목적
ResNeXt 을 이해하고 Pytorch로 구현할 수 있다.
Architecture
- Network architecture
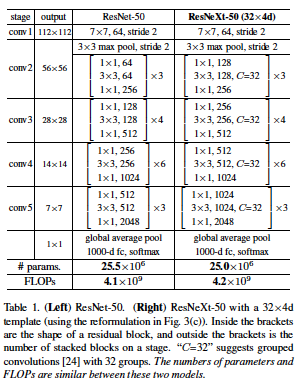
특징
- ResNeXt Block
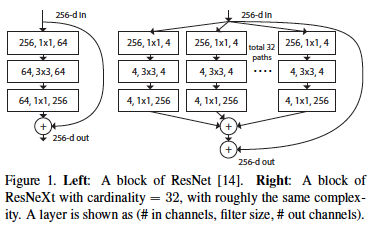
ResNeXt는 ResNet의 Bottleneck과 유사한 block으로 이루어져 있다.
Bottleneck을 구성하고 있는 3개의 layer 중 중간 층의 3x3 Conv layer에 Cardinality 개념을 도입하여 Grouped Conv를 적용했다.
- Grouped Convolutional layer
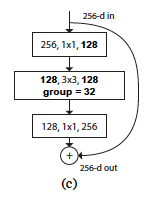
첫 번째 layer와 세 번째 layer는 일반 conv layer이기 때문에 두 번째 layer 만 설명
위 그림처럼 Cardinarity를 32라 가정하고 설명.-
in channels = 128이다. 이를 32 개의 그룹으로 쪼갤 것이다. 각 그룹별in_channels = 4이다. (128 / 32 = 4) -
out_channels = 128이다. 각 그룹별로 4 개의 feature map을 뽑아 총 128개의 feature를 만든다. (32 x 4 = 128)
(Grouped Convolution을 적용할 때
out_channels는 cardinarity의 배수여야 함.)
-
-
개선
-
파라미터 수
일반 Conv와 Grouped Conv를 비교해보자.
nn.Conv2d(64, 128, 3)vsnn.Conv2d(64, 128, 3, groups = 32)
(1)nn.Conv2d(64, 128, 3): 64 x 128 x 3 x 3
(2)nn.Conv2d(64, 128, 3, groups = 32): 32 x (2 x 4 x 3 x 3) = 64 x 4 x 3 x 3
즉, 그룹 수만큼 파라미터 수가 줄어든다. -
Bottleneck block 개선
- ResNet의 bottleneck과 ResNeXt의 bottleneck 구조의 차이
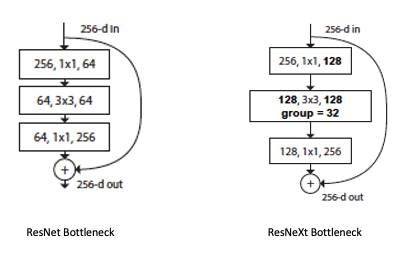 Grouped Conv로 일반 Conv 보다 파라미터 수를 훨씬 아낄 수 있다는 장점을 이용해 ResNeXt의 저자들은
Grouped Conv로 일반 Conv 보다 파라미터 수를 훨씬 아낄 수 있다는 장점을 이용해 ResNeXt의 저자들은
Bottleneck을 구성하고 있는 Conv의 in channel과 out channel 수를 조정하여 ResNet에서 심하게 bottleneck 되던 (256 64) 점을 개선하였다. (256 128)
결과적으로 bottleneck 구조는 개선되었고, 파라미터 수는 비슷해졌다.
-
-
결과
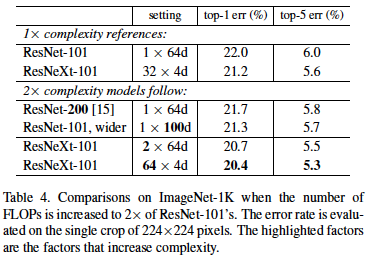
-
ResNet-101과ResNeXt-101을 비교해보면ResNeXt-101의 Error가 더 낮은 것을 볼 수 있다. 이는 Grouped Conv로 파라미터 수를 줄이면서, 채널 수를 늘려 Bottleneck 현상을 어느정도 완화 시킨 것이ResNet의 Bottleneck 보다 효과적이라고 해석할 수 있다. -
ResNet-200과ResNet-101, wider를 비교해보면ResNet-101, wider의 Error가 조금 더 낮다. 이는 layer의 깊이도 중요하지만 layer를 구성하는 필터 수(너비)도 꽤 중요하다고 볼 수 있다. -
ResNeXt-101, C = 2와ResNeXt-101, C = 64를 비교해보면 그룹 수가 많은 것이 더 Error가 낮다. 또한ResNet-200과ResNet-101, wider에 비해ResNeXt-101이 압도적으로 성능이 좋다. 이는 다음과 같이 해석 할 수 있다. 만약, 모델의 파라미터를 2 배 키우고 싶다면.. 층을 깊이 쌓거나, 단순히 너비(채널)를 늘리는 것보다는 층을 유지하고 Grouped Conv를 사용하면서 채널 수를 늘리는 방법이 효율성이 뛰어다는 것을 시사한다.
