분류 문제와 분류 모델
- 이메일 분류 : spam or ham
- 종양 분류 : 악성 or 양성
Classification model의 경우, 분류 방식에 따라 다음과 같이 모형을 나눌 수 있다.
분류(Classification)의 사례
확률적으로 예측하느냐 vs 비확률적으로 예측하느냐
확률적 모형 vs 판별(비확률적) 모형
선형적으로 예측하느냐 vs 비선형적으로 예측하느냐
선형 모형 vs 비선형 모형
Logistic Regression은
확률적 + 선형적모형
확률적 선형 분류 모형의 의미
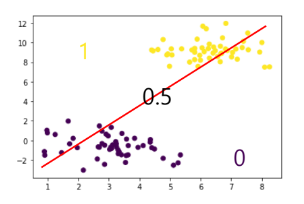
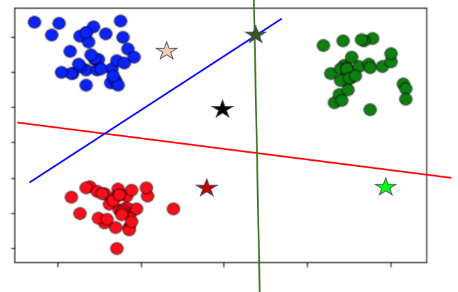
무엇이 선형이라는 걸까?
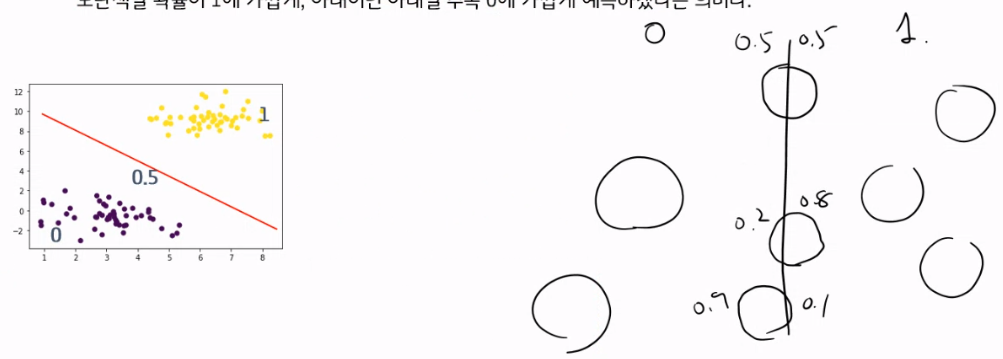
아래의 그림에서, 보라색과 노란색을 ‘구분짓는 경계선’이 선형이라는 의미다!
로지스틱 회귀분석
Hypothesis
로지스틱회귀분석의 예측값은 확률값!
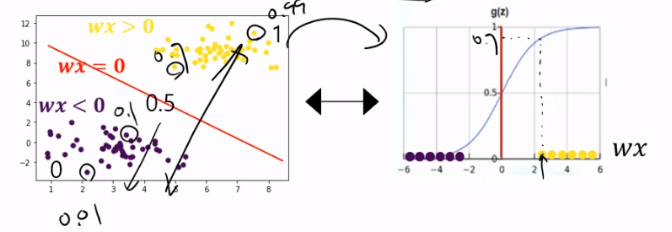
로지스틱 회귀분석의 알고리즘은 크게 두 단계로 나눠 생각할 수 있다.
1 서로 다른 카테고리의 데이터집단을 구분짓는 선형 경계선을 찾는다.
2 선형 경계선을 기준으로 아래 그림과 같이 특정 카테고리일 확률을 예측한다.
