import tensorflow as tf
keras는 tensorflow에서 제공하는 고수준 신경망 API이며,
딥러닝과 기계학습를 쉽게 할 수 있는 인터페이스 중 하나이다
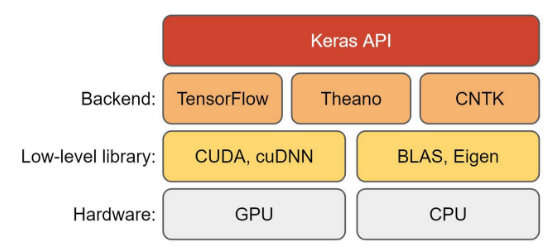
이미지 출처
.
.
특징
-
모델 구축 : 순차적인 신경망을 쉽게 구축 O
-Sequential,subClass,Functional -
레이어 : 다양한 레이어 제공
-
최적화 및 손실 함수 : 다양한 최적화 알고리즘을 사용해 모델 훈련 가능
-
모델 훈련
-compile메서드를 사용해 모델을 설정하고fit메서드로 데이터에 대해 모델을 훈련
-callback을 사용해 훈련 프로세스를 모니터링하고 제어 가능 -
모델 평가 및 예측 :
evaluation,predict사용
.
.
🤔 keras가 어떻게 구성되어 있는지 주요함수 위주로 크게 그려보자
.
.
모듈 종류
activations module
applications module
backend module
callbacks module
constraints module
datasets module
dtensor module
estimator module
experimenta module
export module
initializers module
layers module
losses module
metrics module
mixed_precision module
models module
optimizers module
preprocessing module
regularizers module
saving module
utils module
*출처 정말 많다..
.
.
주요 함수 정리
tf.keras.datasets : 내재된 데이터셋
boston_housing,cifar10, cifar100, fashion_mnist, imdb, mnist, reuters
tf.keras.Sequential : 신경망 구축
- 순서대로 연결된 층을 일렬로 쌓아서 전체 모델을 정의하는 방법
model = tf.keras.Sequential([tf.keras.layers.Dense(units=52, activation='relu', input_shape=(13,)),
tf.keras.layers.Dense(units=39, activation='relu'),
tf.keras.layers.Dense(units=26, activation='relu'),
tf.keras.layers.Dense(units=1)])
### (설명1)
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.07), loss='mse') #loss 최소화 방안 정의
### (설명2)
model.summary() #생성한 모델 구조 확인
history = model.fit(train_X, train_Y, epochs=25, batch_size=32, validation_split=0.25)
history.history #dict 형태의 학습기록 확인 가능
model.evaluate(test_X, test_Y) #성능 확인
model.predict(test_X) #예측(설명1 : 모델 틀 만들기)
#units : 해당 은닉층 뉴런 수, activation : 해당 은닉층 활성화함수
#input_shape : 입력 벡터의 크기로 첫 번째 은닉층에서만 정의, 여기서 13은 df의 열 수
#마지막 output 층에서 units=1 뜻은 출력하는 결과 하나
(설명2)
#compile : 모델 최적화를 위해 어떤 동작을 할 것인지 가르쳐주는 method
#loss : 손실함수, 모델 결과 판단 지표
#optimizer : 최적화 함수, loss가 가장 낮은 학습을 할 수 있도록 기준 계산하는 함수 제공
.
.
✏️ 추후 배울 그 외 모델 정의 방법
subClassing
- model 클래스를 상속해 사용자 정의 모델 클래스를 만드는 방법
- 유연성이 높고 복잡한 모델 생성 가능
Functional API
- 레이어를 함수처럼 호출해 모델 구조를 정의
- input 레이어를 사용해모델의 입력을 정의하고, 레이어를 연결하여 모델 구성
.
