머신러닝 개론
데이터는 눈에 보이지 않습니다.
보이지 않는 세상을 이해하고 다루기 위해서는 수학이 필요합니다.
관계, 나라와 사회(법)를 위해 단어와 의미를 정의하듯이
수학은 세상의 법칙을 수식이라는 표현으로 의미를 정의한 것입니다.
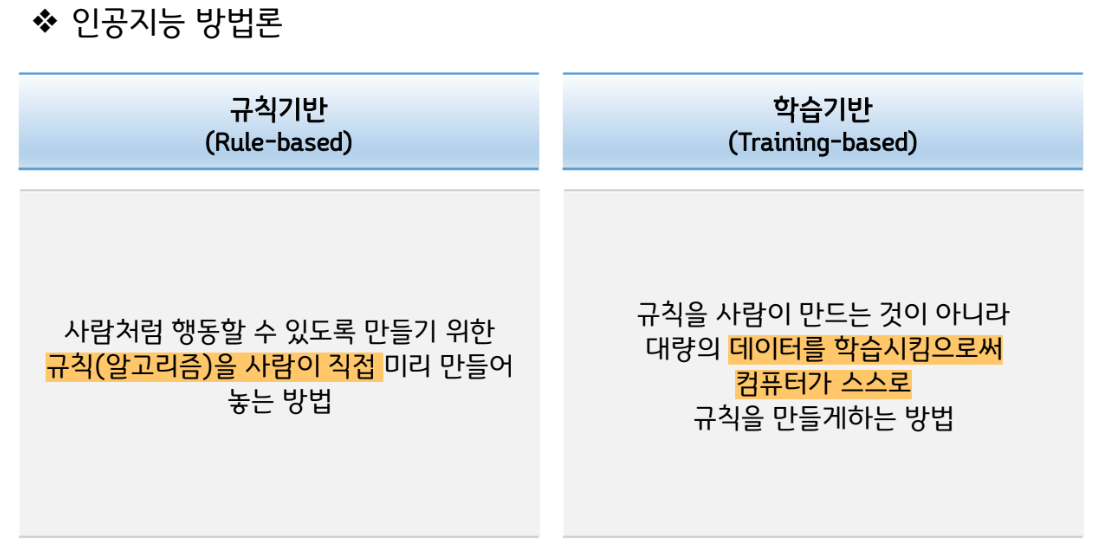
• 지수와 로그
• 확률과 통계
• 벡터와 행렬
• 미분

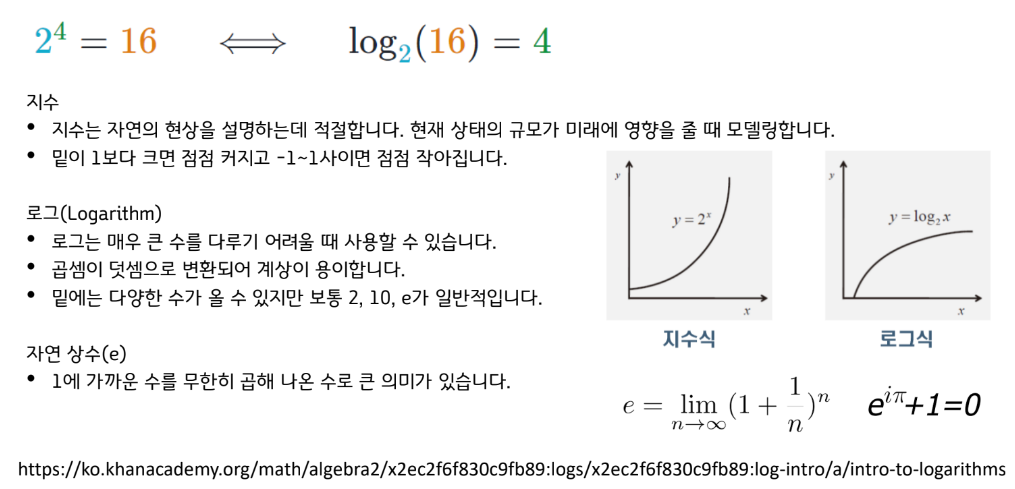
지수와 로그
"현재상태 * @ = 다음상태"
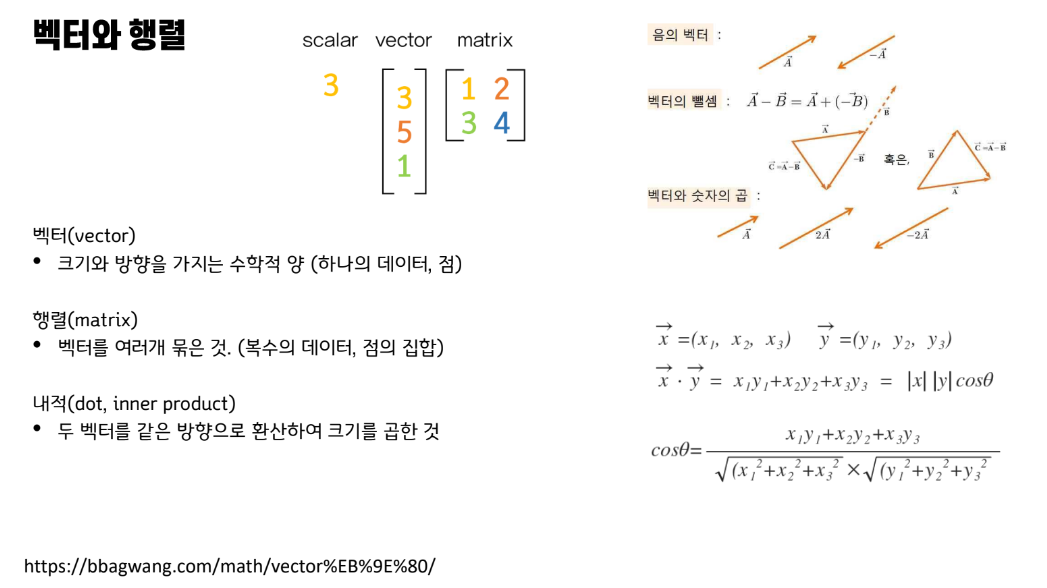
백터와 행렬
확률과 통계
통계에 대해 가장 먼저 듣는 것 중 하나는 빈도주의와 베이지안주의라는 두 가지 접근 방식이 있다는 것입니다.