“선형 경계선 찾고” → “확률적으로 예측하기”
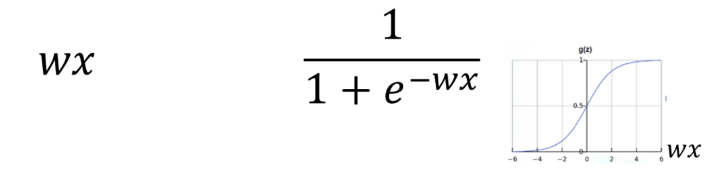
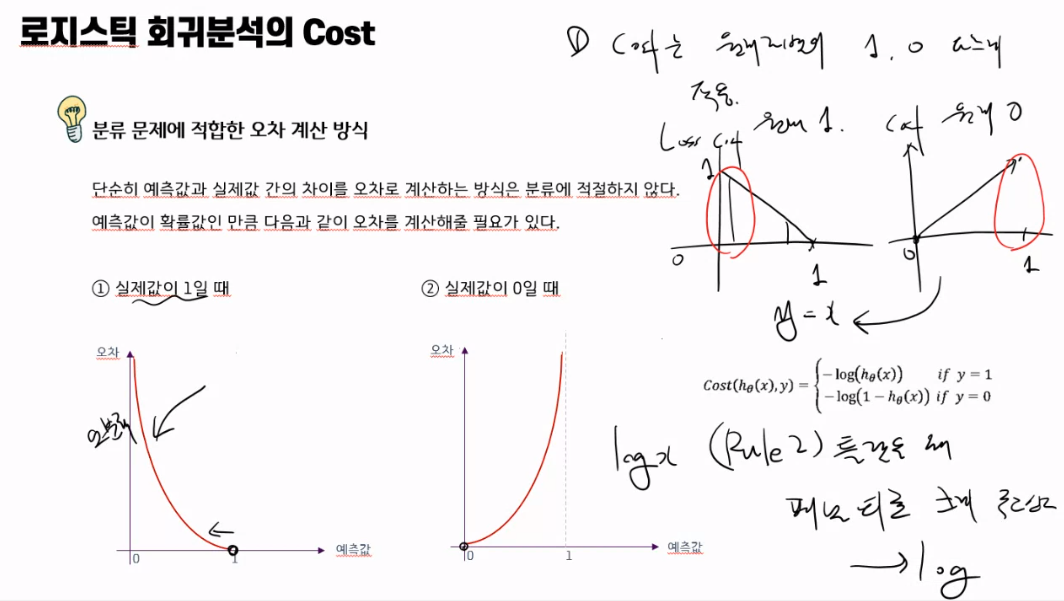
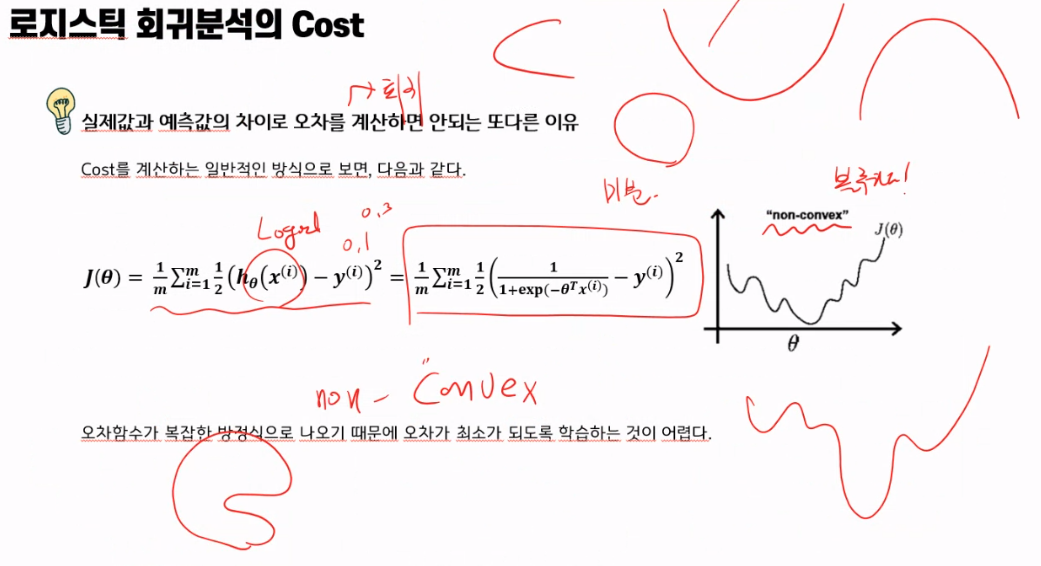
Cost
오차는 항상 0과 1 사이
- 정답은 1아니면 0 이다.
- 예측값은 0~1 사이다.
그럼 다음 두 가지 경우를 비교해보자.
#실제값이 1일때
1 예측값이 0.9일 경우, 그럼 1로 맞췄지만, 오차는 0.1
2 예측값이 0.1일 경우, 0으로 틀렸지만, 오차는 0.9
하나는 잘 맞췄고, 하나는 완전 틀렸지만 오차는 큰 차이가 없다.
이렇게 오차를 계산하면, 학습이 잘 되지 못할 수 있다.
