이전까지 진행사항
: understat 모듈을 사용해서 진행하기로 결정
이번 주에 주제와 데이터를 선정하면서 한 가지 놓친 부분을 깨달았다.
바로 최대로 구할 수 있는 데이터 양이 얼마인지 확인하지 않은 것

문제사항 :
한 시즌 한 프로축구 팀 경기 정보만으로는 데이터 수가 현저히 적어서 진행할 수 없었다.최대 38경기 수집 가능
이에 대한 내용은 내가 했던 중간 발표에 잘 담겨있다.





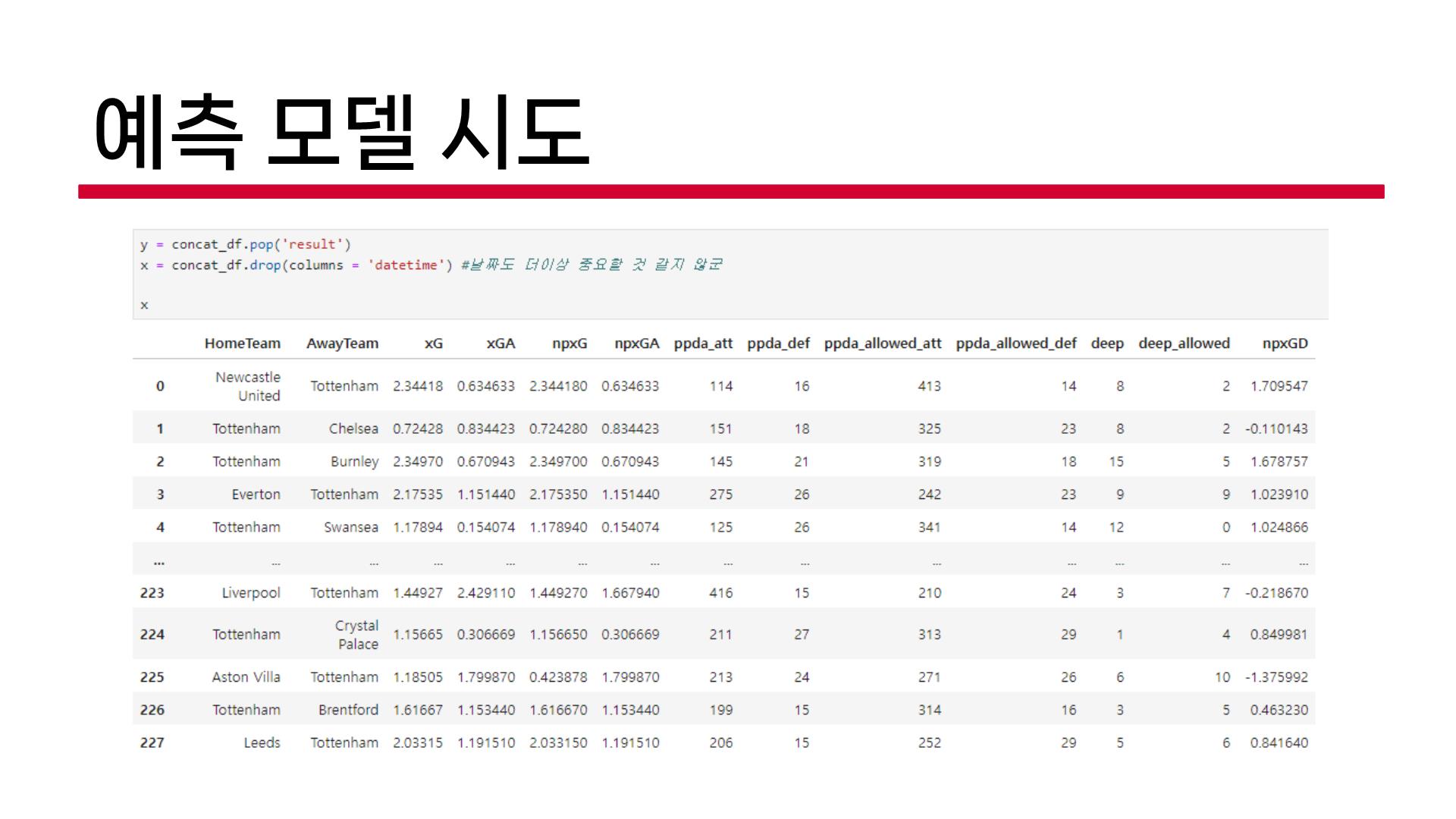
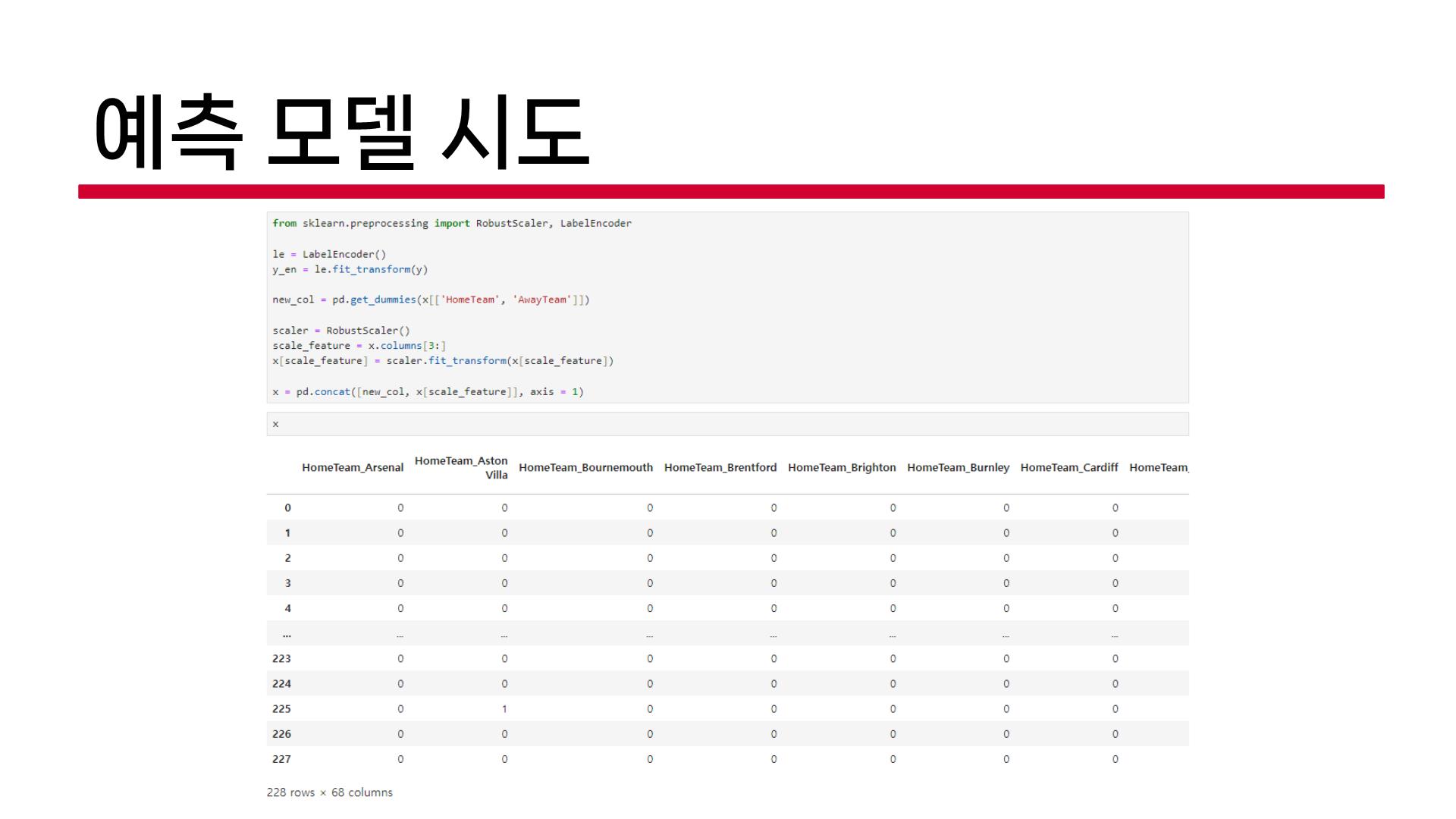


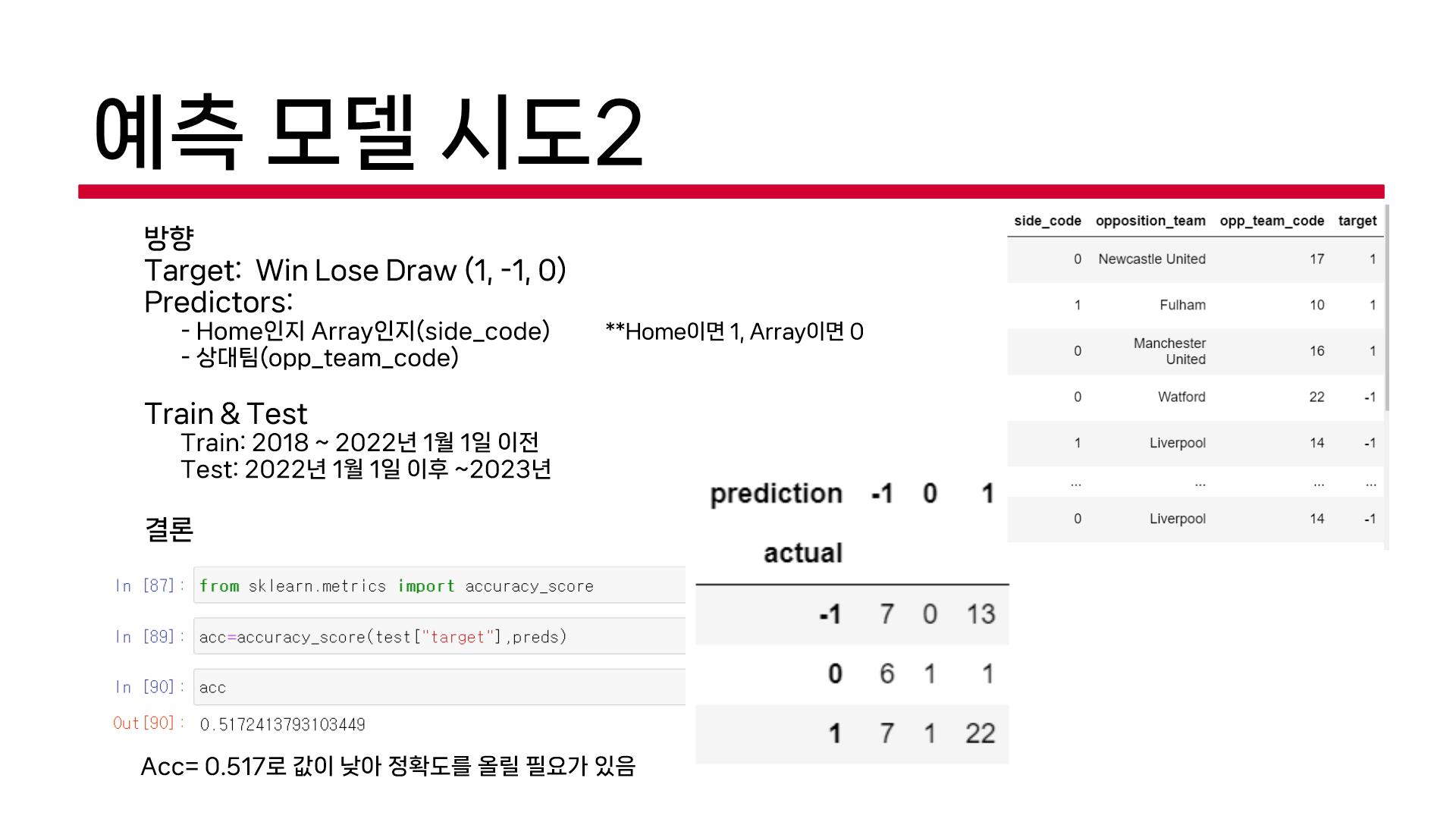

