논문 링크 : https://arxiv.org/abs/2107.06263
혁신적인 하이브리드 네트워크 CMT
서론
-
최근 시각 인식 작업에서 Transformers 가 성공적으로 적용되었으나, 기존 CNNs와 비교해 성능 및 계산 비용에서 차이가 존재한다. 이번 포스트에서는 이 문제를 해결하고자 한 새로운 하이브리드 네트워크 CMT에 대해 소개하고자 한다.
-
CNNs와 Transformers의 배경
- CNNs: 컴퓨터 비전에서 특징 추출 능력으로 높은 성능을 보임. 얼굴 인식, 자율 주행 등 다양한 응용 분야에서 널리 사용되고 있다.
- Transformers: 원래 자연어 처리(NLP)에서 시작하여 텍스트에서 단어들 사이의 관계를 잘 이해한다. 최근에는 이 모델을 이미지 인식에 적용하려는 시도가 많아짐. 시각 인식 작업에 성공적으로 적용되고있고, 특히 장거리 의존성 캡처에 강점.
-
문제점
- Transformers와 CNNs 사이의 성능(정확도) 및 계산 비용(속도) 차이.
- Vision Transformer(ViT) 모델의 패치 분할 방식으로 인한 공간적 로컬 정보 손실. 즉, 이미지를 작은 조각들로 나누어 처리하는데 이 방식은 전체적인 구조를 이해하는 데는 좋으나, 조각 내부의 세부적인 정보는 잘 잡아내지 못한다.
이로 인해 본 논문에서는 Transformers의 장거리 의존성 캡처 능력과 CNN의 로컬 정보 추출 능력을 결합하여 보다 더 나은 정확도와 효율성을 제공하는 하이브리드 네트워크를 개발.
CMT의 혁신적인 구조
-
Transformers와 CNNs의 만남 : CMT는 Transformers의 장거리 의존성 캡쳐 능력과 CNN의 로컬 정보 추출 능력을 결합한다.
