 모르겠다.
아무튼, 이러한 과정을 거쳐서 학습이 되는데, 이 과정을 pseudo code로 나타내면 아래와 같다.

2. Data Augmentation for Contrastive Representation Learning
Data augmentation은 supervised learning과 unsupervised representation learning 모두에서 널리 사용되어 왔는데, 기존의 Contrastive prediction task에서는 이에 대한 체계적인 방법은 없었다.
그래서 기존의 방법에서는 network architecture를 변형시킴으로써, 이를 수행해왔는데, 예를 들어, global-to-local view prediction을 위해서 network의 receptive field를 조절한다거나, neighboring view prediction을 위해서 context aggregation network를 사용하는 등의 방법을 사용해왔다.
하지만, SimCLR에서는 위 두가지를 간단히 random cropping으로 해결할 수 있음을 보여줬다.

Data augmentation의 효과에 대해 좀 더 체계적으로 파악하기 위해서 몇가지 augmentation을 꼽았는데, 다음과 같다.

또한, 이 augmentation들을 개별적으로 적용하거나, 조합하여 적용해서 성능을 뽑아봤을때, 아래와 같았다.
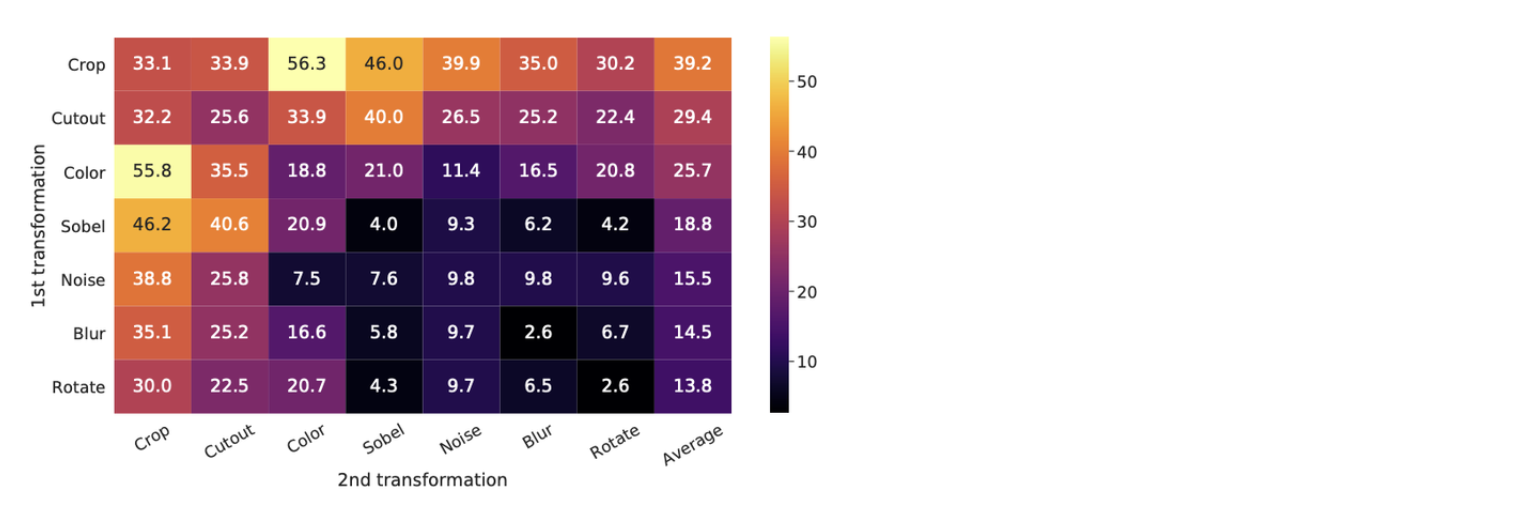
⇒ crop + color distortion의 성능이 가장 좋음을 알 수 있다.
또한, 대체로 augmentation을 단일로 적용한 경우보다 조합하여 적용한 경우에 성능이 높았음을 알 수 있다.
3. A nonlinear projection head imporves the representation quality of the layer before it
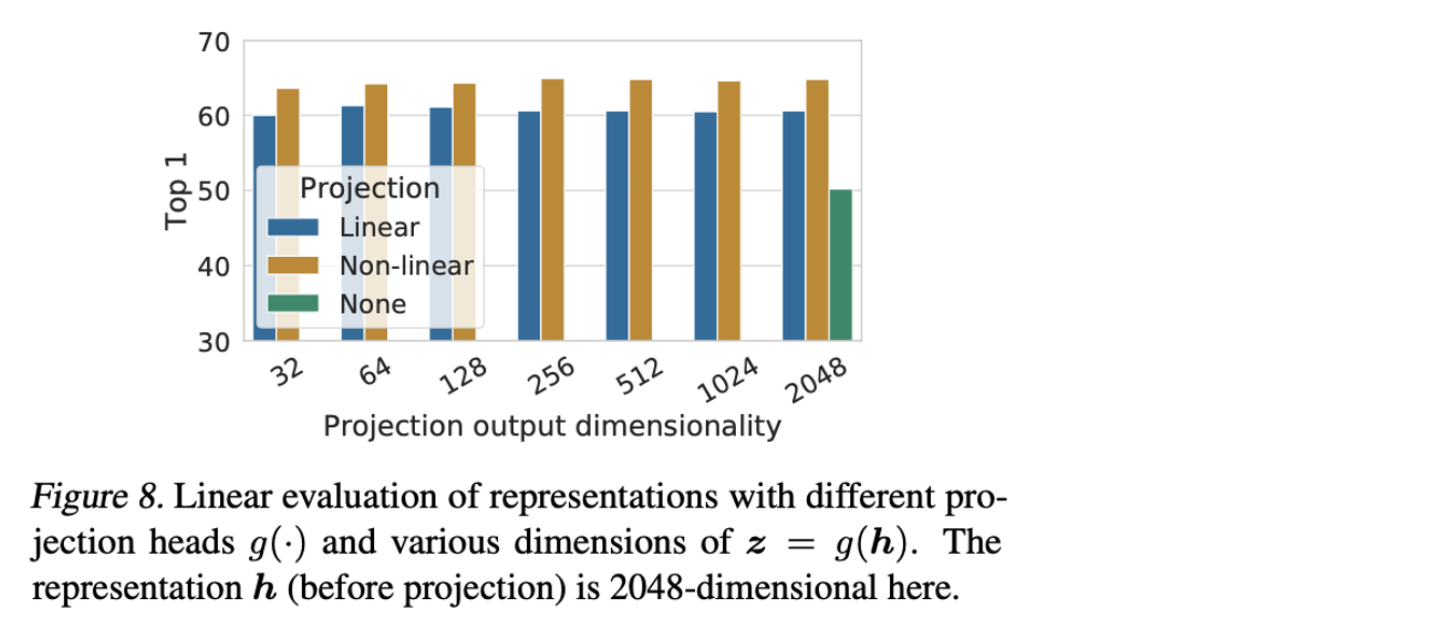
논문에서 위와 같이 을 통해 representation을 Linear, Non-linear projection을 적용하거나, 아무것도 적용하지 않았을 때, 성능을 뽑아봤는데, Non-linear projection을 적용했을 때, 성능이 높음을 알 수 있다.
하지만, downstream task에 적용할 때는 projection 후에 얻을 수 있는 보다 그 전에 얻는 representation 를 사용하는데, 그 이유는 논문에서 data augmentation을 통해서 가 data transformation에 invariant하도록 학습되므로, downstream task에 유용한 정보를 없앨 가능성이 있다고 한다.
실제로 실험 결과를 통해 representation 를 사용하는 이유를 밝히고 있다.