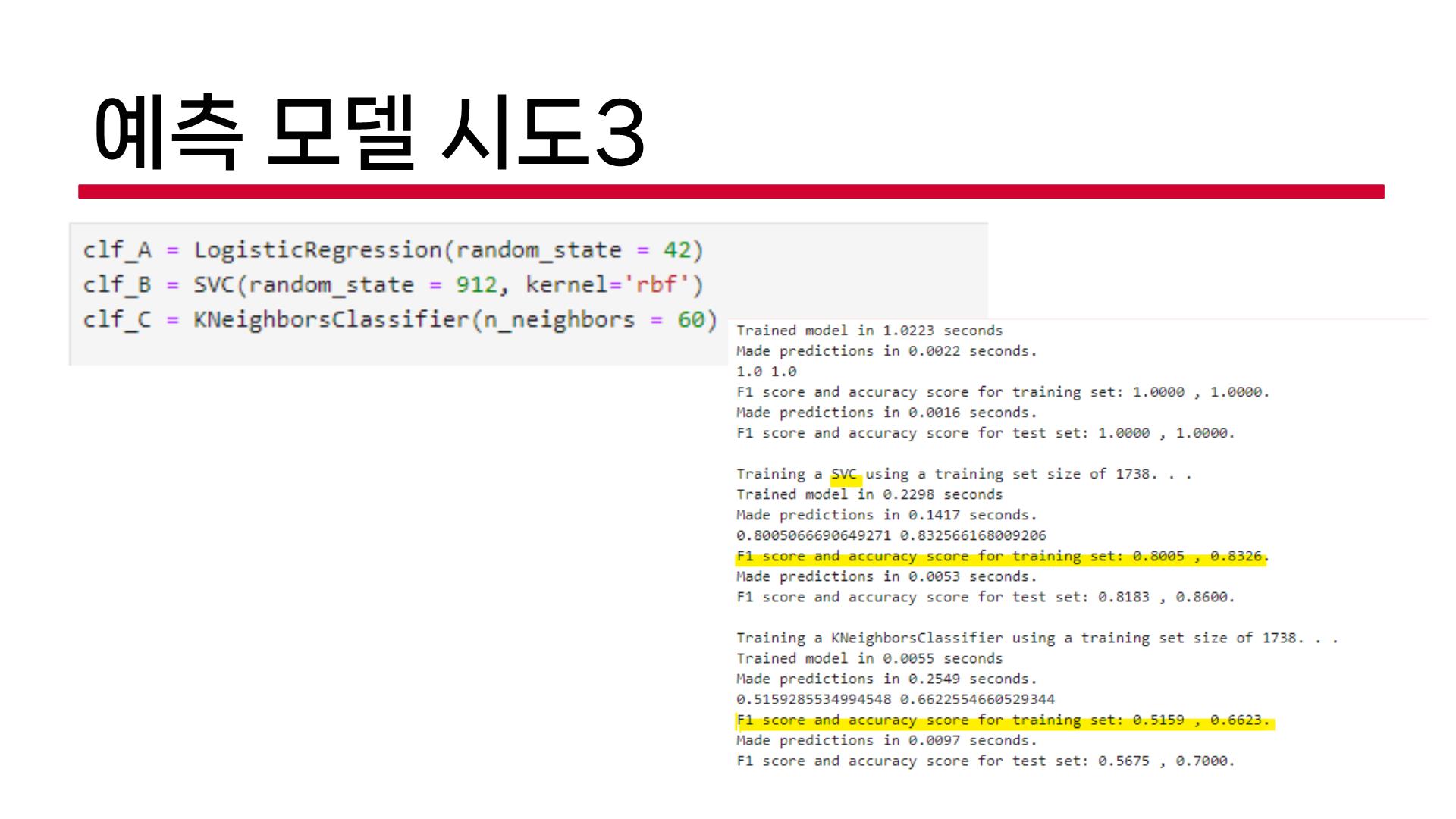
예측모델2, 3은 우리 팀원들이 했던 내용인데, 회의했을 때 느끼는 문제점이 동일했다.
"데이터가 너무 적어...!"
그렇다면 어떻게 하면 데이터를 더 구할 수 있을까?
돌파구 :
1) xG값이 존재하는 17-18 시즌부터 수집해 6시즌으로 작업하기로 진행