.
tf.keras.layers : 다양한 레이어 클래스 포함한 모듈
레이어는 신경망의 다양한 구성 요소를 나타내며, 이를 통해 모델의 아키텍처를 구축할 수 있다.
tf.keras.layers.Dense (units, activation=None, input_shape=None)
입출력 뉴런의 Fully Connected
tf.keras.layers.Conv2D(filters, kernel_size, activation=None, input_shape=None)
2D 컨볼루션(합성곱) 레이어, 이미지 처리에 주로 사용
tf.keras.layers.MaxPooling2D(pool_size=(2, 2))
최대 풀링 레이어, 맵의 크기를 줄이는 역할
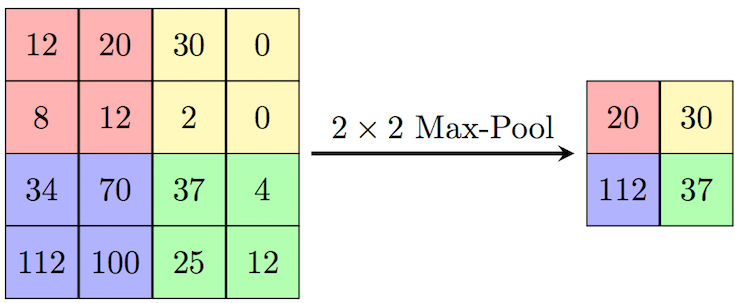
tf.keras.layers.LSTM(units, activation=None)
LSTM(Long Short-Term Memory) 레이어로, 순차적인 데이터 처리에 사용
tf.keras.layers.Flatten()
Flatten Layer로 1차원 벡터로 변환하는 레이터
tf.keras.layers.Activation(activation)
다양한 활성화 함수를 적용하는 레이어
tf.keras.layers.Dropout(rate/드롭아웃 비율)
무작위로 선택한 뉴런을 비활성화시키는 레이어로 정규화 방법 중 하나이며, 과적합을 방지한다
output_tensor = torch.functional.dropout(input_tensor, p=0.5, training=True)
#p : 각 뉴런이 드롭아웃될 확률, training=True 학습 중에 드롭아웃이 적용.
.
from tensorflow.keras.applications import ResNet50
케라스에서 제공하는 사전 훈련된 ResNet-50 모델을 불러오는 코드, 매우 깊은 신경망 구조를 가지고 있으며 잔차학습 개념을 도입해 훈련 과정에서 그래디언트 소실 문제 해결
### 예시 ###
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
# ResNet50 모델 불러오기
model = ResNet50(weights='imagenet')
# 예측을 위한 이미지 로드 및 전처리
img_path = 'path_to_your_image.jpg'
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = preprocess_input(img_array)
# 이미지에 대한 예측
predictions = model.predict(img_array)
# 예측 결과 디코딩 및 출력
decoded_predictions = decode_predictions(predictions, top=3)[0]
print(decoded_predictions)*그 외에도 정말 많음 보기
.
.
tf.keras.optimizers : 최적화 알고리즘을 포함
-
확률적 경사 하강법
tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.0, nesterov=False)
: 배치에 대한 기울기를 이용해 가중치 업데이트 -
Adam 최적화 알고리즘
tf.keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False)
: 지수 이동 평균으로 가중치 업데이트 -
Adagrad 최적화 알고리즘
tf.keras.optimizers.Adagrad(learning_rate=0.01, initial_accumulator_value=0.1, epsilon=1e-07)
: 각 매개변수에 대해 적응하는 학습률을 사용하여 가중치 업데이트
tf.keras.model : 모델을 정의하는 기본 클래스
모델의 핵심 기능을 제공하고, 모델의 아키텍쳐와 동작을 정의한다.
tf.keras.Model.evaluate
tf.keras.Model.predict
(번외) Tensorflow 2.0.0 버전 후 변경된 부분
-
Session() 함수 삭제
with tf.Session as sses:부분이 필요없다는 뜻 (이전 버전 책에서 많이 나옴) -
tf.placeholder함수 더이상 사용하지 않음 (정의를 플레이스홀더 노드로 변경할 필요 없음) -
pandas df로도 바로 input 가능
-
eval() 함수는 더 이상 사용되지 않음. TensorFlow 1.x 버전에서 eval() 함수는 계산 그래프를 실행하고 결과를 얻기 위해 사용되었으나, TensorFlow 2.0부터는 즉시 실행 모드 (Eager Execution)가 기본적으로 활성화되어 있어서 계산 그래프를 명시적으로 만들고 세션을 열 필요가 없음
