분류 문제와 분류 모델
분류(Classification)의 사례
- 이메일 분류 : spam or ham
- 종양 분류 : 악성 or 양성
Classification model의 경우, 분류 방식에 따라 다음과 같이 모형을 나눌 수 있다.
확률적으로 예측하느냐 vs 비확률적으로 예측하느냐
확률적 모형 vs 판별(비확률적) 모형
선형적으로 예측하느냐 vs 비선형적으로 예측하느냐
선형 모형 vs 비선형 모형
SVM
어떤 문제를 푸는 지에 따라 f(X)의 역할이 달라진다.
분류 모델 :
2개의 카테고리 데이터를 분류하는
선형 Decision Boundary를 찾는 것이 목적!
회귀 모델:
데이터를 잘 나타내는 선분을 찾는 것이 목적!
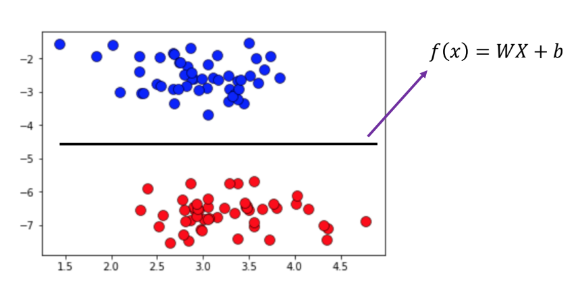
SVM이 생각하는 좋은 경계선의 조건
데이터와 최대한 여백을 두면서 경계선을 그리라고 명령하면 된다.
그 데이터와 경계선 사이의 여백을 “마진”이라고 부른다.
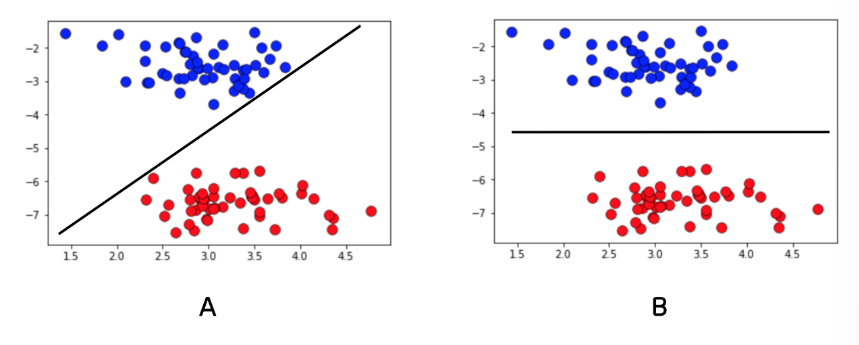
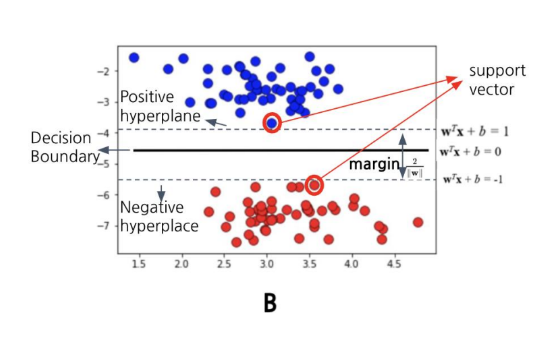
SVM은 이러한 관점에서 시작한다
Decision Boundary(결정 경계)를 선형으로 그
리되, 데이터와 선분의 폭을 크게 하자!
이 선분 폭을 Margin이라 하고,
이 선분과 가장 가까운 데이터,
즉 Margin을 결정하는 기준이 되는 데이터를
Support Vector라 한다.
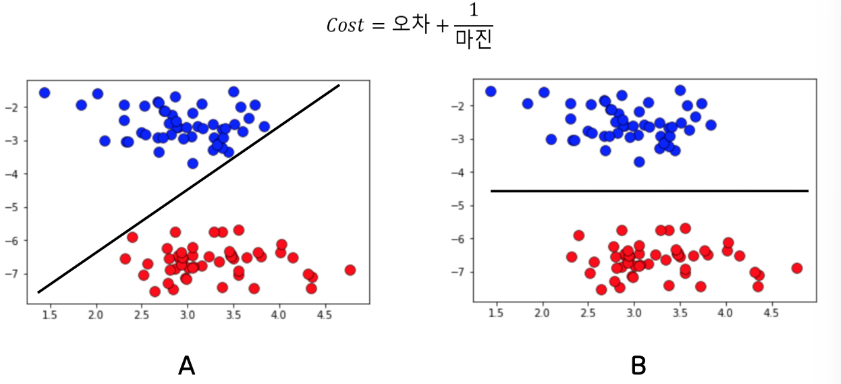
아래 식과 같이 Cost를 구성하면, A와 B가 모두 오차는 0이지만, A가 마진이 더 작기 때문에
총 Cost는 높게된다. 그럼, A에서 만족하지 않고, B까지 학습할 수 있게 되는 것이다.
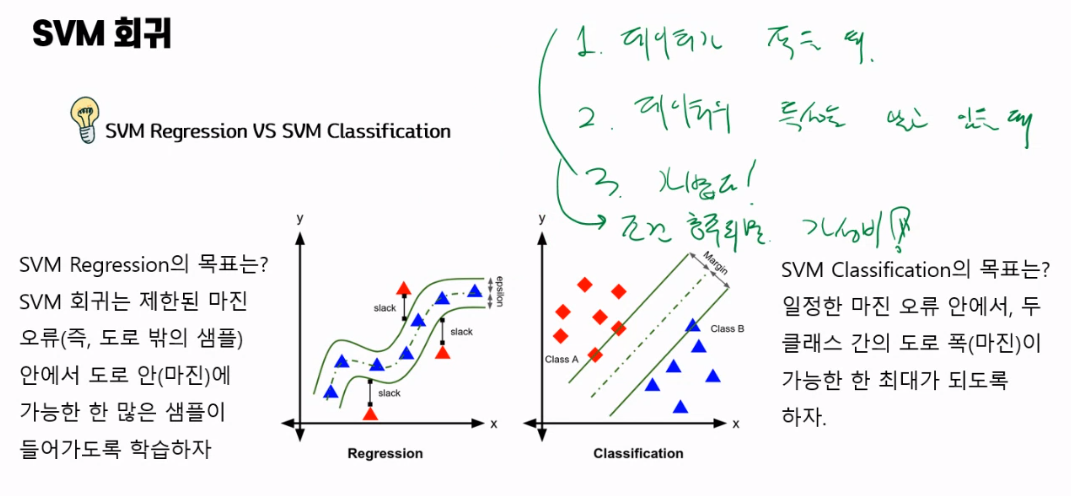
SVM 회귀

어떻게 오셨나요