빈도주의자에게 확률은 반복 측정의 제한된 경우:확률은 근본적으로 사건의 빈도와 관련이 있습니다
베이지안의 경우 확률 개념은 진술에 대한 확실성의 정도:확률은 근본적으로 이벤트에 대한 우리 자신의 지식과 관련이 있습니다
머신러닝은 수많은 모델 파라미터가 고정된 값이 아닌 불확실성을 가진 확률 변수로 보기 때문에 베이지안 머신러닝이 적합
참고:http://jakevdp.github.io/blog/2014/03/11/frequentism-and-bayesianism-a-practical-intro/

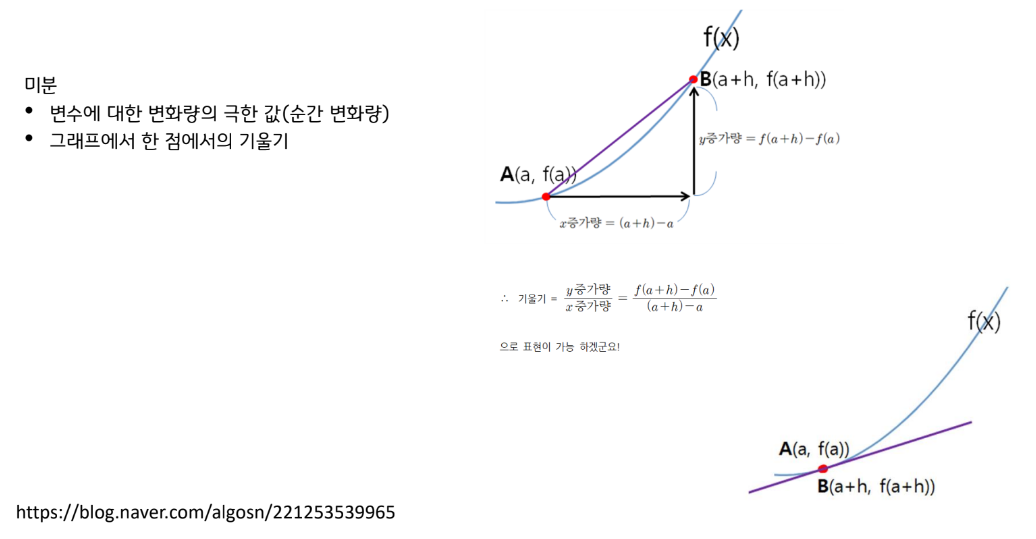
미분
머신러닝 기초
귤 익은 것 분류하기 - 로봇
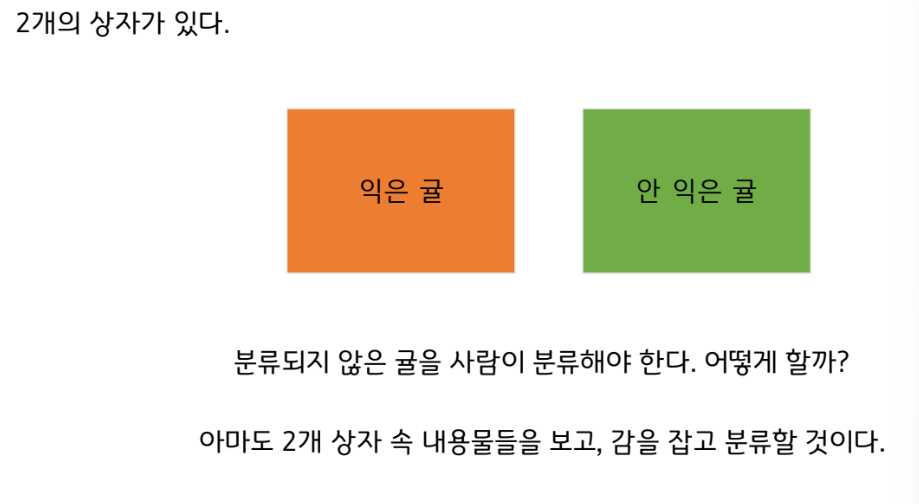
로봇을 위한 프로그램을 작성해야 한다.