Code
환경
- python 3.8.16
- pytorch 2.1.0
- torchinfo 1.8.0
구현
ResNet과 매우 유사하다.
import torch
from torch import nn
from torchinfo import summaryclass Bottleneck(nn.Module):
expansion = 2
def __init__(self, in_channels, inner_channels, cardinality, stride = 1, projection = None):
super().__init__()
self.residual = nn.Sequential(
nn.Conv2d(in_channels, inner_channels, 1, stride = stride, bias = False),
nn.BatchNorm2d(inner_channels),
nn.ReLU(),
nn.Conv2d(inner_channels, inner_channels, 3, stride = 1, padding = 1, groups = cardinality, bias = False),
nn.BatchNorm2d(inner_channels),
nn.ReLU(),
nn.Conv2d(inner_channels, inner_channels * self.expansion, 1, bias = False),
nn.BatchNorm2d(inner_channels * self.expansion),
)
self.relu = nn.ReLU()
self.projection = projection
def forward(self, x):
residual = self.residual(x)
if self.projection is not None:
skip_connection = self.projection(x)
else:
skip_connection = x
out = self.relu(residual + skip_connection)
return out
class ResNeXt(nn.Module):
def __init__(self, block, block_list, cardinality, n_classes = 1000):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 7, stride = 2, padding = 3, bias = False),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.maxpool = nn.MaxPool2d(3, stride = 2, padding = 1)
self.in_channels = 64
self.stage1 = self.make_stage(block, 128, block_list[0], stride = 1, cardinality = cardinality)
self.stage2 = self.make_stage(block, 256, block_list[1], stride = 2, cardinality = cardinality)
self.stage3 = self.make_stage(block, 512, block_list[2], stride = 2, cardinality = cardinality)
self.stage4 = self.make_stage(block, 1024, block_list[3], stride = 2, cardinality = cardinality)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(2048, n_classes)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def make_stage(self, block, inner_channels, block_nums, stride, cardinality):
if self.in_channels != inner_channels * block.expansion or stride != 1:
projection = nn.Sequential(
nn.Conv2d(self.in_channels, inner_channels * block.expansion, 1, stride = stride, bias = False),
nn.BatchNorm2d(inner_channels * block.expansion)
)
else:
projection = None
layers = []
for idx in range(block_nums):
if idx == 0:
layers.append(block(self.in_channels, inner_channels, cardinality, stride, projection))
self.in_channels = inner_channels * block.expansion
else:
layers.append(block(self.in_channels, inner_channels, cardinality))
return nn.Sequential(*layers)def ResNeXt50():
return ResNeXt(Bottleneck, [3, 4, 6, 3], cardinality = 32)
def ResNeXt101():
return ResNeXt(Bottleneck, [3, 4, 23, 3], cardinality = 32)model = ResNeXt50()
summary(model, input_size=(2,3,224,224), device='cpu')#### OUTPUT ####
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNeXt [2, 1000] --
├─Sequential: 1-1 [2, 64, 112, 112] --
│ └─Conv2d: 2-1 [2, 64, 112, 112] 9,408
│ └─BatchNorm2d: 2-2 [2, 64, 112, 112] 128
│ └─ReLU: 2-3 [2, 64, 112, 112] --
├─MaxPool2d: 1-2 [2, 64, 56, 56] --
