앙상블
Deicison Tree 하나의 모형만을 독립적으로 사용하기 보다는
서로 다른 Deicison Tree 여러 개를 함께 사용한다.
WHY? Deicison Tree 하나의 모형으로는 학습이 잘 되지 않기 때문!
이렇게 하나의 모형으로는 학습이 잘 안될 때 여러 개를 합쳐 사용하는 것을 “앙상블” 이라고 한다.
앙상블 학습 (Ensemble Learning)
여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 적확한 최종 예측을 도출하는 기법
현재 분류의 SOTA(State-of-the-Art)
-> 비정형 데이터의 분류 : 딥러닝
-> 정형 데이터의 분류 : 머신러닝 앙상블 모델
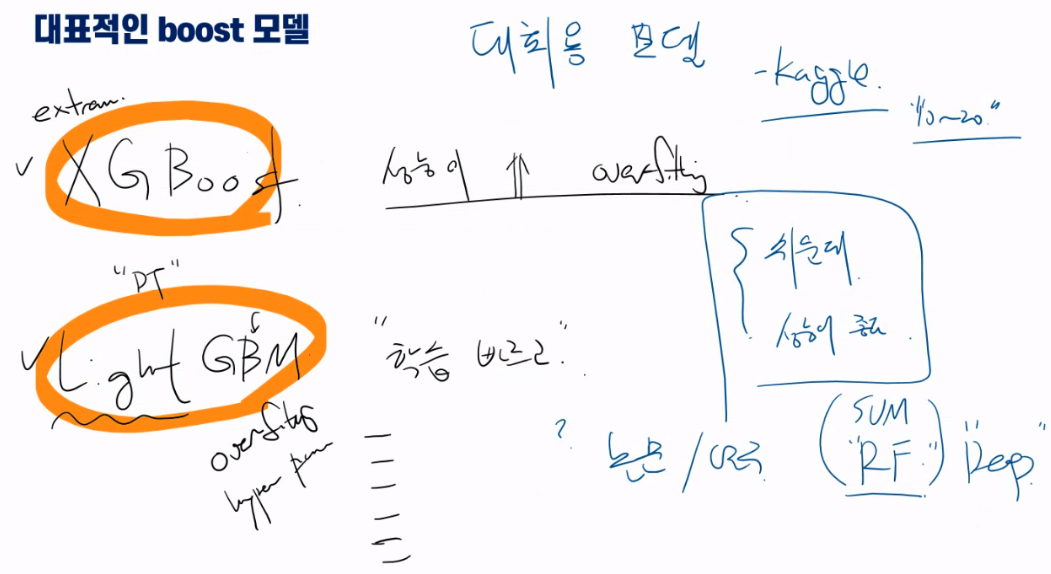
그 중에서도 부스팅 계열 앙상블 알고리즘이 강세 (Xgboost, LightGBM)
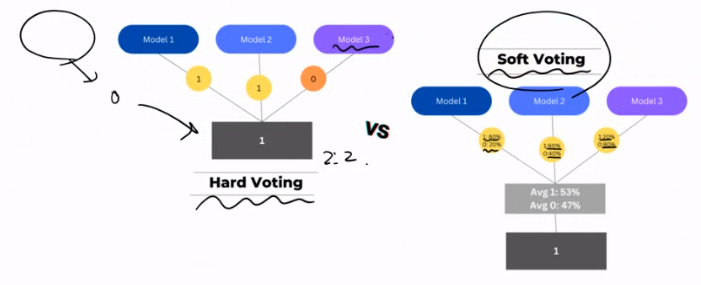
Voting이란
Hard Voting : 다수의 분류기간 다수결로 최종 클래스 결정하는 것
Soft Voting : 다수의 분류기들의 class 확률의 평균으로 결정하는 것
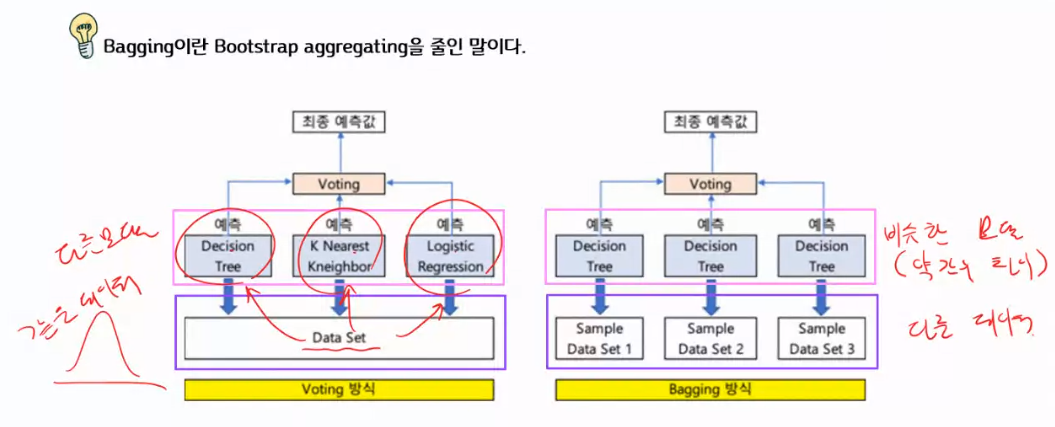
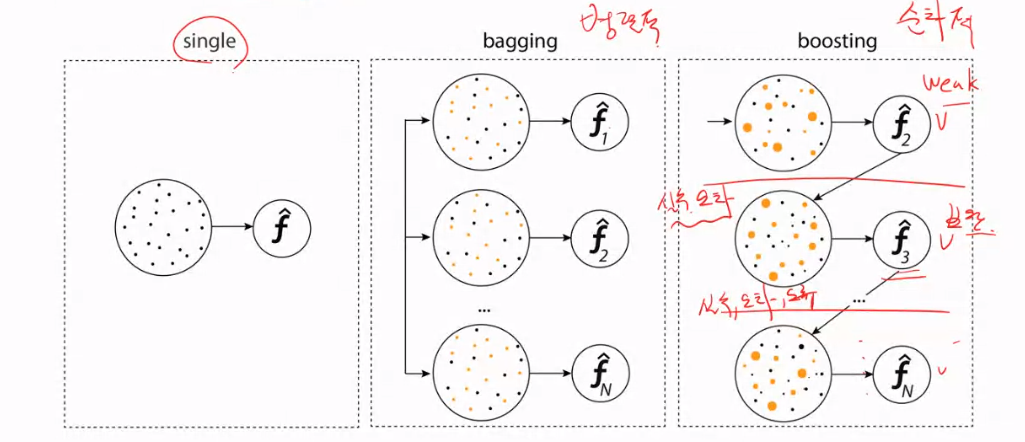