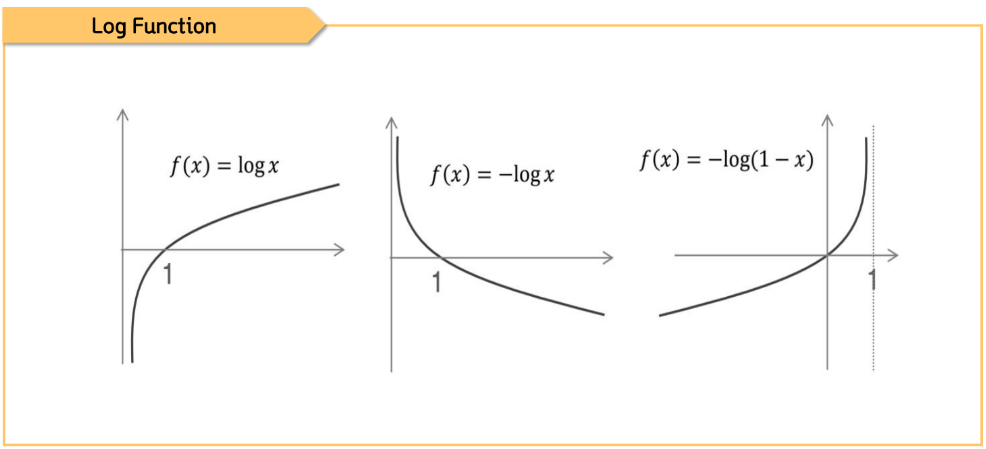
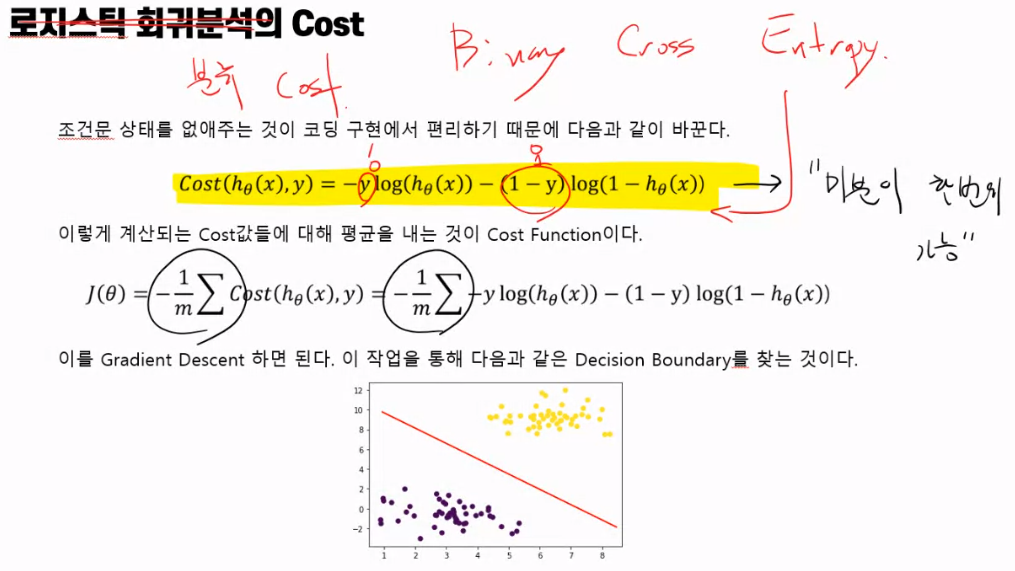
분류 문제에 적합한 오차 계산 방식
단순히 예측값과 실제값 간의 차이를 오차로 계산하는 방식은 분류에 적절하지 않다.
예측값이 확률값인 만큼 다음과 같이 오차를 계산해줄 필요가 있다.
