CNN (컨볼루션/합성곱 신경망)
-
이미지 인식에 주로 사용되는, 합성곱층(컨볼루션 층)과 풀링층으로 이루어져 있는 특징을 가진 딥러닝 아키텍처
-
시각 피질 뉴런으로부터 힌트를 얻음
-
구조
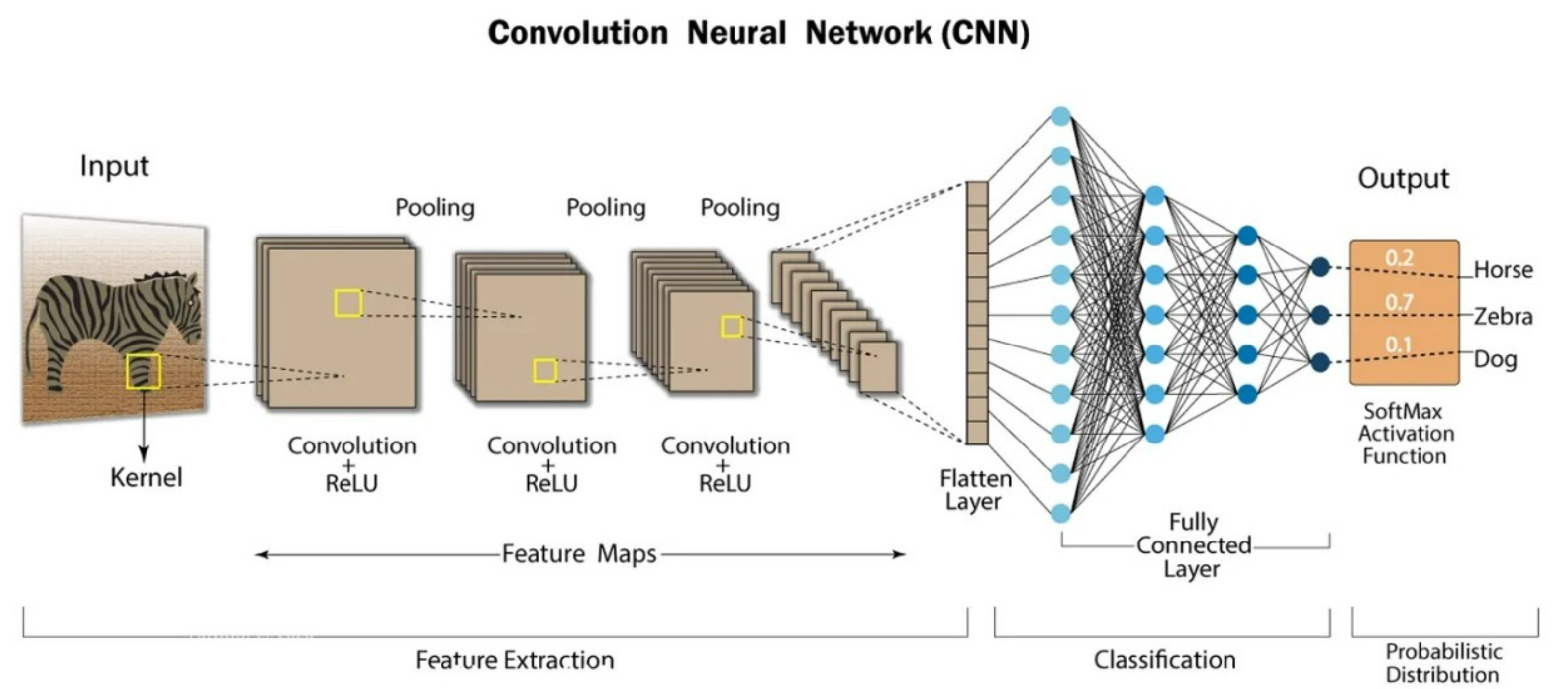
Input Layer - 합성곱층 - 풀링층 - FNL - Output Layer
1) 합성곱층 : 여러 필터(kernal)을 사용해 합성곱을 수행하고 특징 맵을 생성한다. CNN은 패턴을 인식하도록 학습한다면 어떤 위치에서도 패턴을 인식할 수 있다.