├─Sequential: 1-3 [2, 256, 56, 56] --
│ └─Bottleneck: 2-4 [2, 256, 56, 56] --
│ │ └─Sequential: 3-1 [2, 256, 56, 56] 46,592
│ │ └─Sequential: 3-2 [2, 256, 56, 56] 16,896
│ │ └─ReLU: 3-3 [2, 256, 56, 56] --
│ └─Bottleneck: 2-5 [2, 256, 56, 56] --
│ │ └─Sequential: 3-4 [2, 256, 56, 56] 71,168
│ │ └─ReLU: 3-5 [2, 256, 56, 56] --
│ └─Bottleneck: 2-6 [2, 256, 56, 56] --
│ │ └─Sequential: 3-6 [2, 256, 56, 56] 71,168
│ │ └─ReLU: 3-7 [2, 256, 56, 56] --
├─Sequential: 1-4 [2, 512, 28, 28] --
│ └─Bottleneck: 2-7 [2, 512, 28, 28] --
│ │ └─Sequential: 3-8 [2, 512, 28, 28] 217,088
│ │ └─Sequential: 3-9 [2, 512, 28, 28] 132,096
│ │ └─ReLU: 3-10 [2, 512, 28, 28] --
│ └─Bottleneck: 2-8 [2, 512, 28, 28] --
│ │ └─Sequential: 3-11 [2, 512, 28, 28] 282,624
│ │ └─ReLU: 3-12 [2, 512, 28, 28] --
│ └─Bottleneck: 2-9 [2, 512, 28, 28] --
│ │ └─Sequential: 3-13 [2, 512, 28, 28] 282,624
│ │ └─ReLU: 3-14 [2, 512, 28, 28] --
│ └─Bottleneck: 2-10 [2, 512, 28, 28] --
│ │ └─Sequential: 3-15 [2, 512, 28, 28] 282,624
│ │ └─ReLU: 3-16 [2, 512, 28, 28] --
├─Sequential: 1-5 [2, 1024, 14, 14] --
│ └─Bottleneck: 2-11 [2, 1024, 14, 14] --
│ │ └─Sequential: 3-17 [2, 1024, 14, 14] 864,256
│ │ └─Sequential: 3-18 [2, 1024, 14, 14] 526,336
│ │ └─ReLU: 3-19 [2, 1024, 14, 14] --
│ └─Bottleneck: 2-12 [2, 1024, 14, 14] --
│ │ └─Sequential: 3-20 [2, 1024, 14, 14] 1,126,400
│ │ └─ReLU: 3-21 [2, 1024, 14, 14] --
│ └─Bottleneck: 2-13 [2, 1024, 14, 14] --
│ │ └─Sequential: 3-22 [2, 1024, 14, 14] 1,126,400
│ │ └─ReLU: 3-23 [2, 1024, 14, 14] --
│ └─Bottleneck: 2-14 [2, 1024, 14, 14] --
│ │ └─Sequential: 3-24 [2, 1024, 14, 14] 1,126,400
│ │ └─ReLU: 3-25 [2, 1024, 14, 14] --
│ └─Bottleneck: 2-15 [2, 1024, 14, 14] --
│ │ └─Sequential: 3-26 [2, 1024, 14, 14] 1,126,400
│ │ └─ReLU: 3-27 [2, 1024, 14, 14] --
│ └─Bottleneck: 2-16 [2, 1024, 14, 14] --
│ │ └─Sequential: 3-28 [2, 1024, 14, 14] 1,126,400
│ │ └─ReLU: 3-29 [2, 1024, 14, 14] --
├─Sequential: 1-6 [2, 2048, 7, 7] --
│ └─Bottleneck: 2-17 [2, 2048, 7, 7] --
│ │ └─Sequential: 3-30 [2, 2048, 7, 7] 3,448,832
│ │ └─Sequential: 3-31 [2, 2048, 7, 7] 2,101,248
│ │ └─ReLU: 3-32 [2, 2048, 7, 7] --
│ └─Bottleneck: 2-18 [2, 2048, 7, 7] --
│ │ └─Sequential: 3-33 [2, 2048, 7, 7] 4,497,408
│ │ └─ReLU: 3-34 [2, 2048, 7, 7] --
│ └─Bottleneck: 2-19 [2, 2048, 7, 7] --
│ │ └─Sequential: 3-35 [2, 2048, 7, 7] 4,497,408
│ │ └─ReLU: 3-36 [2, 2048, 7, 7] --
├─AdaptiveAvgPool2d: 1-7 [2, 2048, 1, 1] --
├─Linear: 1-8 [2, 1000] 2,049,000
==========================================================================================
Total params: 25,028,904
Trainable params: 25,028,904
Non-trainable params: 0
Total mult-adds (G): 7.54
==========================================================================================
Input size (MB): 1.20
Forward/backward pass size (MB): 427.11
Params size (MB): 100.12
Estimated Total Size (MB): 528.43
==========================================================================================