Bagging이란
Bagging이란 Bootstrap aggregating을 줄인 말이다.
❖ Bootstrap
원본 데이터 집단으로부터 원본과 유사한 새로운 데이터 집단을 추출하는 것이다.
❖ Aggregate
‘모으다’, ‘합치다’라는 의미이다.
즉, Bagging이란 여러개의 원본과 유사한 새로운 데이터 집단을 학습시켜 합치는 것을 말한다.
Bootstrap이란
Bootstrap이란 원본데이터로부터 원본데이터와 유사한 샘플데이터를 추출하는 것을 말한다.
Scikit-learn에서는 원본데이터의 개수가 N개라면, 원본데이터로부터 중복을 허용하여,
무작위로 N개의 데이터를 추출하여 샘플데이터를 만든다.
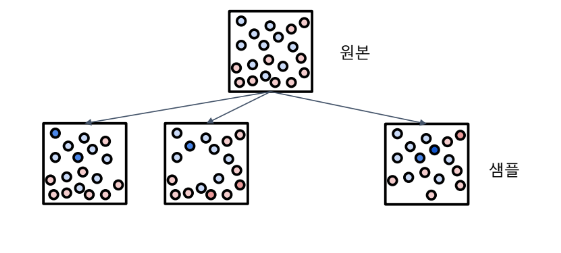
배깅은 Bootstrap한 다음,Aggregating
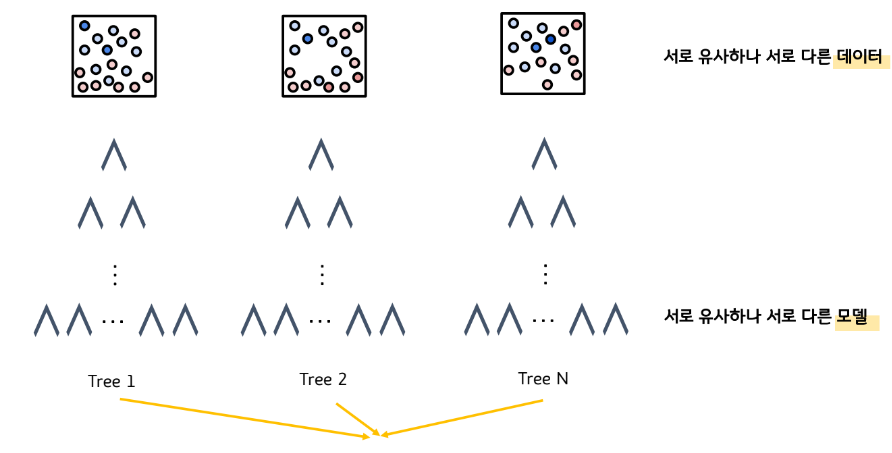
부트스트랩으로 각각의 다른 샘플데이터가 만들어졌다.
데이터가 유사하지만, 서로 다르기 때문에 약한 학습기(Decision tree)의 결과도 서로 다르게 나올 가능성이 높다.
Aggregating이란?
서로 다른 약한 학습기(Decision Tree)의 예측값을 합치는 것을 말한다.
회귀분석은 평균을 내면 되고, 분류는 빈도수를 계산하면 된다.