2) 풀링층 : 계산량과 과대적합을 방지하기 위해 축소본을 만드는 것
3) FNL(완전연결층) : 컨볼루션과 풀링을 거친 특징 맵을 1차원으로 평탄화하고 입력으로 사용한다. 분류작업을 위해 사용하고, 각 클래스에 대한 확률을 출력
RNN (순환 신경망)
-
순환신경망은 순차데이터나 시계열데이터를 이용하는 인공신경망 유형
-
내부 순환 구조가 포함되어있어 현재 정보에 이전 정보가 쌓이면서 정보 표현이 가능한 알고리즘이다. 데이터가 순환되기 때문에 정보가 끊임없이 갱신될수 있는 구조이다.
-
언어변환, 자연어 처리(NLP), 음성인식, 이미지 캡션 등에 사용한다.
-
특징
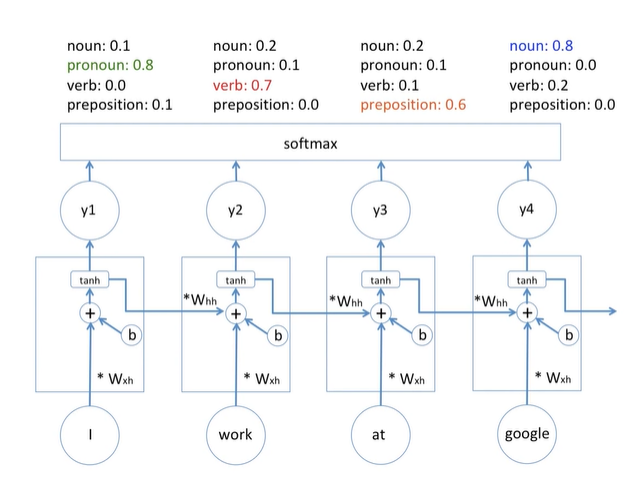
네트워크 각 계층에서 같은 가중치 매개변수를 공유한다는 것, 강화 학습을 촉진하기 위해 역전파(역방향으로 해당 함수의 국소적 미분을 곱해나가는 방법) 및 기울기 하강 프로세스를 진행하는 동안 이 가중치가 계속 조정된다.
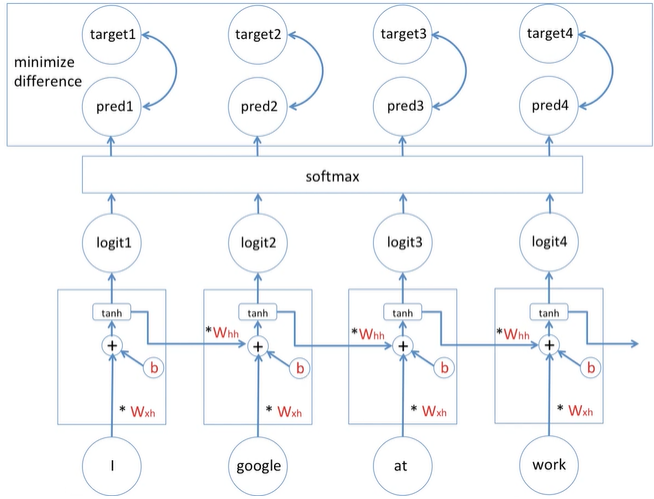

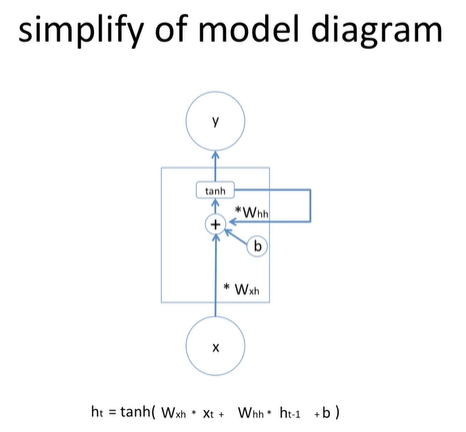
- 간단하게 표현하기
RNN은 필요한 정보를 얻기 위한 시간 격차가 커지면 학습한 정보를 계속 이어나가기 힘들어한다.
.
.
그래서 만들어진 LSTM
LSTM (장단기 기억 신경망)
Long Short-Term Memory
-
LSTM은 RNN의 한 종류로 긴 의존 기간이 필요한 학습을 수행하는 능력을 가지고 있다. (어떤 정보는 기억하고, 어떤 정보는 잊는다.)