‘xxx하면 우측 상자에, 그렇지 않은 경우 좌측 상자에’
분류할 때 사용할 기준을 하드 코딩해야 한다.
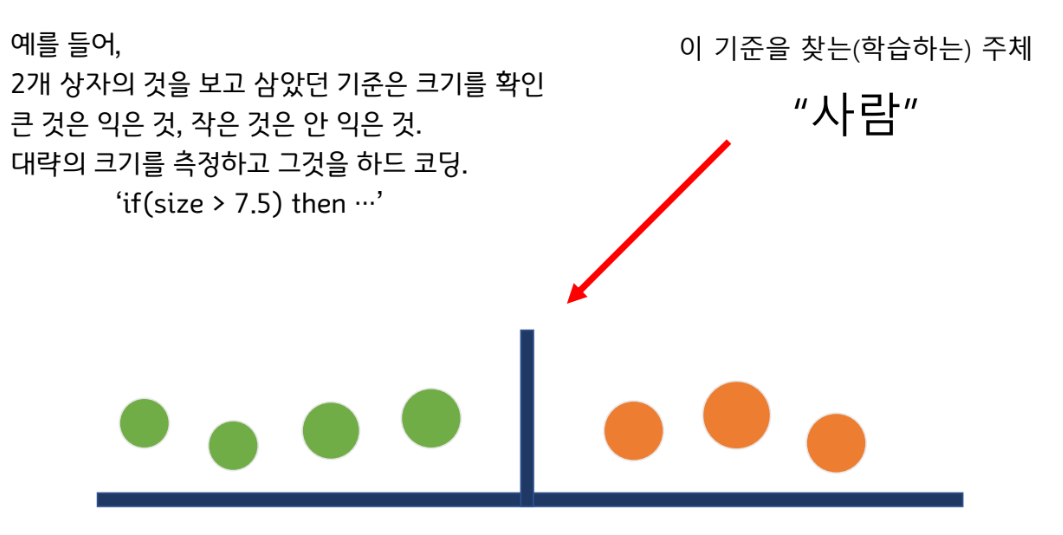
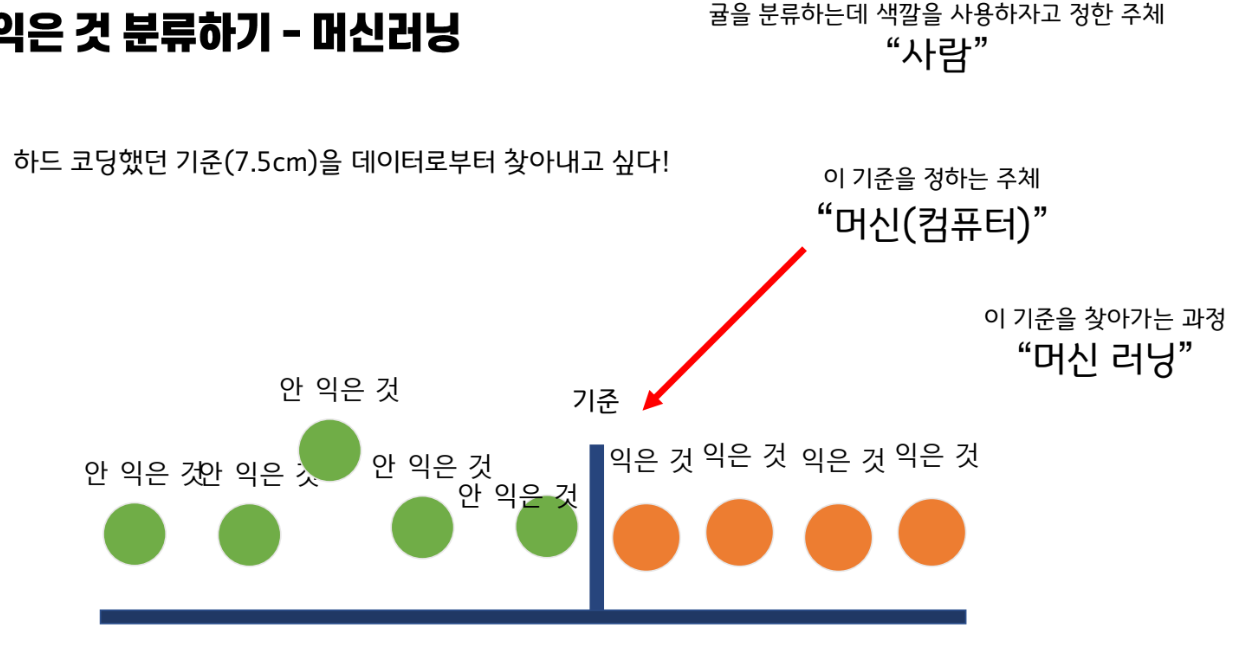

컴퓨터가 학습을 한다?
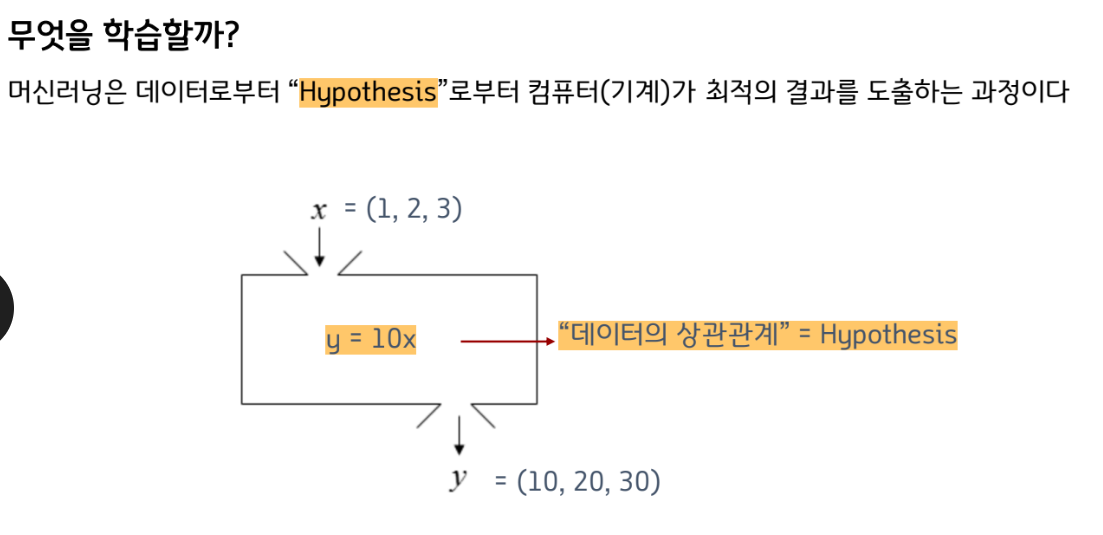
Hypothesis를 잘 찾는 것이 핵심!
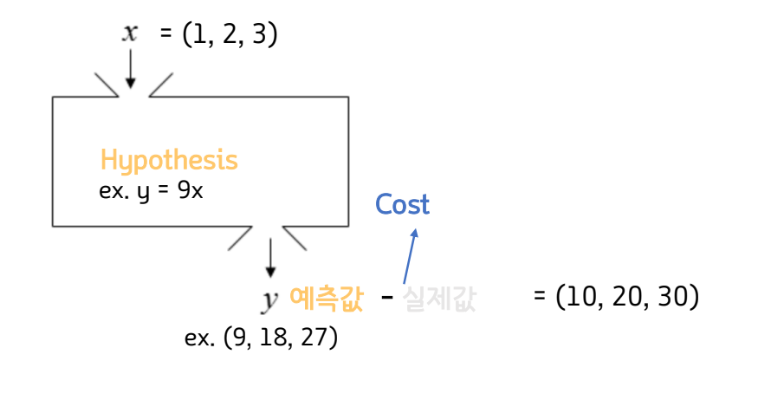
Hypothesis 는 머신러닝의 목적이고,
Cost는 가설과 결과의 차이이고
Hypothesis의 평가/비교 지표가 된다.
머신러닝의 목적은
Cost가 낮은 Hypothesis를 찾는 것이다!
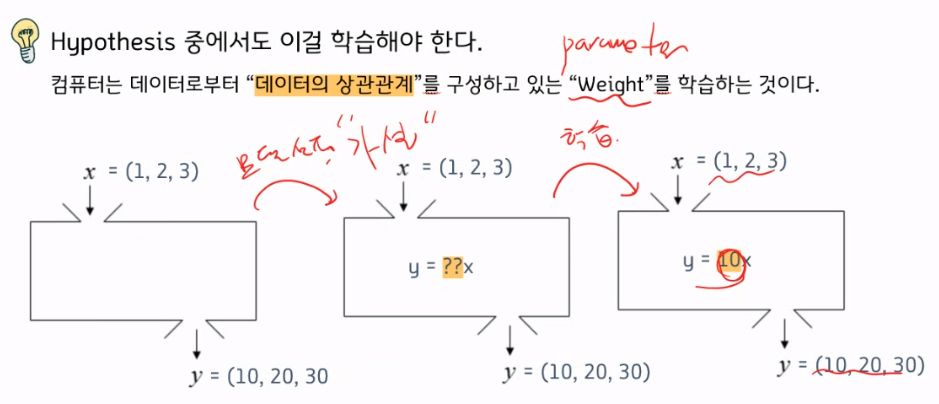
데이터의 상관관계를 찾는 과정은 사실 2단계로 나뉜다.
