ML
1.머신러닝 이미지 전처리

컴퓨터에게 이미지를 어떻게 인식시킬까 “우선, 기계가 분석할 수 있는 데이터로 변환해주자” 이를 데이터를 “정형화” 해준다고 한다. 비정형 데이터 → 정형 데이터 (이미지) (숫자) 컴퓨터에게 이미지를 인식시키는법 (이미지) (숫자) → (벡터) 색의 밝기를 기
2.텍스트 전처리

전처리란 “데이터를 분석하기에 앞서 분석에 용이하도록 데이터를 정제/가공하는 작업” ↓ How? 영어는 NLTK 패키지를, 한글은 KoNLPy 패키지를 사용한다. 텍스트 전처리 “텍스트 데이터 전처리로는 토큰화, 노이즈/불용어 제거, 정규화, 품사 태깅, 벡터화
3.머신러닝 개론

데이터는 눈에 보이지 않습니다.보이지 않는 세상을 이해하고 다루기 위해서는 수학이 필요합니다.관계, 나라와 사회(법)를 위해 단어와 의미를 정의하듯이수학은 세상의 법칙을 수식이라는 표현으로 의미를 정의한 것입니다.• 지수와 로그• 확률과 통계• 벡터와 행렬• 미분"현재
4.머신러닝 기초

