[논문리뷰] Inter-Instance Similarity Modeling for Contrastive Learning
Introduction
-
기존의 Contrastive learning은 inter-instance similarity에 대해서는 신경쓰지 않아왔다.
예를 들어, 갈매기 이미지가 있다고 할때, 데이터셋에는 그 이미지 외에 갈매기와 비슷한 다른 조류들 이미지들도 있을 것이고, 다른 행동을 하고 있는 갈매기 이미지도 있을 것이다.
그런데, 기존의 방식에서는 그 이미지를 augmentation한 이미지만 positive sample로 정하고, 나머지는 negative sample로 정했다.
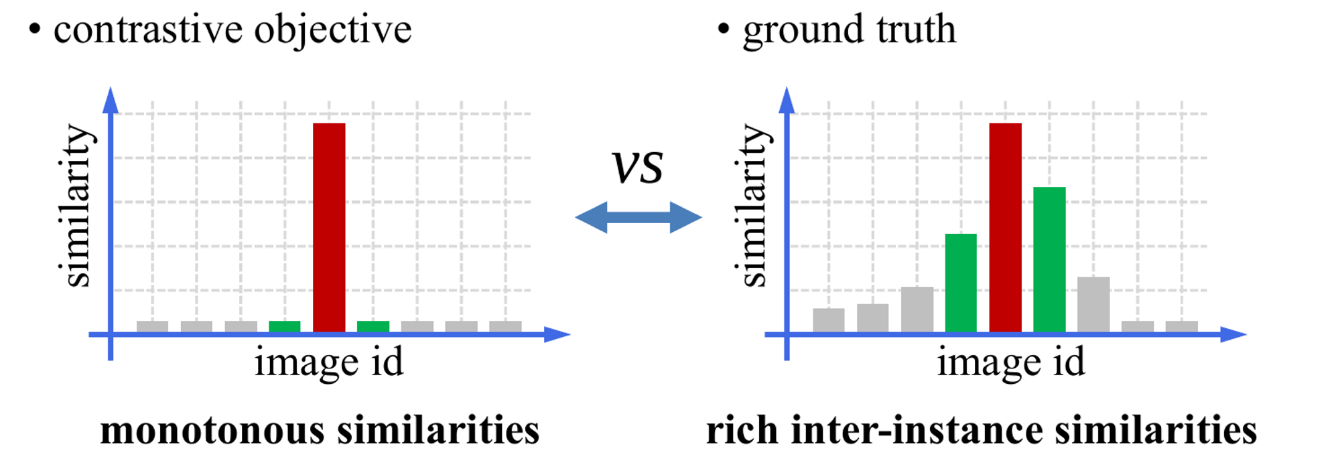
이러한 방식은 실제 상황과 부합하지 않으므로, 본 논문은 Inter-instance similarity에 대해서도 학습이 가능한 PatchMix 방식을 제안한다.
Method
PatchMix
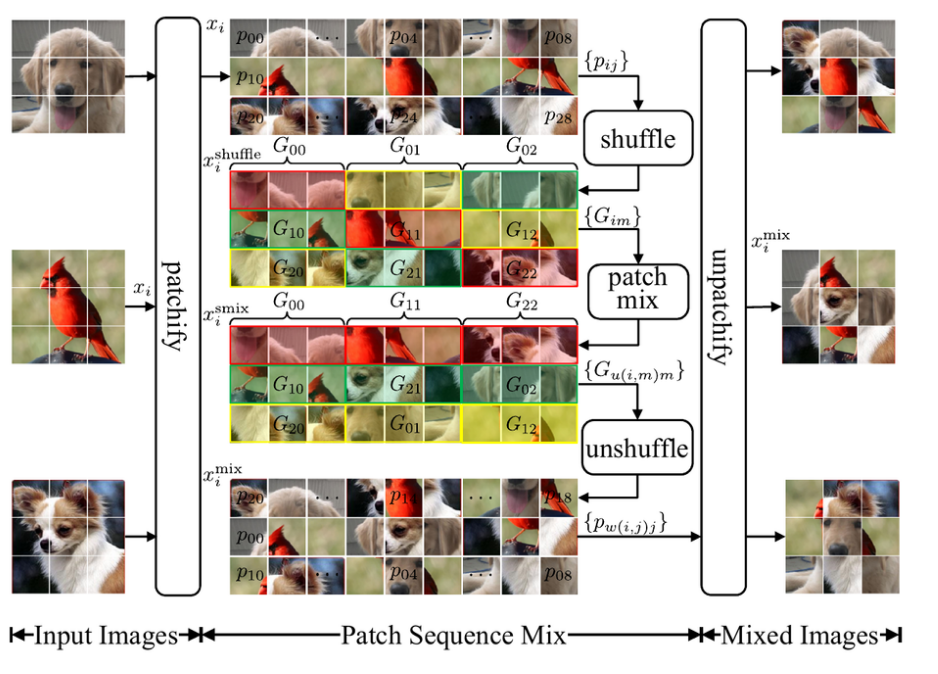
- Patchmix는 3가지 step(shuffle, patch mix, unshuffle)으로 나뉘어 이미지 patch를 mix하는 방식이다.