사실, x와 y의 관계가 y=ax+b 정도의 식으로 찾겠다는 전제는 사람이 정하는 것이고,
그 전제 아래 미지수인 a와 b를 기계가 찾는 것이다.

한마디로

지도학습 비지도학습
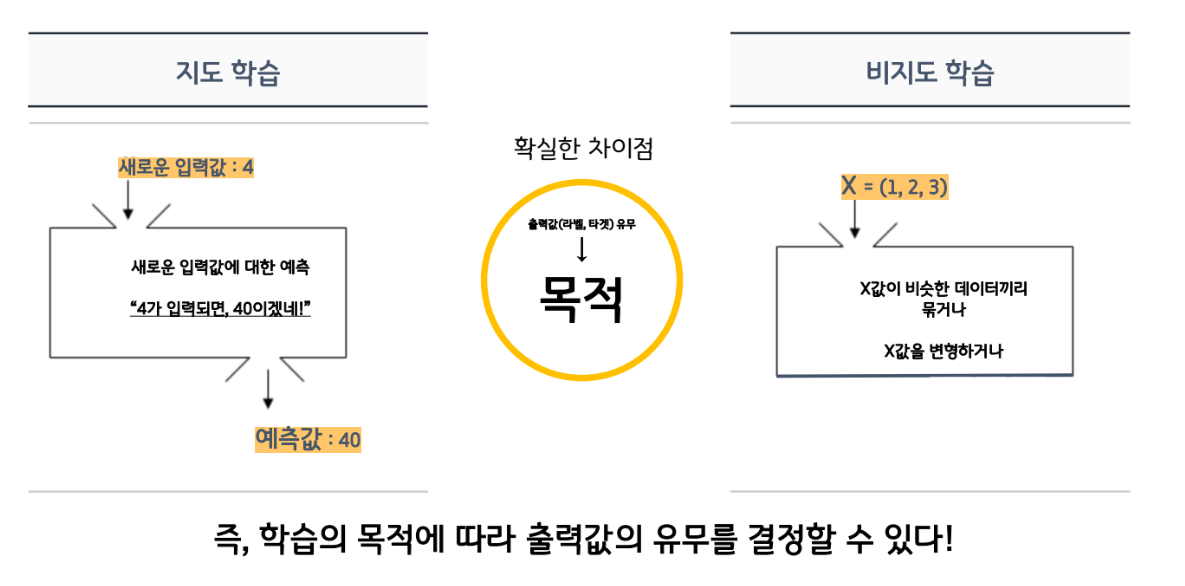
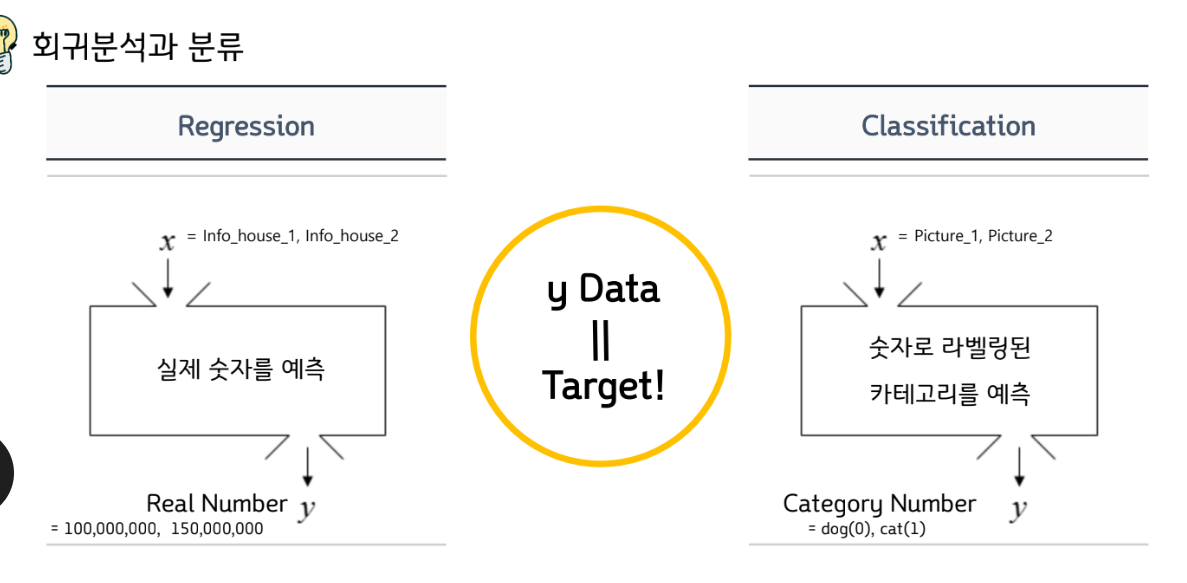
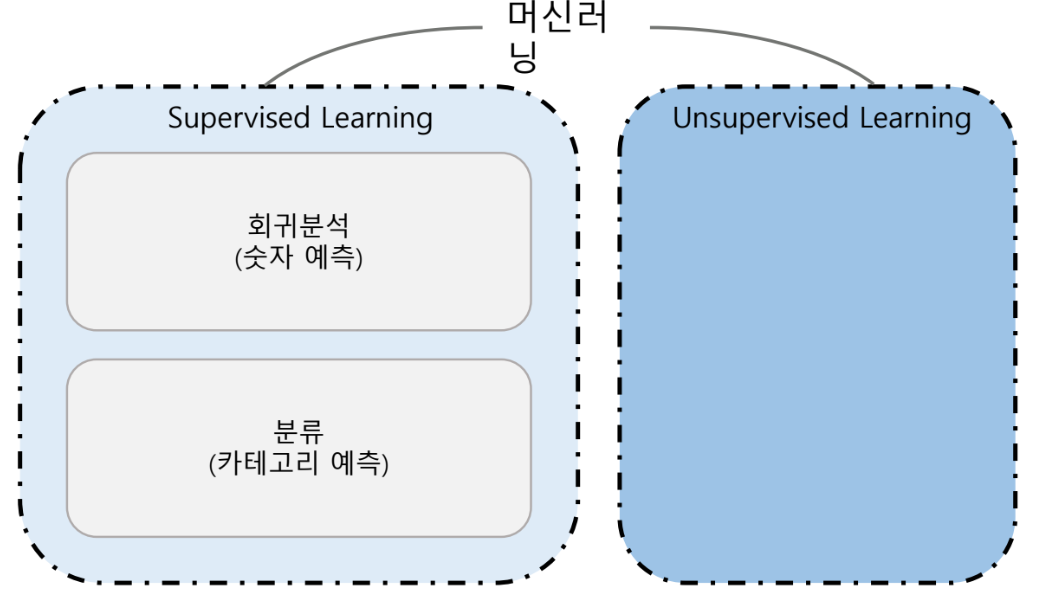
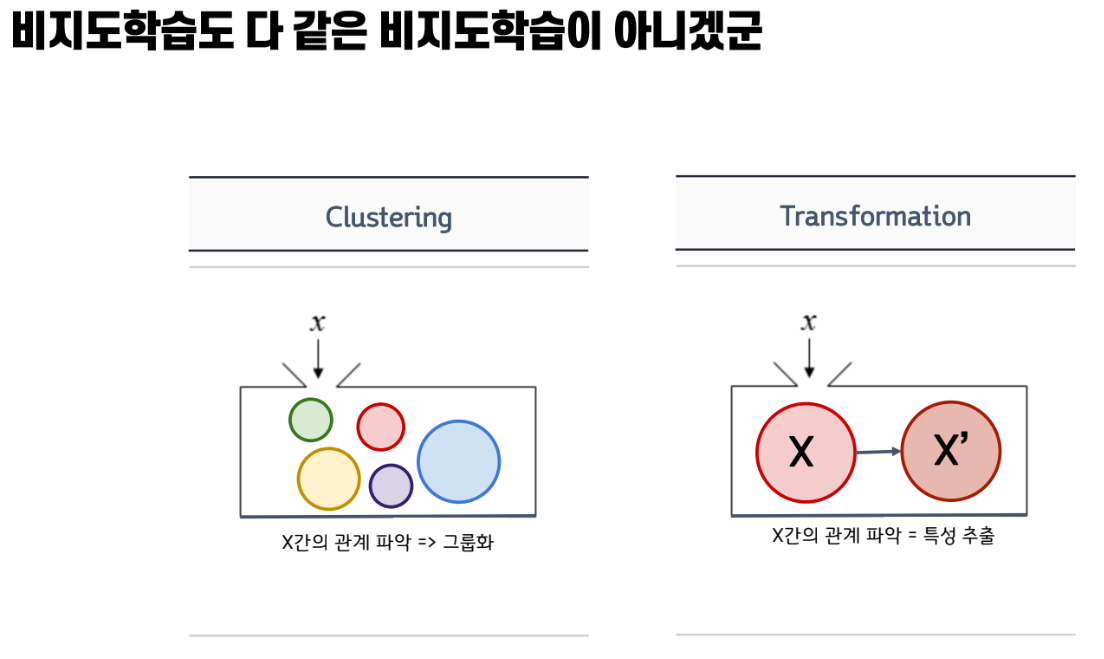