2) 전체 프로축구팀 데이터로 데이터분석을 진행해서 도출 (총 2280 경기)
3) 추가 데이터 수집


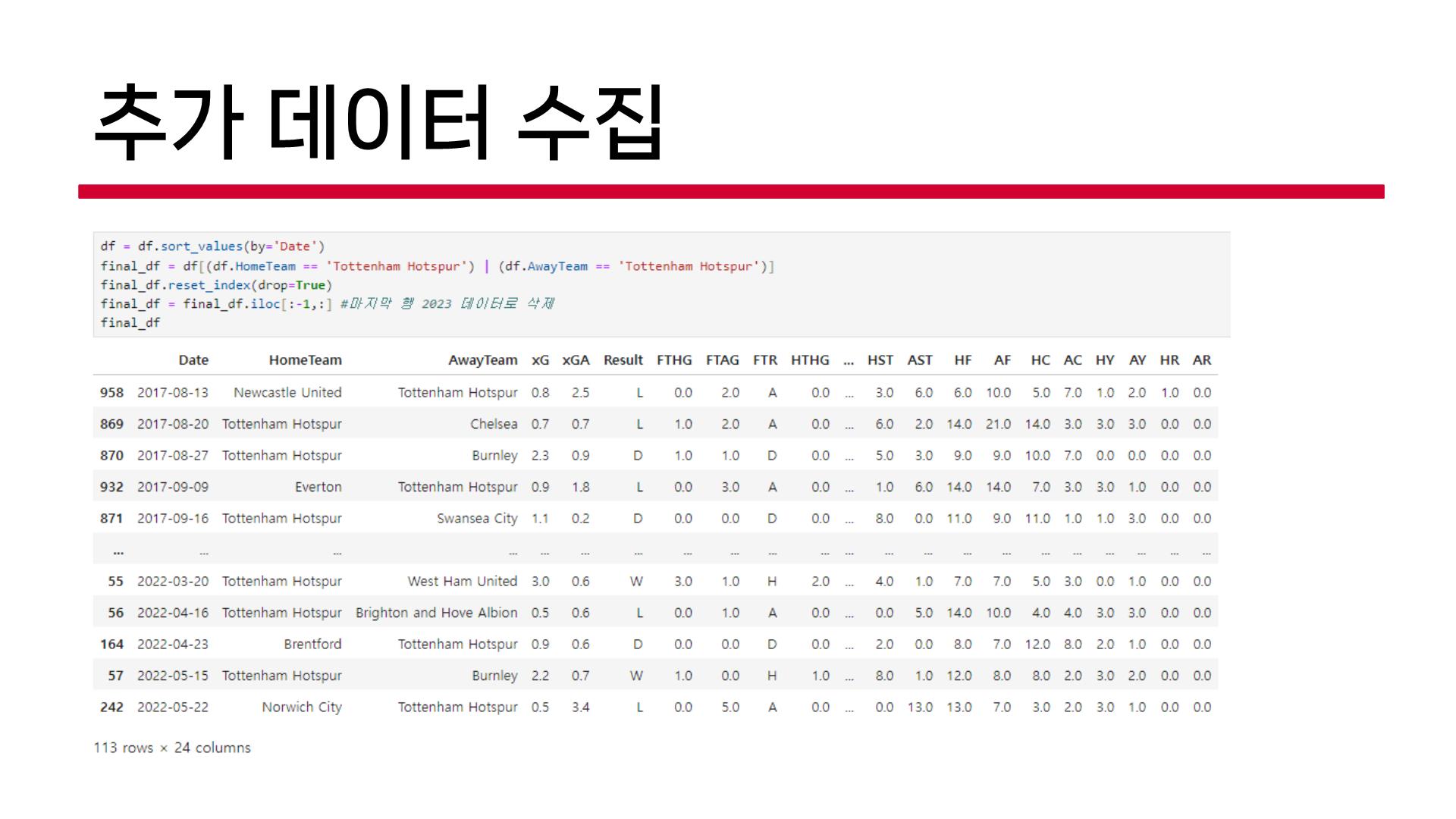

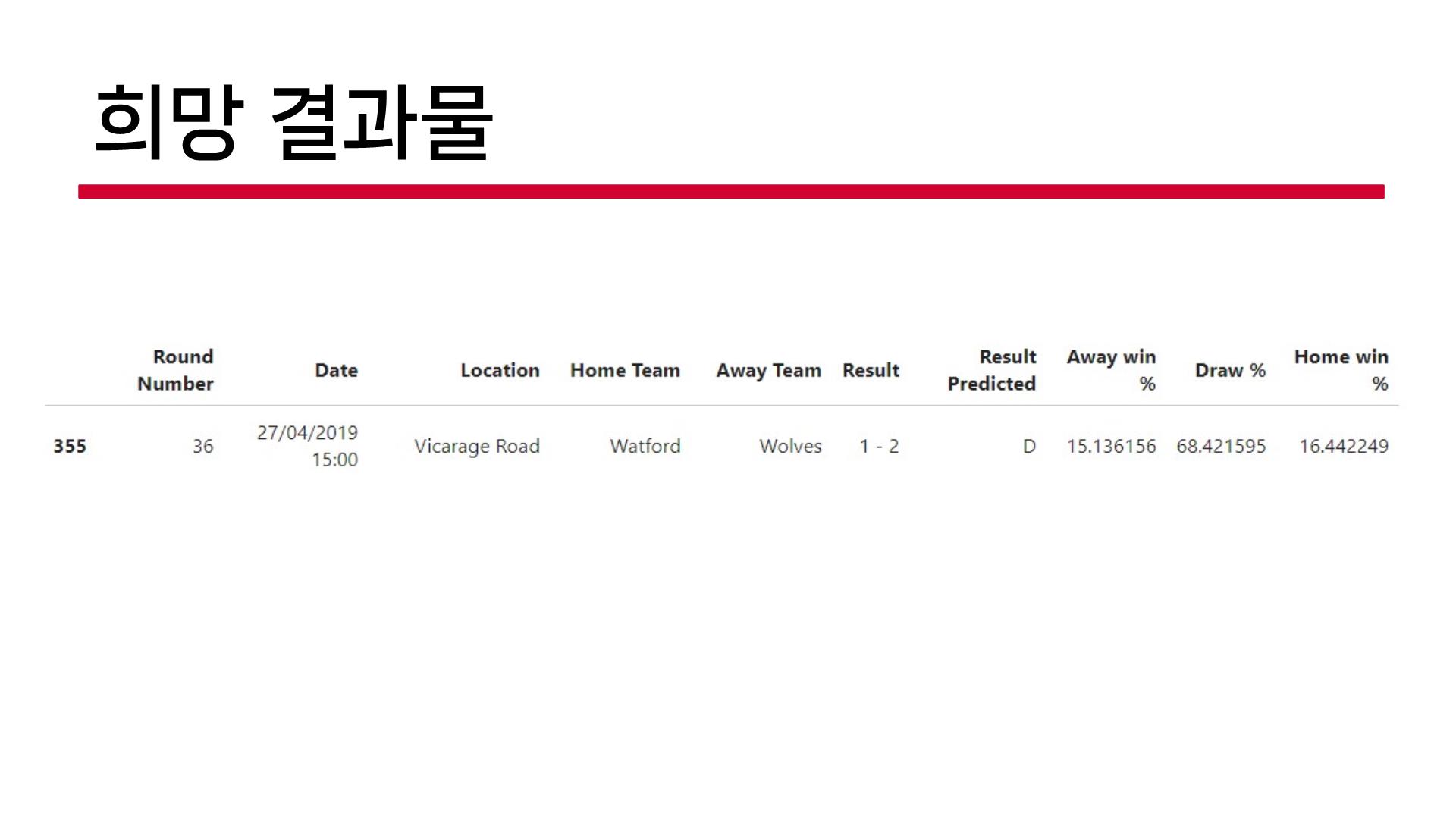
🤔 이미 진행한 입장에서 돌아보면 여기서 데이터 추가 수집에도 문제점이 존재한다. 왜냐하면 이미 경기 수는 한정되어있기 때문에 추가 데이터를 수집한다고 해도 승부를 예측할 수 있는 다양성이 증가될 뿐 학습할 수 있는 데이터가 많아지는 것은 아니므로... 그냥 노가다를 했다고 볼 수 있다. 어쩌면 주제를 변경해야 했어야 했다는 생각이 미쳤다.