-
RNN에 Gate 구조가 추가 된 것(4개의 MLP 구조), Gradient Flow를 제어할 수 있는 밸브 역할을 한다고 생각해보아라
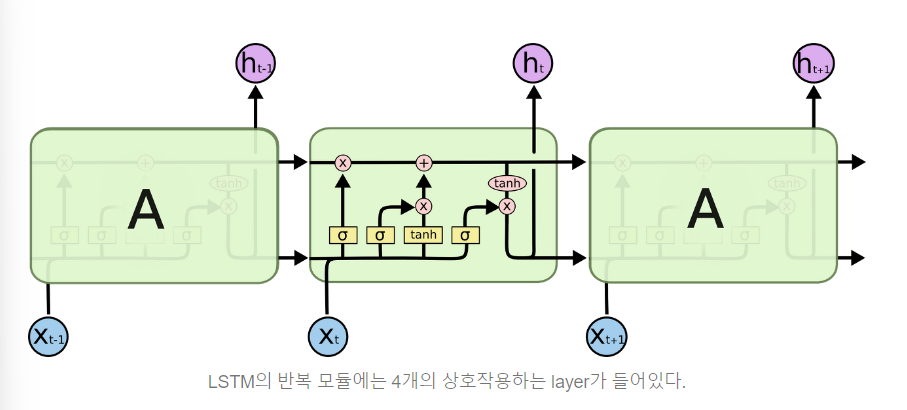
위 그림에서 각 선(line)은 한 노드의 output을 다른 노드의 input으로 vector 전체를 보내는 흐름을 나타낸다. 분홍색 동그라미는 vector 합과 같은 pointwise operation을 나타낸다. 노란색 박스는 학습된 neural network layer다. 합쳐지는 선은 concatenation을 의미하고, 갈라지는 선은 정보를 복사해서 다른 쪽으로 보내는 fork를 의미한다
출처
-
LSTM의 핵심은 cell state(linear interaction 만 적용하면서 전체 체인을 계속 구동)로 모듈 그림에서 수평으로 이어진 윗 선에 해당한다.
-
LSTM은 4개의 gate를 가지고 있고, 이 문들은 cell state를 보호하고 제어한다.
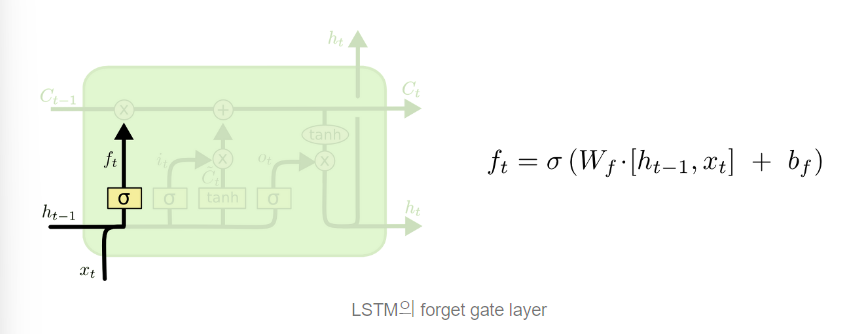
(1) FORGET GATE : cell state로 부터 어떤 정보를 버릴 것인지 정하는 것으로 sigmoid layer에 의해 결정된다. 0과 1사이의 값을 보낸다.(값이 1이면 모든 정보 보존, 0이면 버리기)
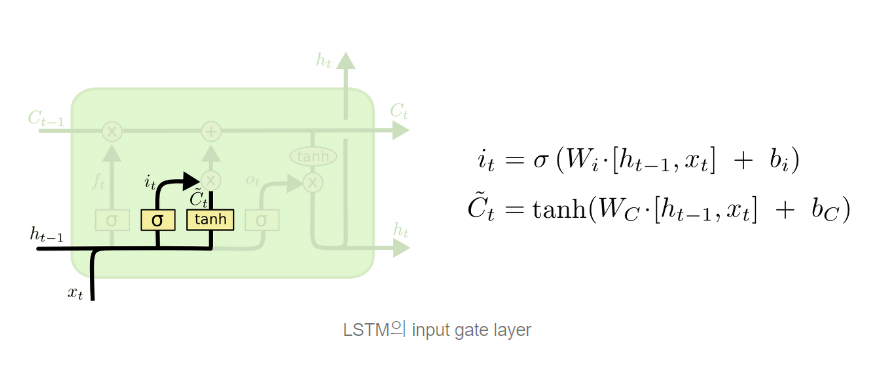
(2) INPUT GATE : 다음 단계는 앞으로 들어오는 새로운 정보 중 어떤 것을 cell state에 저장할 것인지, 활용할 것인지 정한다. sigmoid layer(input gate layer)가 어떤 값을 업데이트할 것인지 정하고, tanh layter가 새로운 후보 Ct 라는 vector를 만들고 cell state에 더할 준비를 한다. 이 두 단계에서 나온 정보를 합쳐 state를 업데이트할 재료를 만들게 된다.