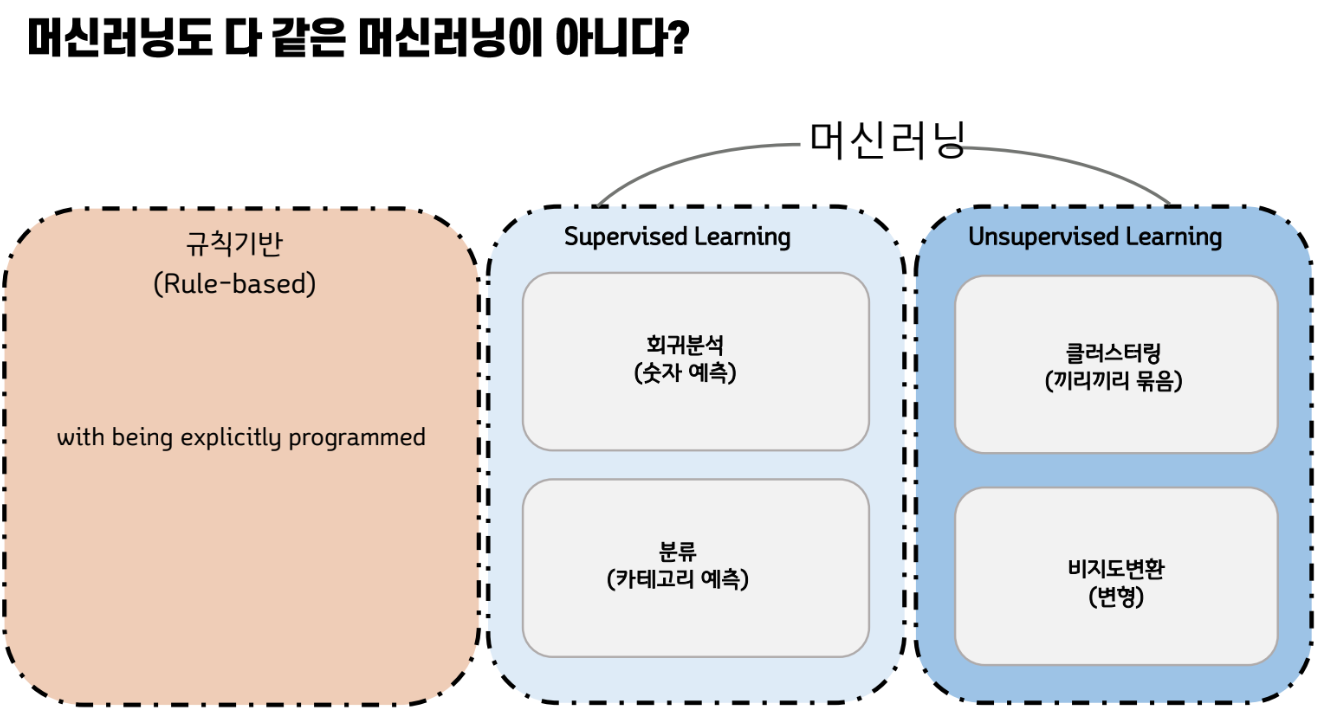
컴퓨터를 어떻게 학습시키나
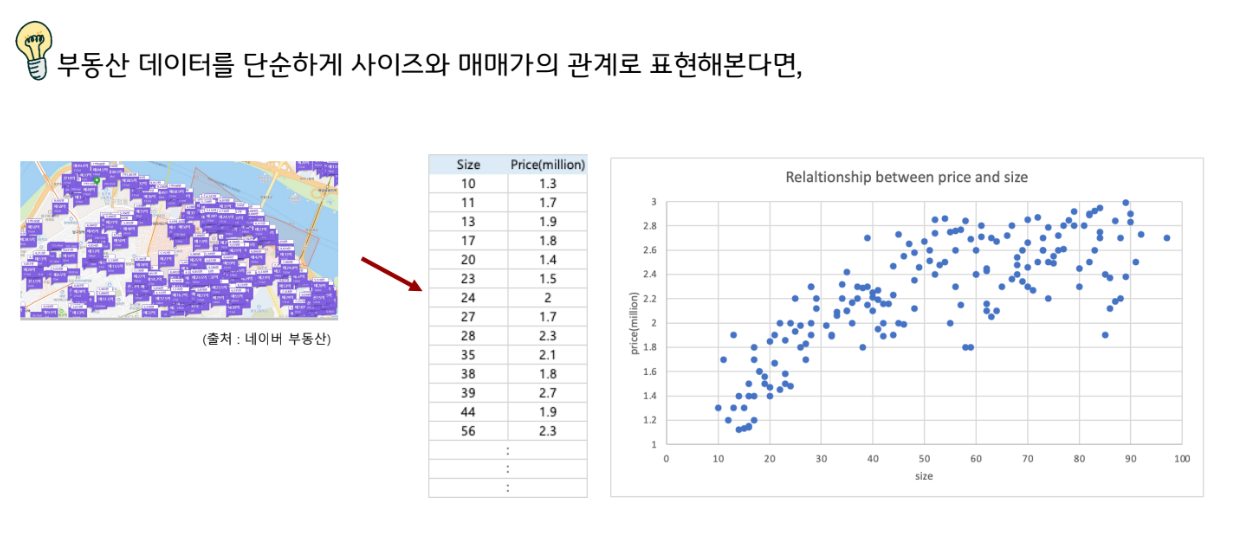
사이즈와 매매가의 관계를 최대한 단순하게 직선으로 찾는다면?
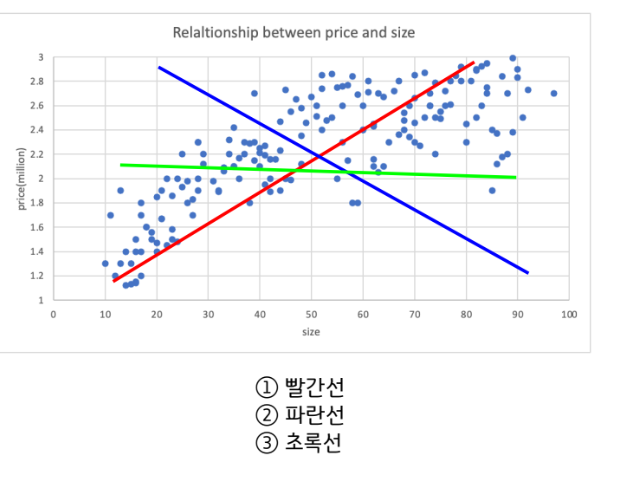
당연히 1번. 빨간선을 고를 것입니다. 그것도 단번에 말입니다. 그런데...
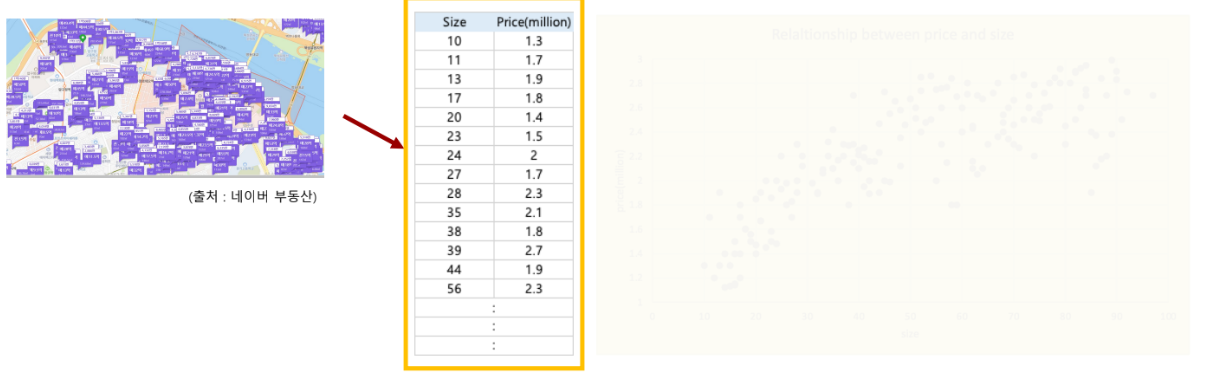