학습했던 데이터로 다시 검증한다.→ 검증결과를 신뢰할 수 없다.(ex. 스카이캐슬, 예서 - 시험문제로 학습)새로운 데이터를 수집해서 검증한다.→ 너무 수고롭거나 불가능하다.기존의 10만개 데이터셋 중에 일부는 학습데이터로 사용하지 않는다.검증할 데이터로 따로 남겨두는
5.Logistic Regression
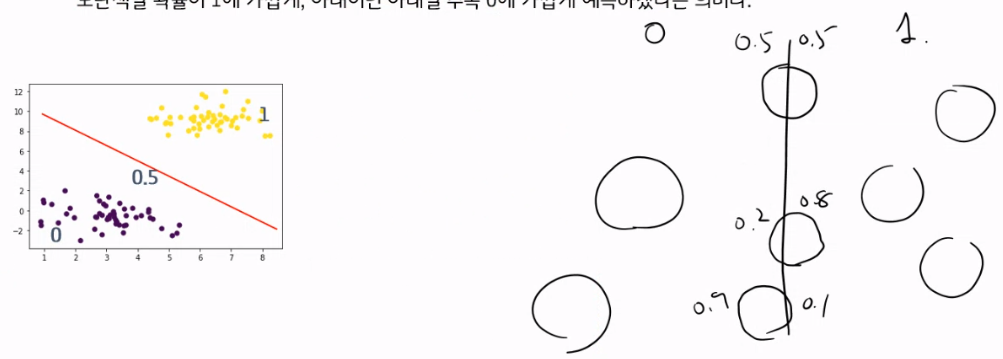
이메일 분류 : spam or ham종양 분류 : 악성 or 양성Classification model의 경우, 분류 방식에 따라 다음과 같이 모형을 나눌 수 있다.분류(Classification)의 사례확률적으로 예측하느냐 vs 비확률적으로 예측하느냐확률적 모형 vs
6.지도학습 Linear SVM
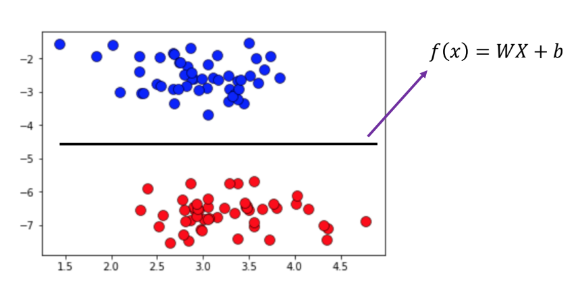
분류(Classification)의 사례이메일 분류 : spam or ham종양 분류 : 악성 or 양성Classification model의 경우, 분류 방식에 따라 다음과 같이 모형을 나눌 수 있다.확률적으로 예측하느냐 vs 비확률적으로 예측하느냐확률적 모형 vs
7.지도학습 Decision Tree
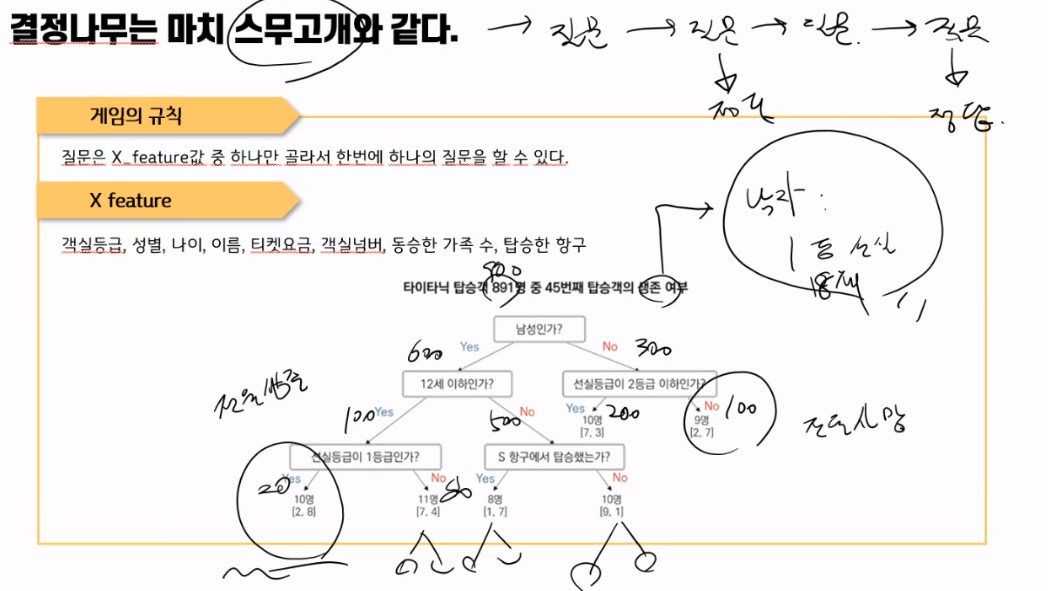
좋은질문과 나쁜질문을 결정 짓는 기준이 Information Gain(정보획득)이다.정보획득이 많다는 뜻은 질문으로 인해 나뉘는 데이터셋의 집단에 카테고리가 잘 분리된다는 의미다.질문에 의해 왼쪽으로 분리된 집단은 A카테고리 많고, 오른쪽으로 분리된 집단은 B카테고리가
8.Ensemble
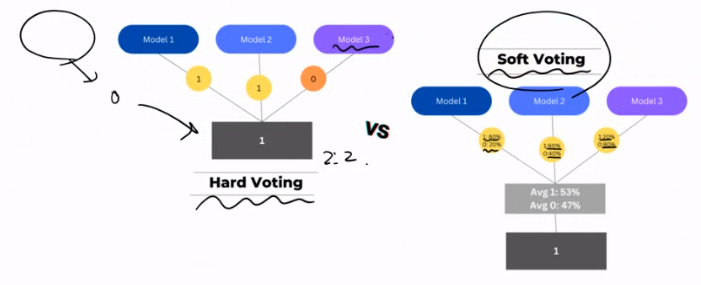
Deicison Tree 하나의 모형만을 독립적으로 사용하기 보다는서로 다른 Deicison Tree 여러 개를 함께 사용한다.WHY? Deicison Tree 하나의 모형으로는 학습이 잘 되지 않기 때문!이렇게 하나의 모형으로는 학습이 잘 안될 때 여러 개를 합쳐 사
9.비지도학습(Unsupervised Learning)
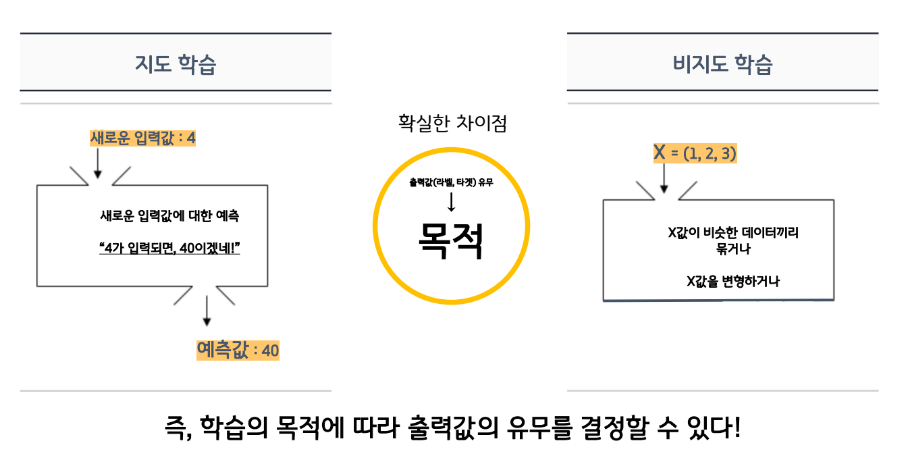
비지도학습은 라벨(정답값, y값, 종속변수)이 없다.데이터가 어떻게 구성되었는지를 알아내는 문제!인간의 개입이 없는 데이터를 스스로 학습하여그 속의 패턴(pattern) 또는 각 데이터 간의 유사도(similarity)를 학습한다.가장 대표적으로 clustering과