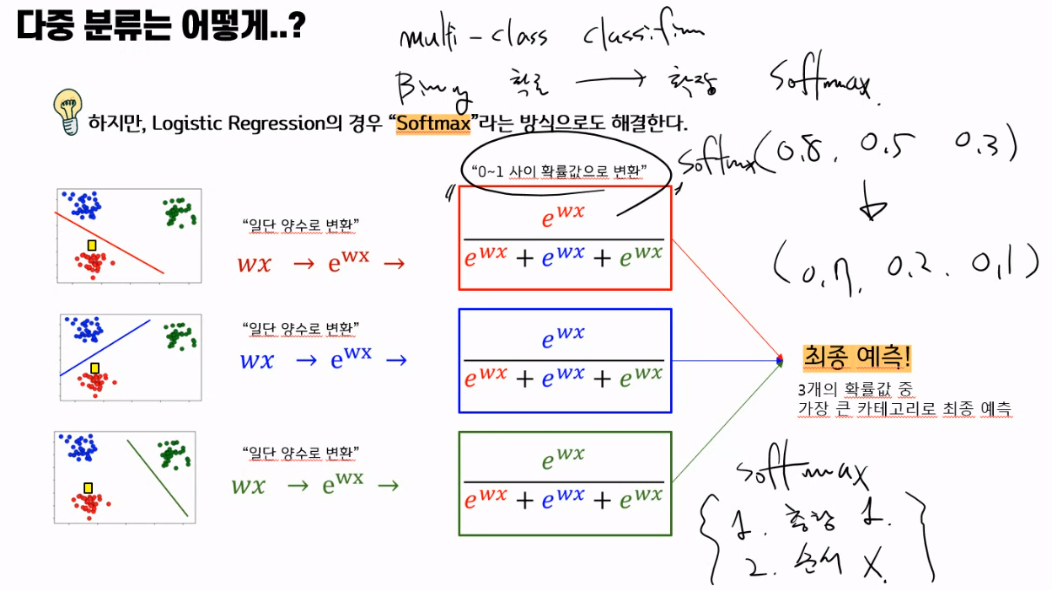
다중 분류는 어떻게?
일반적으로 선형 분류 모형의 경우,
“일대다 방식”으로 다중 분류문제를 해결한다.
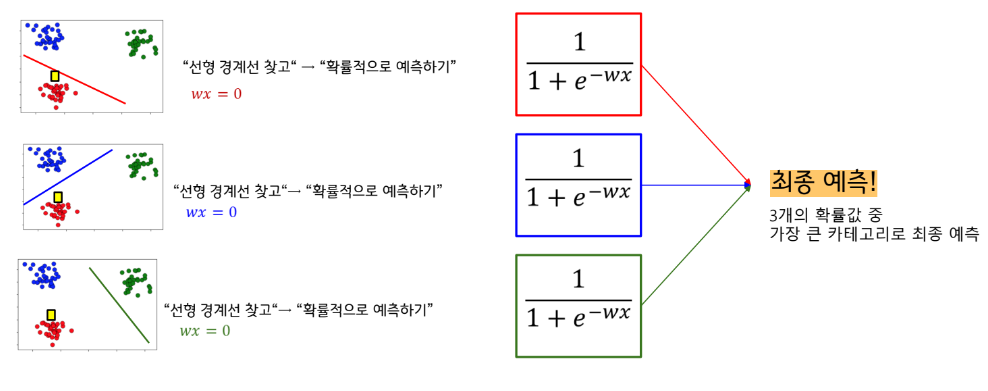
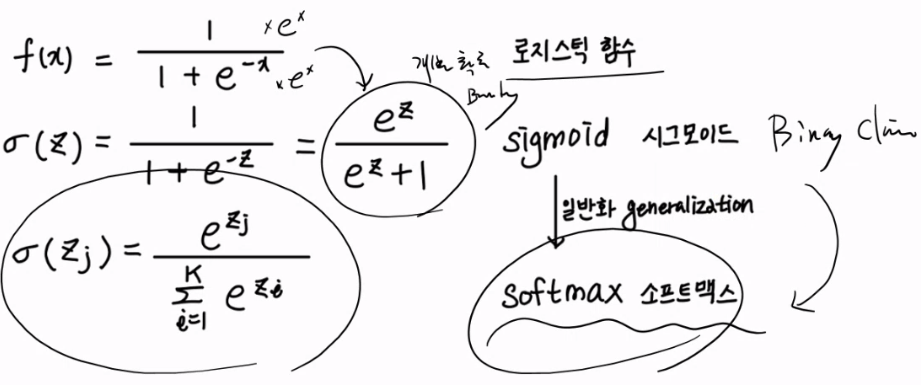
하지만, Logistic Regression의 경우 “Softmax”라는 방식으로도 해결한다.