산점도가 아니라 숫자로 이루어진 테이블을 보고 상관관계를 찾아야 된다면?
조금 전에 봤던 빨간선을 생각해낼 수 있나요?
그럼 이 상황에서 사이즈와 가격의 적절한 상관관계를 어떻게 찾을 수 있을까요?
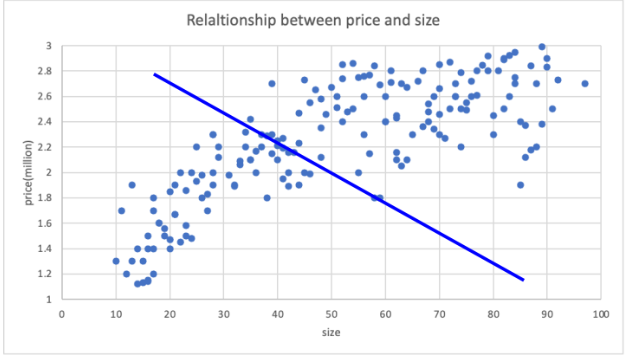
알 수 없기에, 우선 임의로 상관관계를 결정해봅니다. (물론 정확성은 포기하구요.)

그림으로 다시 예제를 표현해보겠습니다. 자, 첫번째 상관관계를 결정해봤습니다.