Random Forest, 무작위의 숲
나무가 모이면 숲이 된다.
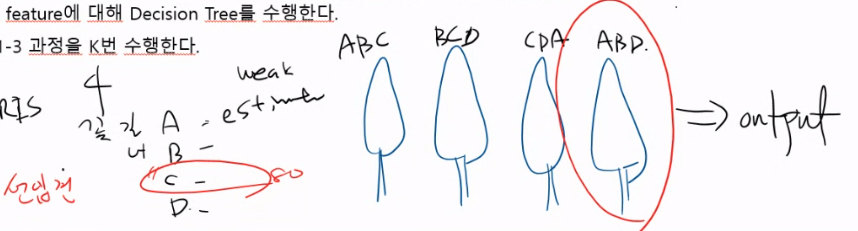
부트스트랩으로 만들어진 여러 샘플 데이터를 가지고, 여러번의 Decision Tree를 수행한다음
이를 Aggregation하는 것이 Random Forest이다.
- 학습 데이터 N개로부터 중복을 허용하여 무작위로 샘플 데이터 N개를 추출한다.
- 샘플 데이터에서 중복을 허용하지 않고, 무작위로 X 값(input feature) d개를 선택한다.
- d개의 feature에 대해 Decision Tree를 수행한다.
- 위의 1-3 과정을 K번 수행한다.
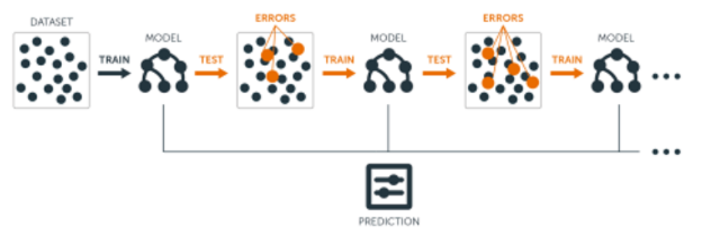
Boosting이란
Bagging과의 공통점
원본 데이터 집단으로부터 원본과 유사한 새로운 데이터 집단을 K번 추출하여 K번의 약학습기 학습을 진행한다.
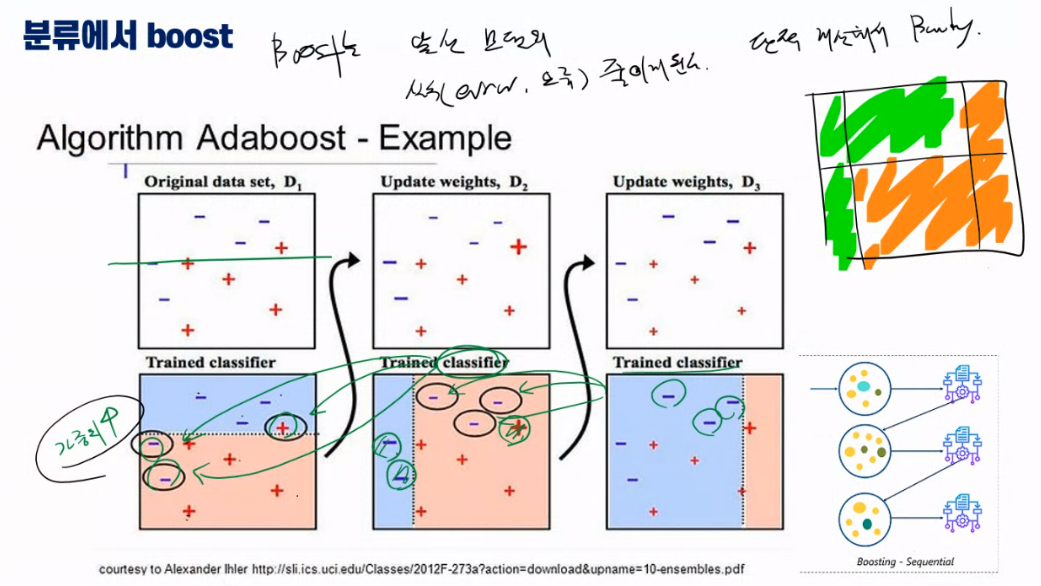
Bagging과의 차이점
Bagging은 K번의 샘플링을 독립적으로 수행하지만, Boosting은 순차적으로 먼저 진행한 샘플링을 통해 먼저 학습한다. 학습한 결과에서 오차가 발생한 데이터에 가중치를 더 강하게 준 다음, 다음 샘플링을 수행한다.
즉, 오차가 발생했던 데이터가 다음 번에 또 뽑힌다면 또 틀리지는 않도록 학습한다는 의미다.
Bagging VS Boosting
GBM(Gradient Boosting Model)
GBM이란?
Ada Boost와 유사하지만, 가중치 업데이트를 경사하강법(Gradient Descent)를 이용하는 것이 큰 차이
즉, 뛰어난 예측 성능과 동시에 보다 빠른 수행시간으로 학습을 진행한다.