하지만 난관으로 팀원들과 함께 고민했을 때 우리는 계속 첫 프로젝트이니 일단 끝까지 해보기로 했다. 여기서 제로베이스에서 내준 과제가 야구 선수 연봉 예측, 축구 승부 예측과 엇비슷한 것인줄 몰랐지만, 여러모로 데이터 수집의 중요성을 알게 되었다.
빅분기랑 공부할 때는 몰랐는데, 전처리 전까지 시간이 이렇게 오래 걸리는 구나.. 데이터 수집으로 2-3주를 보낼 줄 몰랐다 히히...
.
.
🥲 understat json 파일 예쁘게 만드는 것도 오래 걸렸는데! (결국 해내서 행복했다)
understat 으로 뭘 했냐고 물으신다면.. 일부
#2021 시즌 understat에 저장된 토트넘 정보
async def main():
global teams
async with aiohttp.ClientSession() as session:
understat = Understat(session)
teams = await understat.get_teams(
"epl",
2021,
title="Tottenham"
)
teams = pd.DataFrame(teams)
# print(teams)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
print(teams)
#설정한 값 : 토트넘, 2021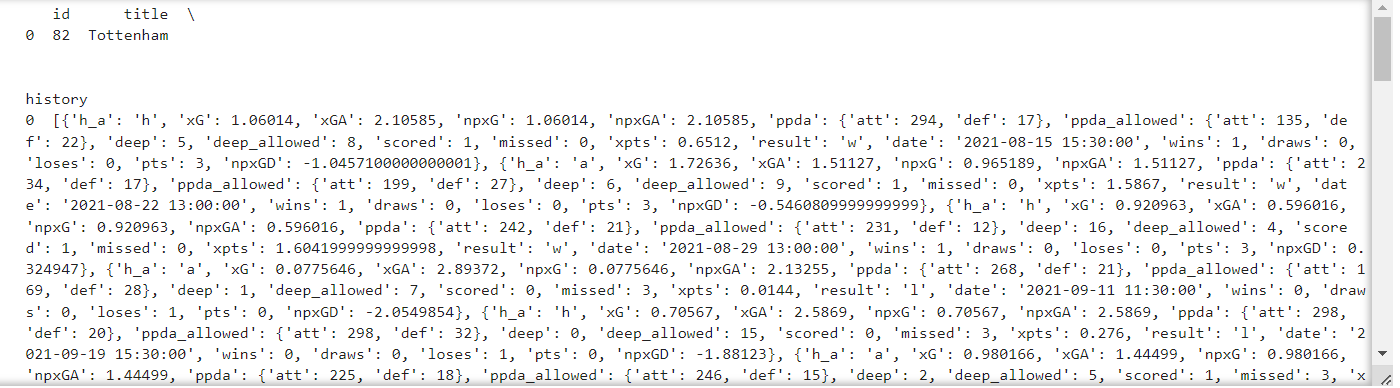
#데이터 프레임 만들기 : ppda att와 def는 각각 ppda_att ppda_def 열을 만들기
leng = len(teams.history[0]) #38개
pd.set_option('display.max_columns', None) #열 다 보일 수 있도록 환경설정
result = []
for j in range(leng):
list_idx = []