이를 두고, “상관관계의 초기값을 설정했다"라고 말합니다.
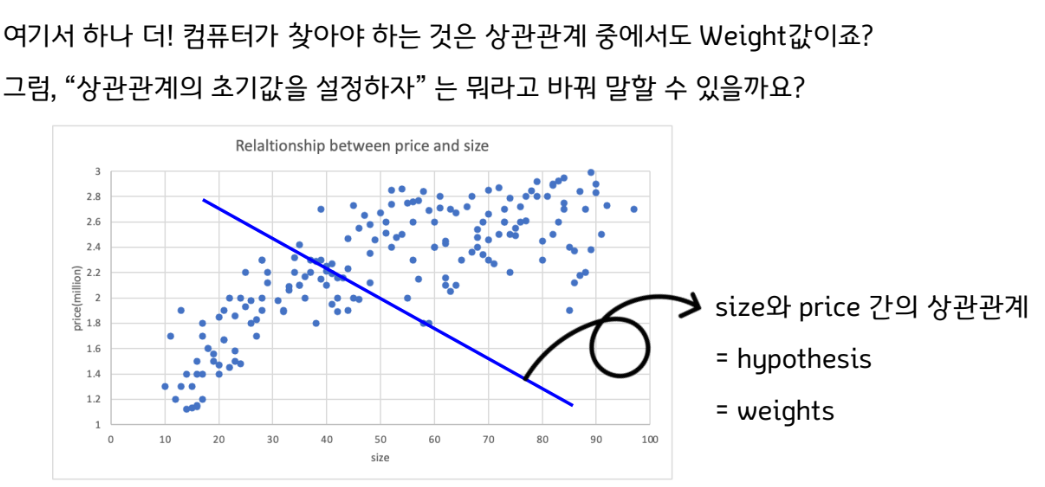
정리합니다. 컴퓨터를 어떻게 학습시킬까?
1단계! Weights의 초기값을 설정합니다.
2단계! 예측값과 실제값의 차이(COST)를 계산합니다.
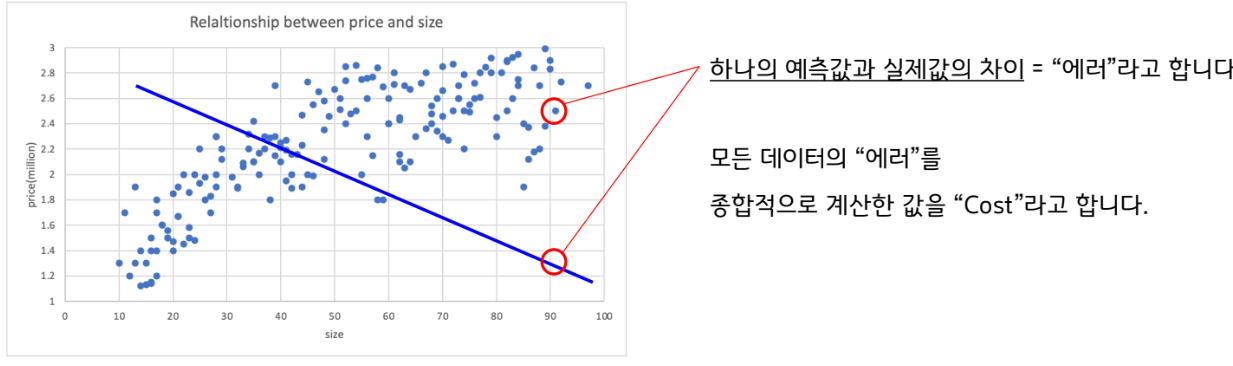
3단계, Cost가 가장 낮아질 때까지 weights 업데이트를 반복합니다.
업데이트를 반복한다고 하여 이를 두고, “반복 계산법"이라고도 부릅니다.
이 과정에서의 핵심은
“어떻게 Cost가 낮아지는 방향으로 weights를 업데이트하냐”는 것입니다.
초기값보다 Cost가 작은 weights를 찾는 방법을 알아봅시다.

예를 들어봅시다.
기울기가 +3이란 의미는 뭘까요?

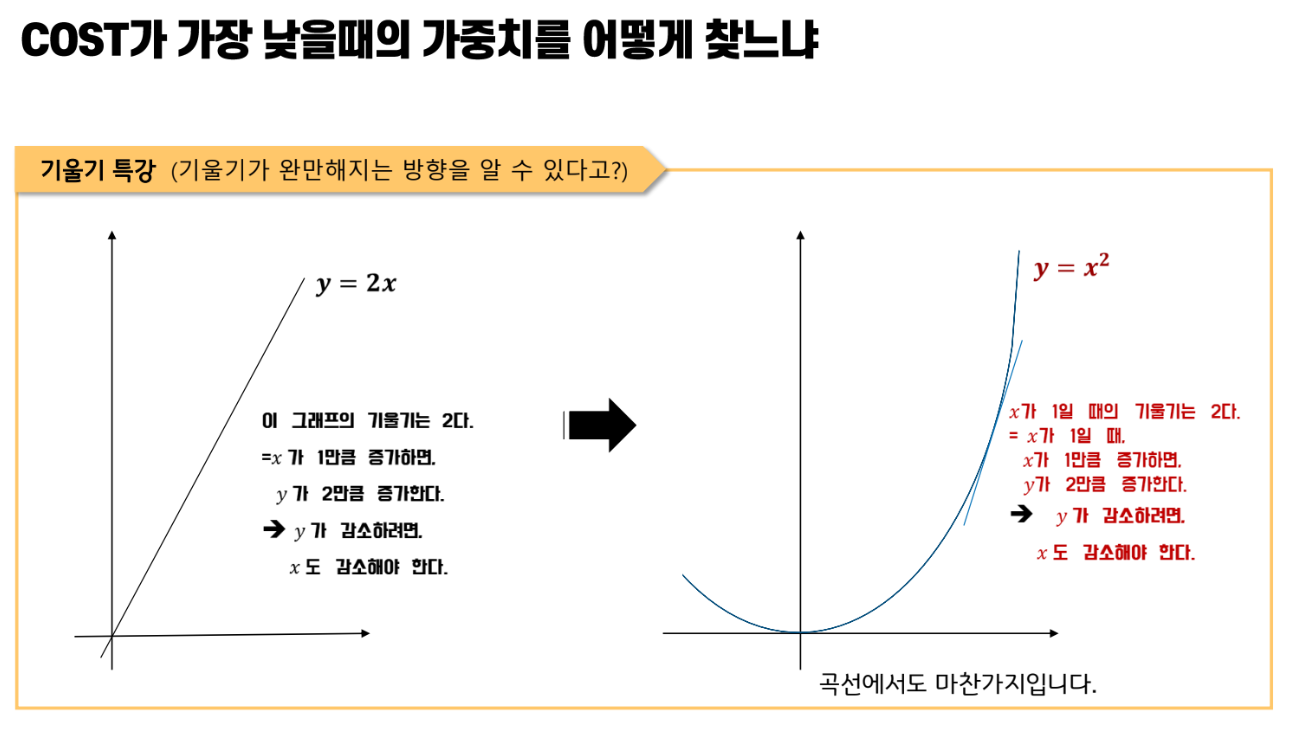
정리

그런데, 기울기값이 weights값보다 훨씬 큰 경우가 있기 때문에
다음과 같이 기울기값에 매우 작은 수를 곱해서 빼준다. (이 매우 작은 수를 learning rate이라고 부른다.)