- 논문에서는 여러 수식을 통해 이를 나타내었는데, 그림을 보고 이해하면 더 쉽게 이해할 수 있다.
- shuffle
- 말 그대로 무작위로 섞는 방식으로 이미지 a는 이미지 a 패치끼리, b는 b끼리 섞는 방식이다.
- patch mix
- 그림과 같이 그룹을 지정해서 한 줄에 3가지 이미지 패치 모두가 골고루 포함되도록 섞는 방식이다.
- 수식으로 나타내면 다음과 같다.
-
- unshuffle
- 같은 row의 패치들을 원래 순서대로 배열하는 방식이다.
- shuffle
- 위의 3가지 step에 대한 pseudo-code는 다음과 같다.

Inter-Instance Similarity Modelling
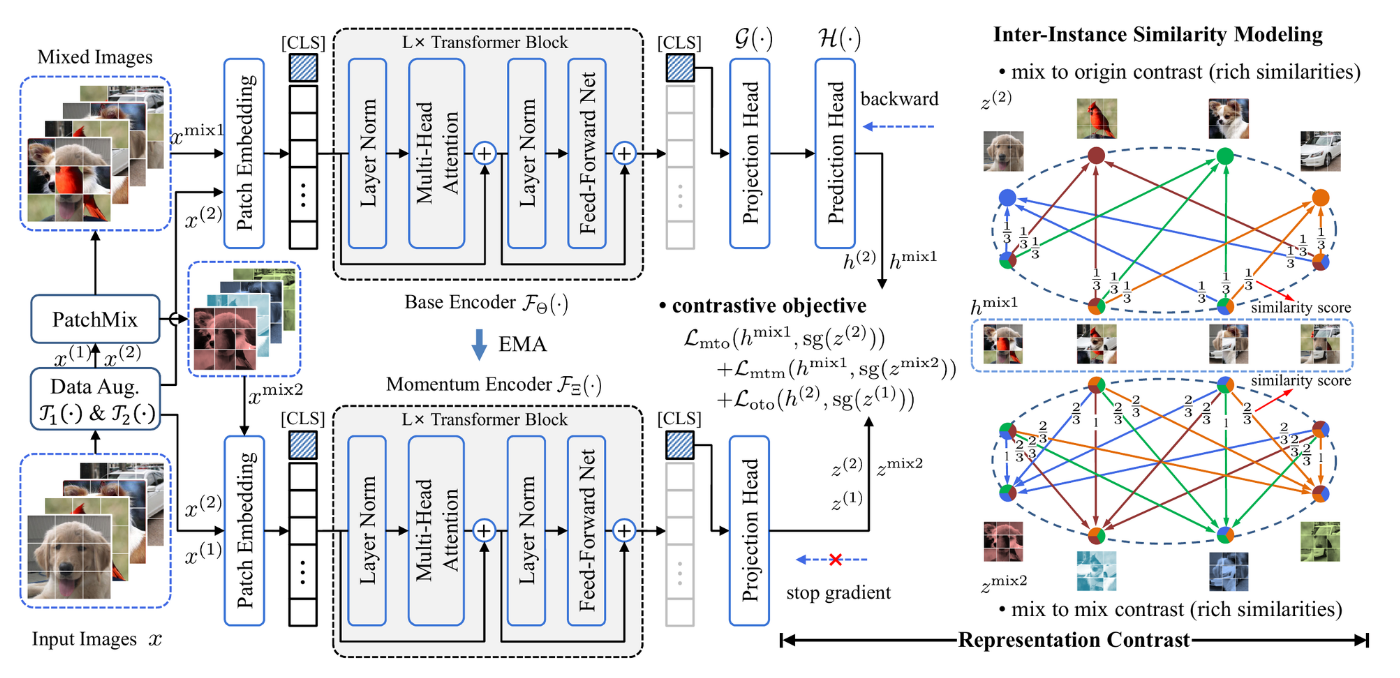
- 전체적인 아키텍쳐는 BYOL 논문에서 제시한 방법과 매우 비슷하다. 하지만, 본 논문에서는 patchmix, augmentation을 통해서 얻어진 데이터들을 통해 총 3가지 Loss를 구한다.
- mix to mix
- , 를 각각 base encoder와 momentum encoder에 넣어서 contrastive loss를 구함.
- mix to origin
- , 를 각각 base encoder, momentum encoder에 넣어 contrastive loss를 구함.
- origin to origin
- 기존 contrastive learning과 같은 방법으로 구함.
- mix to mix
- 여기서 BYOL 논문과 마찬가지로 Momentum encoder를 EMA방식으로 업데이트한다.
- 최종적인 pseudo-code는 다음과 같다.