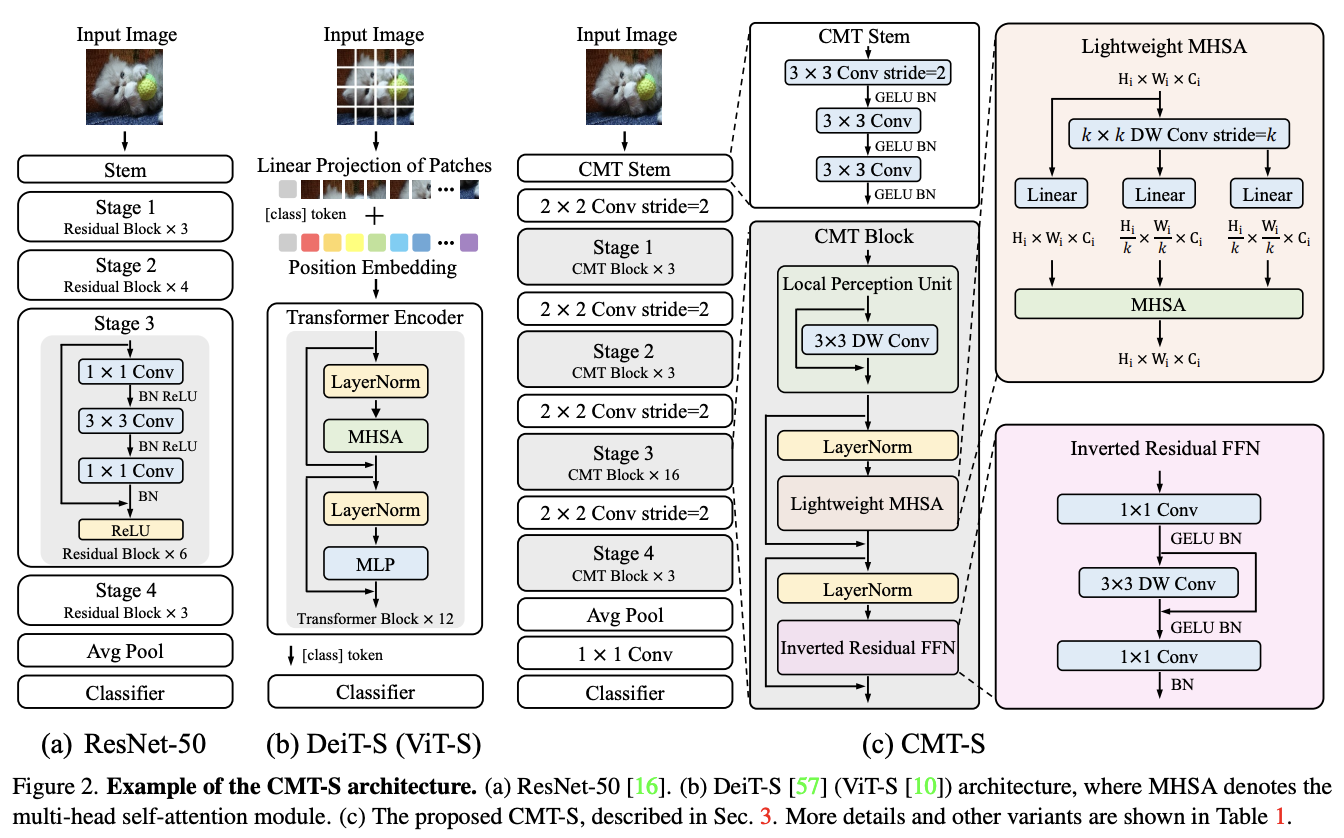
-
Convolution Stem
- 입력 이미지를 CNN으로 전처리하여 세밀한 특징을 추출한다. 이미지를 처음에 잘게 쪼개기 전에 중요한 정보를 미리 뽑아내는 단계.
-
CMT Blocks
- Depth-wise Convolution을 사용하여 로컬 정보를 강화한 Transformer 변형이다. 이미지 조각 내부의 세부적인 정보를 더 잘 캡처하기 위해 고안된 기술.
-
Stage-wise Architecture
- CNN과 유사한 단계별 구조로 다중 해상도 특징 맵을 생성하여 Dense Predicton Tasks에 최적화된 구조이다. 다양한 크기의 특징을 추출할 수 있게 해줘서 더 복잡한 이미지를 잘 처리할 수 있다.
그 외...
- Local Perception Unit (LPU)
- CMT block의 첫 번째 구성요소. Depth-wise Convolution을 사용하여 로컬 정보를 보강. 이미지의 작은 부분들에 대한 세부 정보를 더 잘 이해하게 해준다.
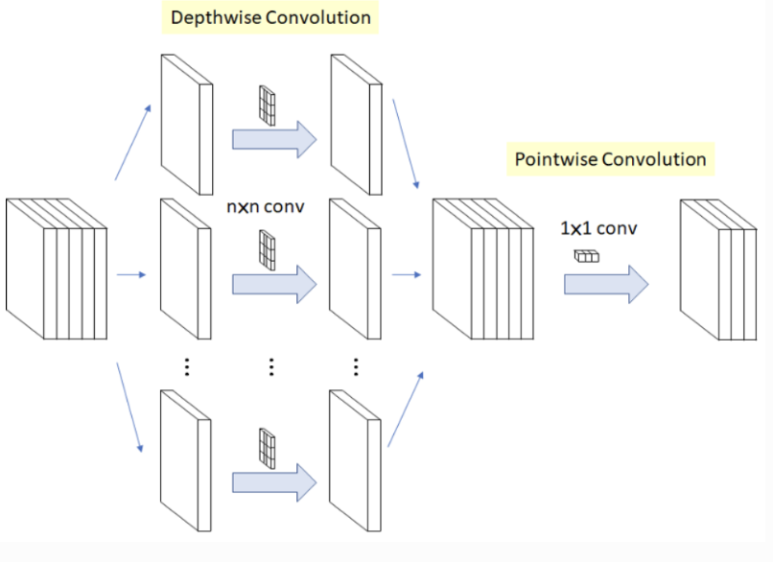
- Depth-wise convolution이란?
컨볼루션 연산의 한 종류. 입력 채널마다 따로따로 컨볼루션을 수행하는 방법. 이 방법은 모델의 파라미터 수를 줄이고, 계산량을 감소시키면서도 모델의 성능을 유지하는 효과가 있다. 입력 이미지의 각 채널마다 따로따로 필터를 적용하므로 입력 이미지의 지역적인 정보를 더욱 잘 보존할 수 있다.