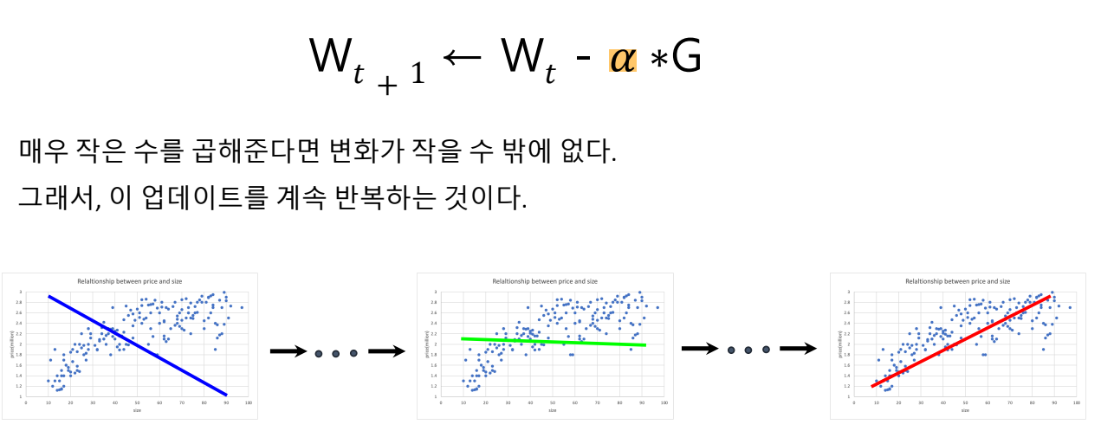
이를 weigh에 대한 Cost 함수의 그래프로 설명해보겠습니다.
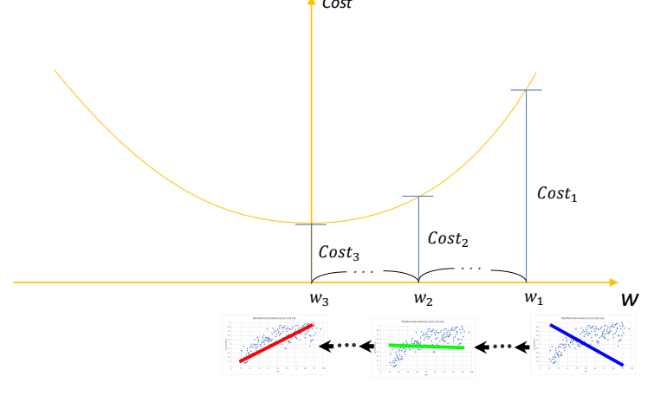
weights를 업데이트하다 보면, Cost함수의 기울기도 완만해지는 것을 알 수 있습니다.
결국, 기울기가 0이 되면 업데이트를 더 이상 하지 않게 되는 것도 알 수 있죠.
그래서 이 방법을 “기울기 하강법(Gradient Descent Algorithm)”이라고 부릅니다.
0단계 : Hypothesis 폼을 정한다.
1단계 : Weights 초기값 설정 (최적의 weights를 한번에 찾을 순 없으니까)
2단계 : Cost 확인
3단계 : Wt+1 ← Wt − α ∗ Gradient
∗ Gradient : 기울기 = w의 변화량에 대한 Cost의 변화량
Cost가 낮아지려면 W가 어떻게 변화해야 하는지 방향을 알려준다.
어떻게 컴퓨터가 데이터로부터
정확한 데이터의 상관관계를 찾는가?
Wt+1 ← Wt − α ∗ Gradient
어떻게 성능을 향상시킬까
머신러닝 성능의 문제는 크게 두가지다.
1) 오버핏 (Overfit)
2) 언더핏 (Underfit)
➔ 위 두 문제는 결국 한마디로 정리할 수 있다.
“데이터의 복잡도와 모델의 복잡도의 부조화”
그럼 이 문제는 어떻게 해결해야 되겠는가?
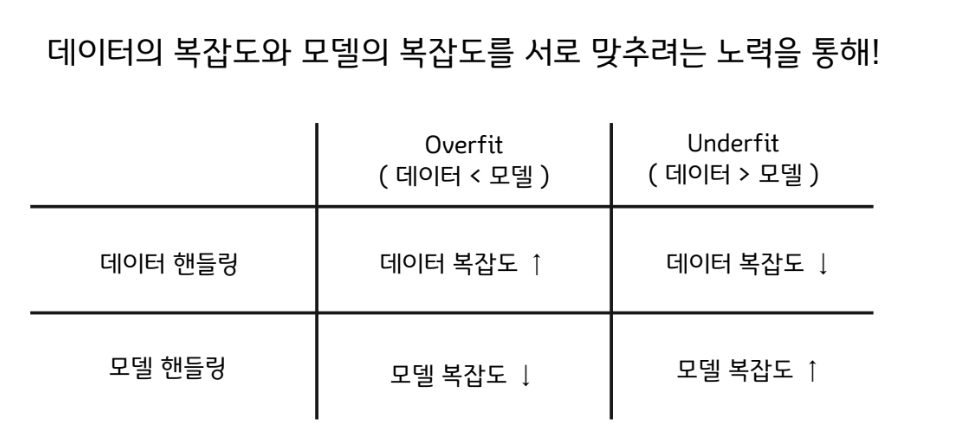

아주 유익한 내용이네요!