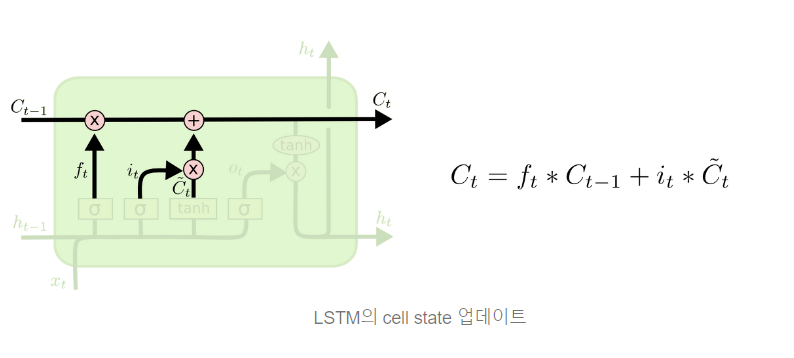
(3) CELL GATE : FORGET과 INPUT GATE에서 나온 값을 적절히 섞는다.
(4) OUTPUT GATE : 무엇을 output으로 내보낼 지 정한다. 이 output은 cell state를 바탕으로 필터된 값이 될 것이다. sigmoid layer에서 input 데이터를 태워 cell state의 어느 부분을 output으로 내보낼 지 결정하고, cell state를 tahn layer에 태워서 -1과 1사이의 값을 받은 뒤 방금 계산한 sigmoid gate의 output과 곱해준다.
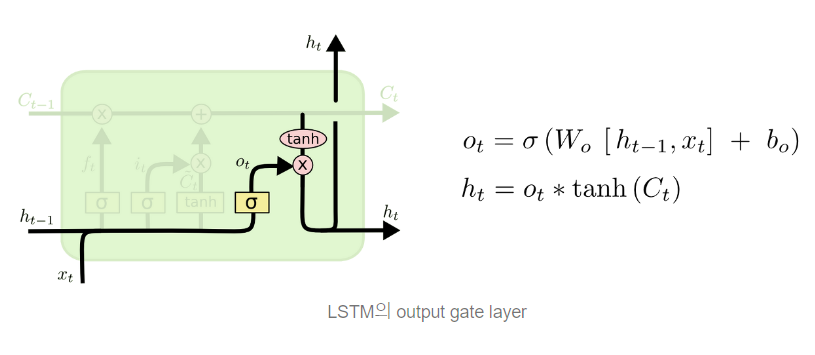
- 또다른 설명을 덧붙이자면 (출처 핸즈온 머신러닝)
-그림에서 보이는 C는 장기 상태, H는 단기 기억 상태로 볼 수 있다. 장기 기억 C는 네트워크를 왼쪽에서 오른 쪽으로 관통하면서 삭제 게이트를 지나 면서 일부 기억을 잃고, 입력 게이트에서 덧셈연산으로 새로운 기억 일부를 추가한다. 만들어진 C는 다른 추가변환 없이 바로 출력으로 보내진다.
-타임스텝마다 일부 기억이 삭제/추가된다. (선택적으로 기억한다)
-덧셈 연산 후에는 장기 상태가 복사되어 tanh 함수로 전달, 출력 게이트에 의해 걸러져 단기 상태 H(t)를 만든다.
GRU(Gated Recurrent Unit)
-
LSTM이 조금 더 변형된 것으로 LSTM의 간소화 버전, Cell State가 없다.
-
task에 따라 성능이 천차만별(RNN보다는 확실한 성능 보장)
-
장점 : LSTM보다 파라미터 수가 적어서 training time이 짧다.