분류모델의 평가
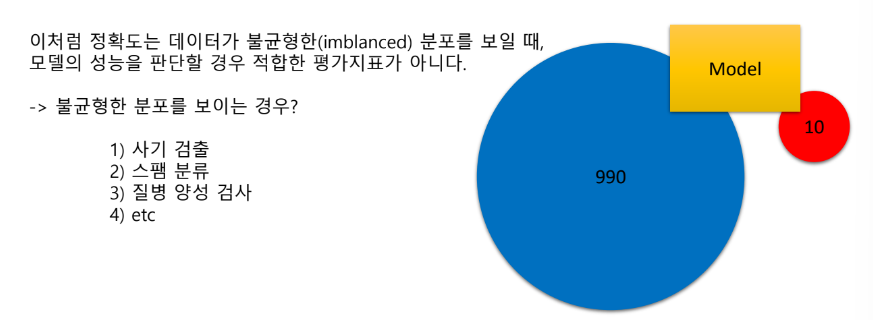
이렇게 분류 모델을 완성했다. 이 모델을 사용해도 되는지 개선이 필요한지는 어떻게 평가할까?
목표 : 실제 데이터와 예측 결과 데이터가 얼마나 정확하고 오류가 적은가.
정확도 (Accuracy)
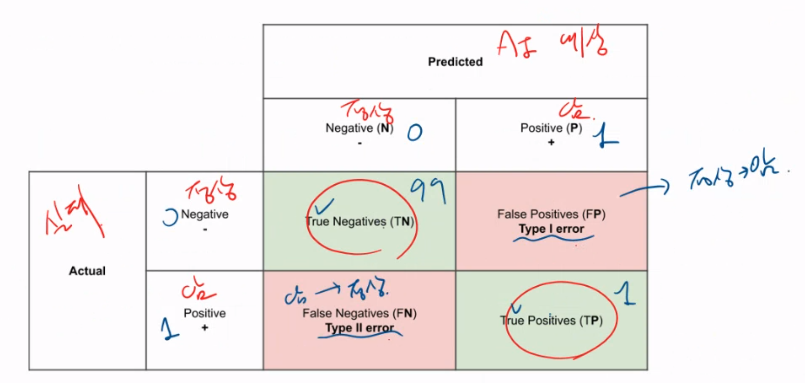
오차행렬 (Confusion Matrix)
정밀도 (Precision)
재현율(Recall)
F1 Score
*ROC AUC
어떤 상황에서 어떤 데이터로 어떤 목적이냐에따라 평가 기준이 다름
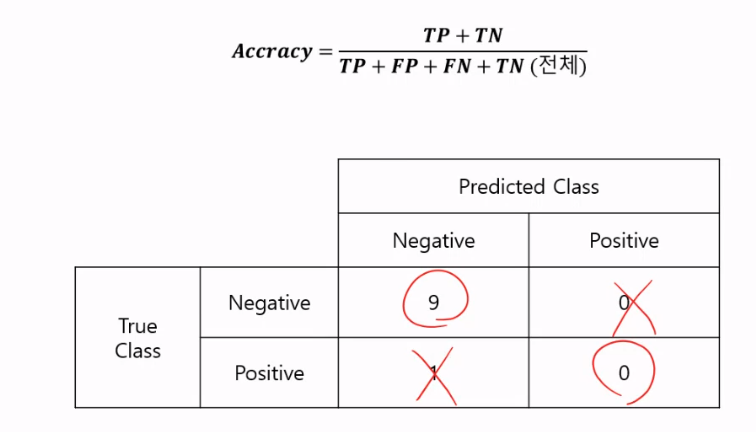
정확도(Accuracy)
정확도 = 전체 중 모델이 바르게 분류한 비율
오차행렬(Confusion Matrix,혼돈행렬)
학습된 분류모델이 예측을 수행하면서 얼마나 헷갈리고 있는가
-> 즉 모델의 예측 오류가 얼마인지와 더불어 어떠한 유형의 예측 오류가 있는지를 함께 보여주는 지표
정밀도 : 모델이 Positive라고 분류한 것 중에서 실제 Positive인 것의 비율
-> 날씨 예측 모델이 맑다로 예측했는데, 실제 날씨가 맑았는지
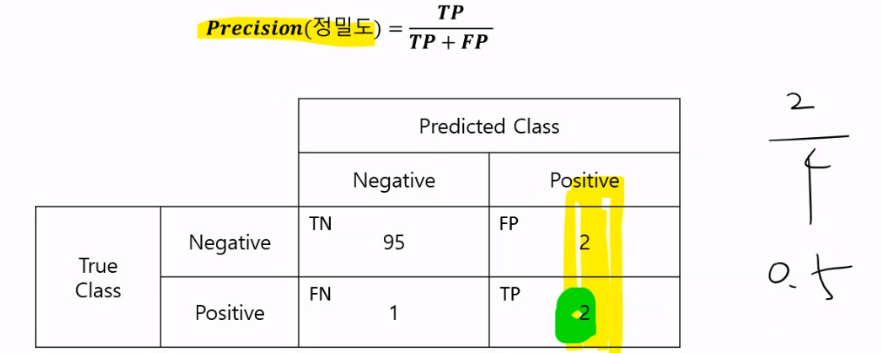