- Lightweight Multi-head Self-Attention (LMHSA)
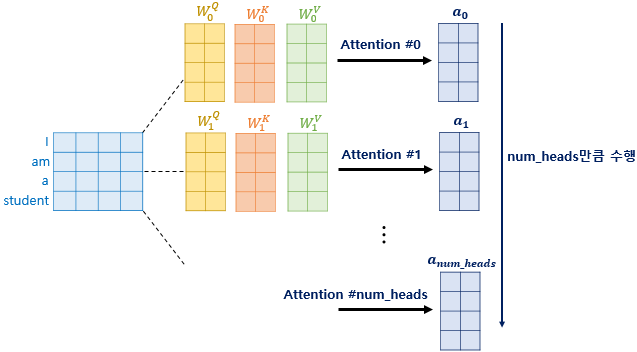
- 효율성을 높이기 위해 공간 크기를 줄이는 Depth-wise Convolution 사용. 계산 비용이 줄어드는 효과가 발생한다.
Depthwise / Pointwise Convolution이란 다음 그림과 같이 각각의 채널에 독립적으로 convolution을 수행하는걸 말한다.
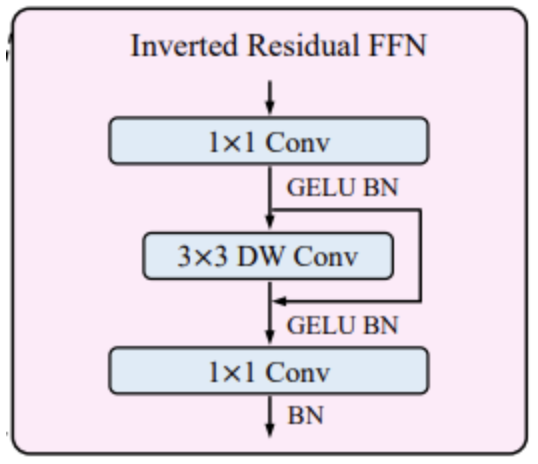
- Inverted Residual Feed-forward Network (IRFFN)
ViT 에서 제안한 기존 FFN 의 경우에는 2개의 linear layer 를 사용하였다.
- 첫 번째 layer 는 expansion 인 4만큼 차원을 증가시켜주고
- 두 번째 layer 를 거치면서 다시 원래의 차원으로 돌아오는 방식이다.
[출처][논문 리뷰] CMT: Convolutional Neural Networks Meet Vision Transformers|작성자 지피 - CNN의 inverted residual block을 모방한 구조로, 중간에 shortcut 연결을 통해 성능 향상.
실험 결과
- ImageNet에서의 성능 : CMT-S는 83.5% top-1 정확도를 달성하여, DeiT와 EfficientNet같은 기존 모델들보다 14배, 2배 작은 FLOPs로 더 나은 성능.
- 다양한 데이터셋에서의 적용 : CIFAR10, CIFAR100, Flowers 등 다양한 데이터셋에서 높은 성능을 유지했다.
- Object Detection과 Segmentation : COCO 데이터셋에서 RetinaNet 및 Mask R-CNN 기반으로 높은 성능을 기록했다.
Ablation Study로 본 CMT의 강점
- Stage-wise Architecture : 단일 스케일 ViT/DeiT보다 다중 스케일 정보 제공하여 성능이 향상되었다.
- LPU 및 IRFFN 모듈 : 각각의 모듈 추가로 성능이 향상되었다.
- 적절한 Normalization : LN과 BN의 적절한 사용으로 성능이 최적화되었다. 모든 LN을 BN으로 교체 시 학습 불가, 반대로 모든 BN을 LN으로 교체 시 성능이 저하됨.
- 복합 스케일링 전략 : 단일 스케일링보다 뛰어난 성능을 보였다. 복합 스케일링이 깊이만 또는 차원만 확장한 경우보다도 더 나은 성능을 기록함.
결론
CMT는 CNN과 Transformers의 장점을 결합한 혁신적인 하이브리드 네트워크로, 시각 인식 작업에서 높은 성능과 효율성을 자랑한다. 다양한 비전 작업에 쉽게 적용할 수 있는 이 네트워크의 잠재력을 기대해 볼 수 있을 것 같다.

hckr.