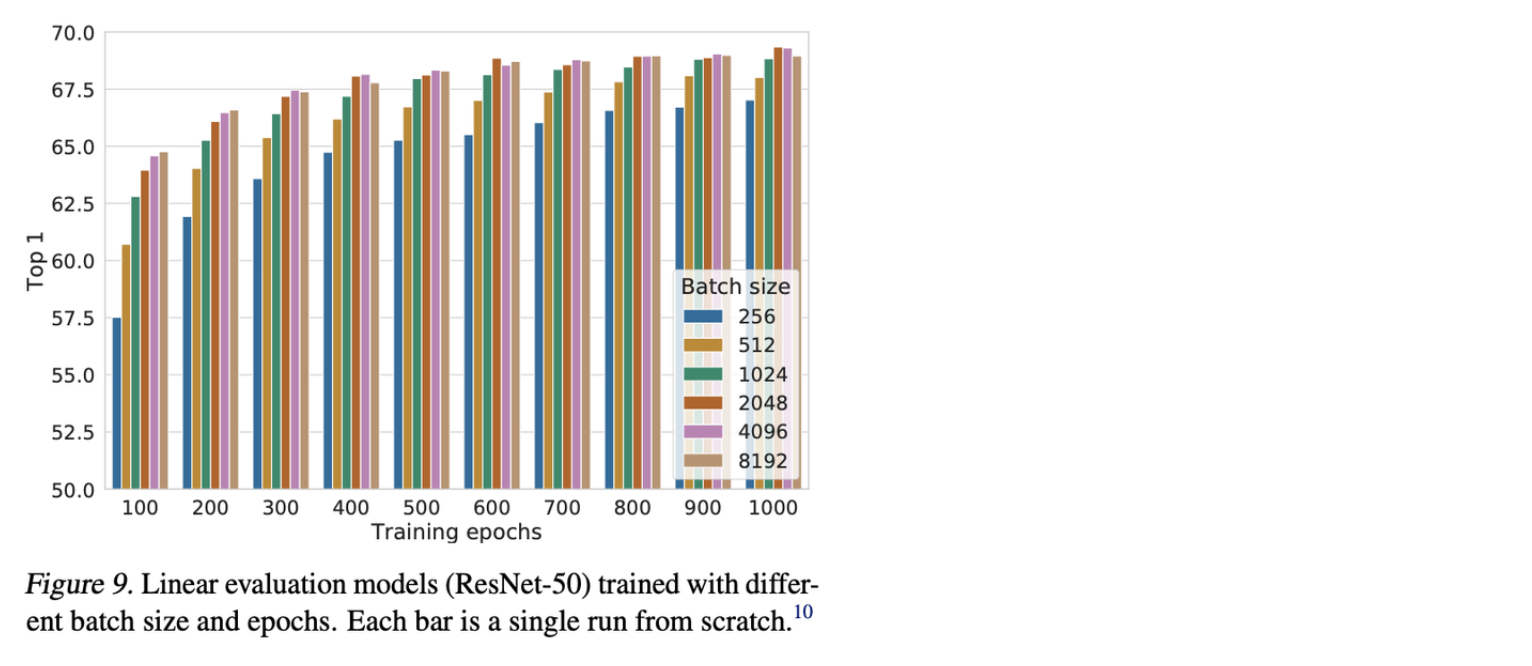
4. Contrastive learning benefits from larger batch sizes and longer training
Contrastive learning은 positive sample에 비해서 negative sample이 훨씬 많아야 학습이 잘 된다.
⇒ 그 이유는 unlabelled data이므로, 실제로 같은 class임에도 다른 Instance로 분류를 하는 경우가 있으므로, 이를 완화하기 위해서 많은 negative sample이 필요하다고 한다.
이를 SimCLR에서는 large batch size로 해결했는데, 실제로 batch size의 크기에 따른 성능 차이가 심하다.
⇒ 이게 이 논문의 한계점이다.
느낀점
논문에서 제시한 방법론들이 크게 참신하거나 새로운 메커니즘의 도입같은 것들은 없었고, 사실 negative sample이 많아야 학습이 잘된다는 점도 이미 이전에 언급되었고, 이 논문에서 제시한 프레임 워크도 이전 논문과 비슷하다.
하지만, SimCLR 논문을 실제로 읽어보면 실험 결과가 엄청 많은데, 이전 논문들과 달리, 실험 결과들로 세세한 것들까지 모두 보여주었다는 점에서 좋은 논문이 된 것 같다.
논문을 낼 때, 참신함에 집착할 필요는 없는 듯.

느낀점에 많이 공감됩니다 ㅎㅎ