list_val = []
for idx, val in teams.history[0][j].items():
if idx == 'ppda':
for i, v in val.items():
list_idx.append('ppda_'+i)
list_val.append(v)
elif idx == 'ppda_allowed':
for i, v in val.items():
list_idx.append('ppda_allowed_'+i)
list_val.append(v)
else:
list_idx.append(idx)
list_val.append(val)
result.append(list_val)
get_teams_df = pd.DataFrame(result, columns = list_idx)
get_teams_df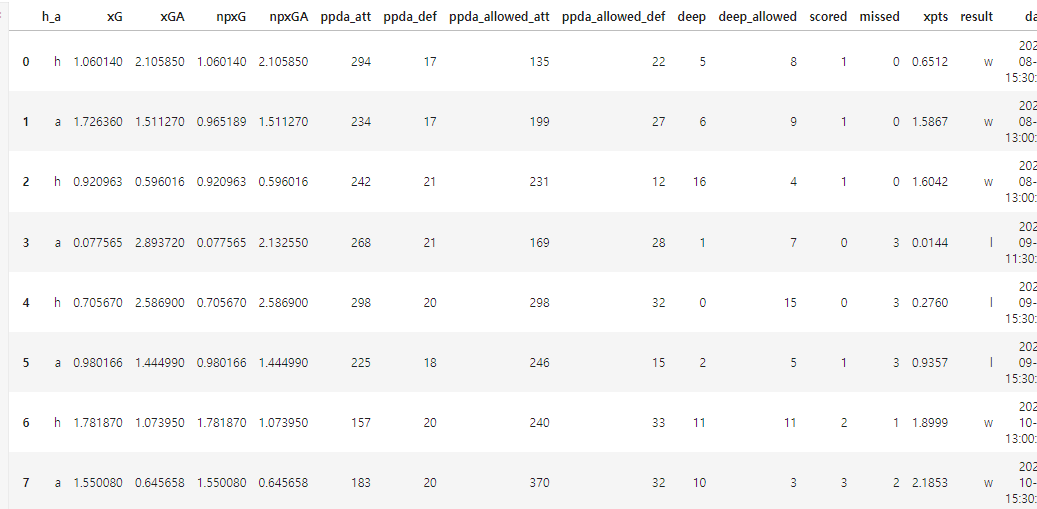
#get_team_stats : 팀 통계 반환
#데이터프레임 뽑아내기
async def main():
global team_stats_df
async with aiohttp.ClientSession() as session:
understat = Understat(session)
team_stats = await understat.get_team_stats("Tottenham", 2021)
team_stats_df = pd.DataFrame(team_stats)
#print(team_stats_df)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
team_stats_df
#형태가 독특하다. 각각 특정 열만 데이터가 채워져있는 형태 #각각 분리해보기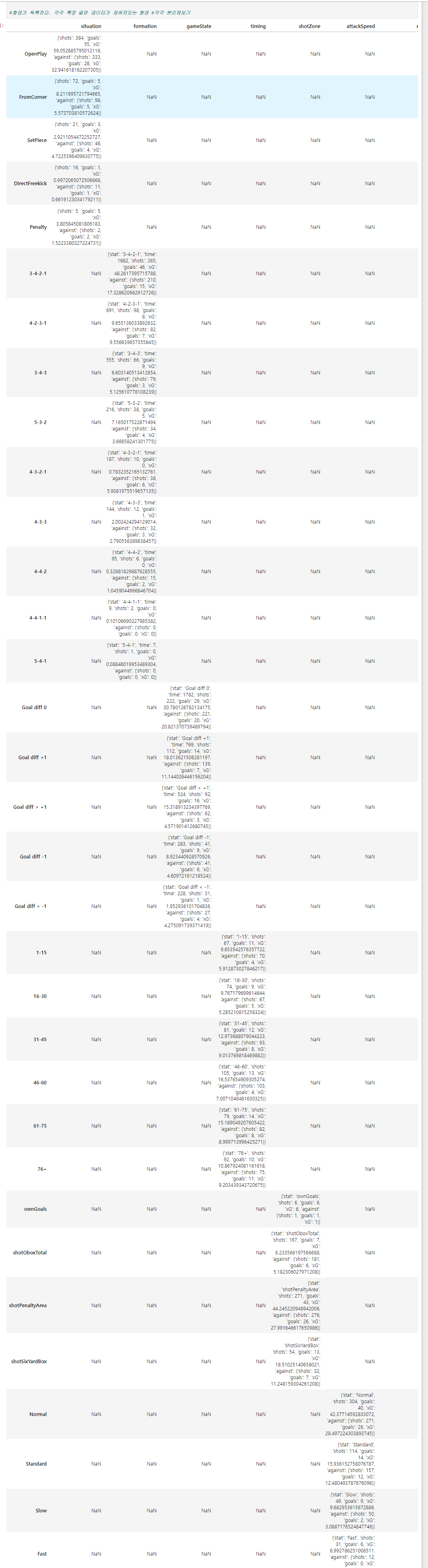
굉장히 독특..
