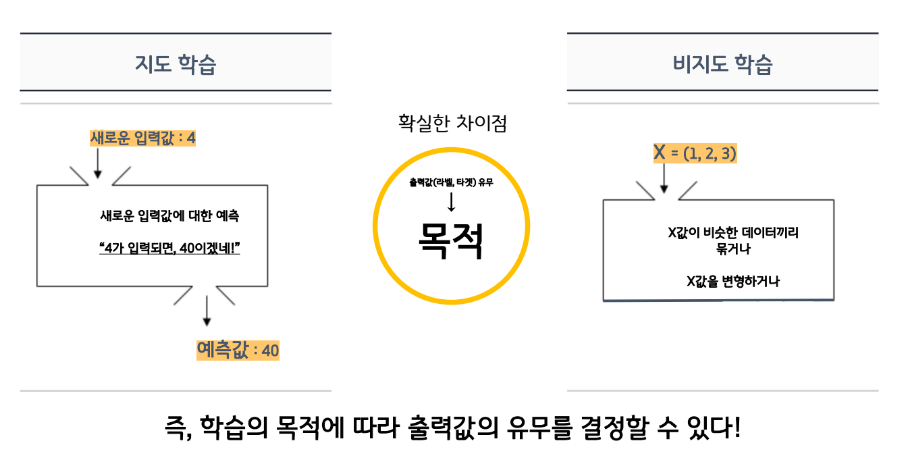
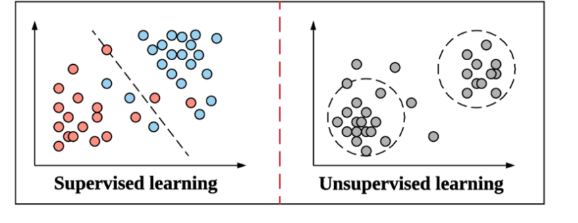
비지도학습(Unsupervised Learning)
비지도학습은 라벨(정답값, y값, 종속변수)이 없다.
- 데이터가 어떻게 구성되었는지를 알아내는 문제!
- 인간의 개입이 없는 데이터를 스스로 학습하여
그 속의 패턴(pattern) 또는 각 데이터 간의 유사도(similarity)를 학습한다.
- 가장 대표적으로 clustering과 dimensionality reduction이 있음
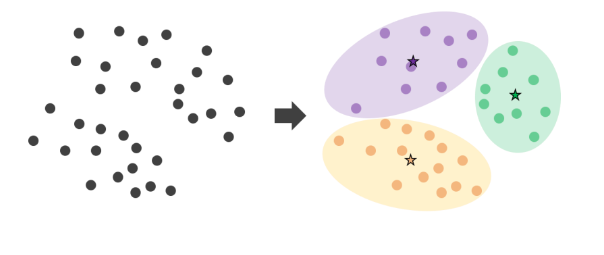
Clustering
K-means(clustering)
K-means는 사용자가 정한 K개의 클러스터로 군집을 생성하는 알고리즘!
- 가장 일반적으로 사용되는 클러스터링 알고리즘
- 알고리즘이 쉽고 간결하지만 효율적이어서 여전히 자주 사용
- 중심점(centroid)라는 특정한 임의의 지점을 선택하여 해당 중심에 가장 가까운 포인트들을 선택하는 기법
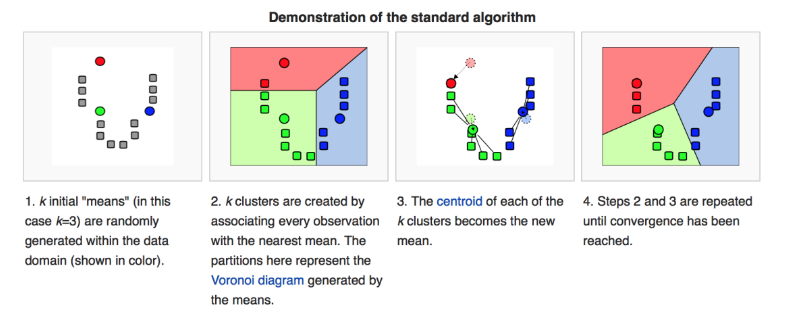
1. K-means 알고리즘의 첫번째 작업은 중심점의 초기값을 설정하는 것이다. 초기값은 데이터 중에서 임의로 K개를 선택한다.
2. 각 중심점에서 가장 가까운 포인트들을 선택한다
3. 각 군집 포인트들의 평균으로 중심점을 업데이트한다.
4. 2-3번을 반복하다가 더이상 중심점 이동이 없을 경우에 중단한다.