재현율 : 실제로 Positive 인 것 중에 모델이 Positive라고 예측한 비율
-> 실제 맑은 날들 중 모델이 맑다고 예측한 날의 비율

재현율 중요한 지표인 경우
실제 Positive를 Negative로 잘못 판단하면 큰 영향을 미치는 경우
Ex ) 암 환자, 사기 판단
Recall(재현율) =
TP
TP + FN
정밀도이 중요한 지표인 경우
실제 Negative 데이터를 잘못 예측하여 Positive로 판단하면 큰 영향을 미치는 경우
Ex ) 스팸 메일 판단
Precision(정밀도) =
TP
TP + FP
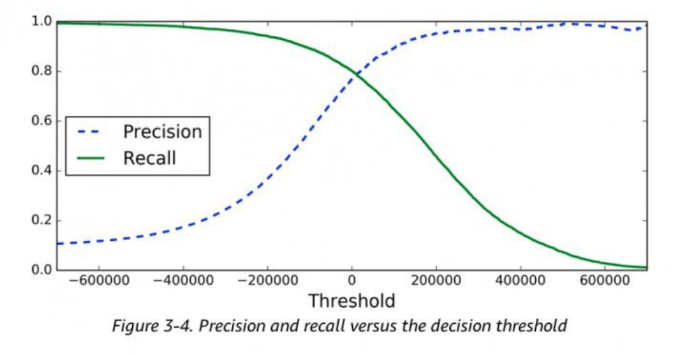
정밀도와 재현율 트레이드 오프
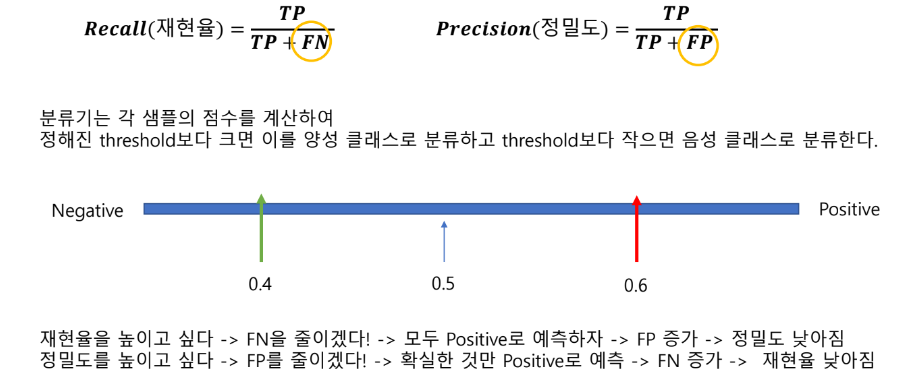
따라서 둘 중 하나만 참고하면 극단적인 수치 조작이 될 수도 있어, 두 수치를 적절하게 조합하여 분류의 종합적인성능평가에 사용되어야 함
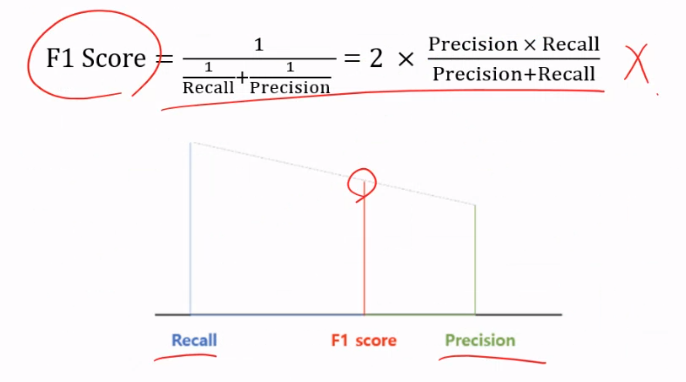
F1 Score
F1 Score : Precision과 Recall의 조화평균
정밀도와 재현율이 어느 한쪽으로 치우지지 않을 때 상대적으로 높은 값을 보임