print(team_stats_df.index)
print(team_stats_df.columns)
#각각 분할df 만듬
sit_df = team_stats_df.loc['OpenPlay' : 'Penalty', 'situation'].to_frame()
for_df = team_stats_df.loc['3-4-2-1' : '5-4-1', 'formation'].to_frame()
gst_df = team_stats_df.loc['Goal diff 0' : 'Goal diff < -1', 'gameState'].to_frame()
tim_df = team_stats_df.loc['1-15' : '76+', 'timing'].to_frame()
shz_df = team_stats_df.loc['ownGoals': 'shotSixYardBox', 'shotZone'].to_frame()
asp_df = team_stats_df.loc['Normal':'Fast' , 'attackSpeed'].to_frame()
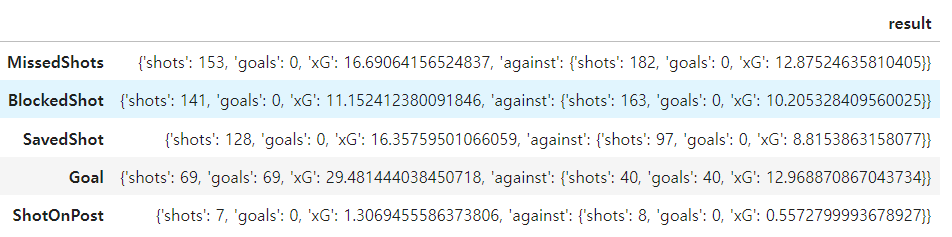
res_df = team_stats_df.loc['MissedShots': 'ShotOnPost', 'result'].to_frame()
#딕셔너리 분리해서 데이터프레임으로 만드는 함수 만들기
def unfold_fun(df):
result_data = []
col = []
for i in range(len(df)):
data = []
for idx, val in df.iloc[:, 0][i].items():
if i == 0:
if idx == 'against':
for ix, v in val.items():
data.append(v)
col.append(ix)
# print(v)
else:
data.append(val)
col.append(idx)
else:
if idx == 'against':
for ix, v in val.items():
data.append(v)
# print(v)
else:
data.append(val)
result_data.append(data)
# print(col)
result_df=pd.DataFrame(result_data, columns = col)
# print(result_df)
return result_df
#against 내 열 이름이 밖과 중복되므로 열 이름 바꾸기
def change_col_names(df):
new_col = ['against_shots', 'against_goals', 'against_xG']
cur_col = df.columns[:-3].tolist() # 마지막 3개 열을 제외한 나머지 열 이름 가져오기
cur_col.extend(new_col) # 새로운 열 이름 리스트에 기존 열 이름 리스트를 이어붙이기
df.columns = cur_col
return df
#1번 sit_df 데이터 프레임 보기좋게 만들기
scaled_sit_df = unfold_fun(sit_df)
change_col_names(scaled_sit_df)
sit_stat = team_stats_df[:5].index
#인덱스 정보가 포함되어있지 않아서 다른 df처럼 stat열을 만들어 저장
scaled_sit_df.insert(0, 'stat', sit_stat)
scaled_sit_df
#2번 for_df 데이터 프레임 보기좋게 만들기
scaled_for_df = unfold_fun(for_df)
change_col_names(scaled_for_df)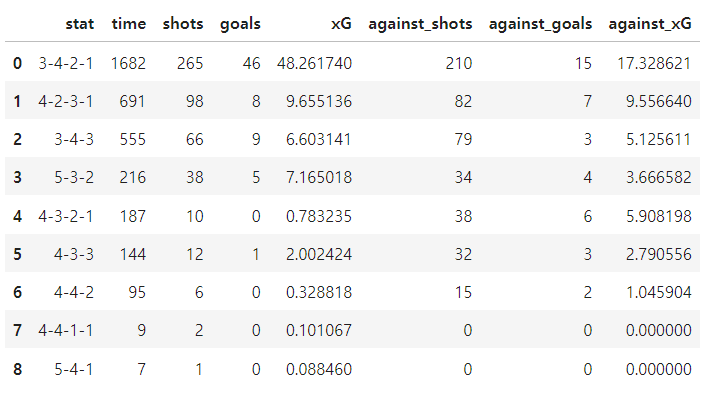
#3번 gst_df 데이터 프레임 보기좋게 만들기
scaled_gst_df = unfold_fun(gst_df)
change_col_names(scaled_gst_df)
#4번 tim_df 데이터 프레임 보기좋게 만들기
scaled_tim_df = unfold_fun(tim_df)
change_col_names(scaled_tim_df)
#5번 shz_df 데이터 프레임 보기좋게 만들기
scaled_shz_df = unfold_fun(shz_df)
change_col_names(scaled_shz_df)
#6번 asp_df 데이터 프레임 보기좋게 만들기
scaled_asp_df = unfold_fun(asp_df)
change_col_names(scaled_asp_df)
#7번 res_df 데이터 프레임 보기좋게 만들기
scaled_res_df = unfold_fun(res_df)
change_col_names(scaled_res_df)
#여기도 동일하게 stat만들어줌
res_stat=team_stats_df[-5:].index
scaled_res_df.insert(0, 'stat', res_stat)
scaled_res_df