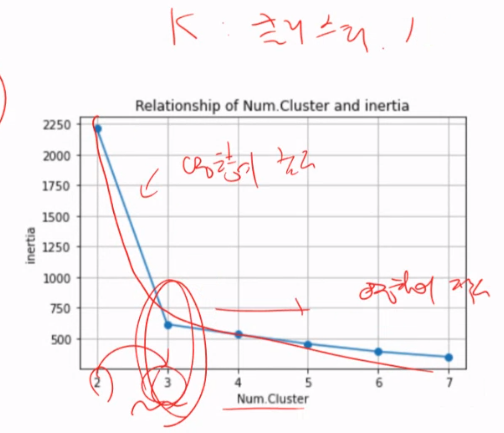
(적정 k 클러스터링 잡는법)
Transformation
차원축소
차원축소는 매우 많은 feature로 구성된 다차원 데이터 세트의 차원을 축소해
새로운 차원의 데이터 세트를 생성하는 것
- Feature Selection : 특정 Feature에 종속성이 강한 불필요한 Feature 제거
- Feature Extraction : 기존 Feature를 저차원의 중요 feature로 압축해서 추출하는 것
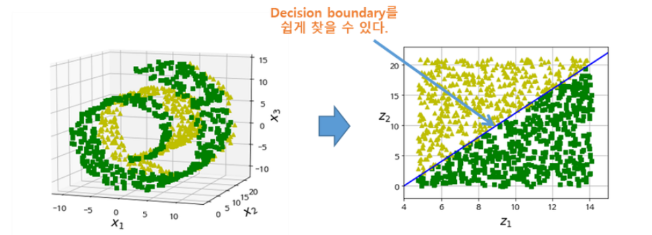
왜 차원축소를 해야 하는가
차원의 저주 ( Curse of dimension)
데이터 학습을 위한 차원(=특성,변수,피쳐)이 증가하면서 학습데이터의 수 보다 차원의 수가 많아지게 되어 모델의 성능이 떨어지는 현상.
예를 들어 데이터의 수는 500개인데 차원이 1000개라면, 모델의 복잡도는 증가하지만 성능은 떨어지게 됨.
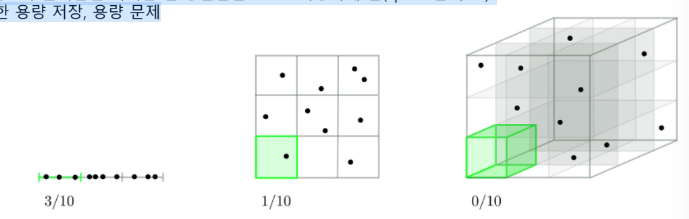
일반적으로 차원이 커지면 -> 데이터 포인터 간의 거리가 기하급수적으로 증가
공간의 부피가 증가하고 밀도가 줄어들면 이러한 빈 공간들은 0으로 저장하게 됨(sparse한 구조)
-> 분석시간 증가, 불필요한 용량 저장, 용량 문제
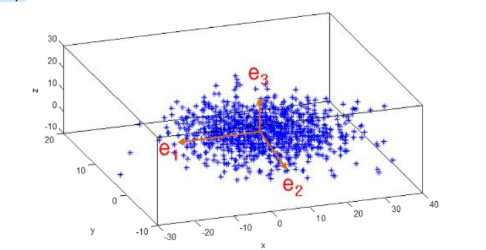
PCA(주성분분석)
PCA는 여러 변수간에 존재하는 상관관계를 이용해 이를 대표하는 주성분(Principal Component)을 추출해 차원을 축소하는 기법
목표 : 정보 유실 최소화
-> 가장 높은 분산을 가지는 데이터의 축을 찾아 해당 축(주성분!)으로 차원을 축소하겠다.
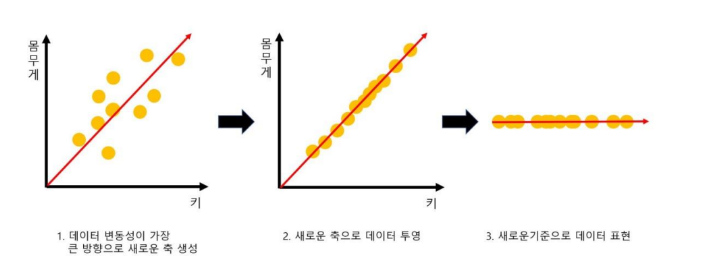
- PCA는 제일 먼저 가장 큰 데이터 변동성을 기반으로 첫 번째 벡터 축을 생성
- 두 번째 축은 이 벡터 축에 직각이 되는 벡터(직교 벡터)를 축으로 생성
- 세 번째 축은 다시 두 번째 축과 직각이 되는 벡터를 설정하는 방식으로 축을 생성
- 이렇게 생성된 벡터 축에 원본 데이터를 투영하면 벡터 축의 개수 만큼의 차원으로 원본 데이터가
차원 축소 됩니다.