Abstract
1. Introduction
2. Related Works
3. Background
3.1. Denoising Diffusion Models
3.2. Latent Diffusion Models
4. Method
4.1. Importance of Parameter Choice
5. Experiments
5.1. Artistic Style Removal
5.1.1. Experiment Setup
5.1.2. Artistic Style Removal User Study
5.2. Explicit Content Removal
5.3. Object Removal
5.4. Effect of η on Interference
5.5. Limitations
6. Conclusion
Self Q&A
Opinion
Abstract
large-scale diffusion model이 sexual 콘텐츠나 copyrighted artistic styles과 같은 'undesirable(바람직하지 않은)' 결과를 낳을 수 있다는 우려를 해결하기 위해, diffusion model의 weights에서 특정 concepts을 삭제 시키는 방안에 대해서 연구이다.
(제거할)스타일 이름만 지정해주면, 이 negative guidance(지정한 스타일)를 teacher로 사용하여 pre-trained diffusion model에서 시각적 concept을 지울 수 있는 fine-tuning 방법을 제안한다.
sexually explicit 콘텐츠를 제거하는 기존 접근 방식과의 benchmark를 비교했을 때, 그 효과를 입증하였고 이는 Safe Latent Diffusion이나 censored training과 동등한 성능을 발휘한다.
artistic styles 제거를 평가하기 위해 네트워크에서 5명의 현대 예술가를 시대별로 구분하는 실험을 수행하고, 제거된 스타일에 대한 인간의 인식을 평가하기 위해 user study를 진행했다.
이전 방법과 달리, 논문의 접근 방식은 inference 시점에 output을 수정하는 대신, diffusion model에서 concepts을 영구적으로 제거할 수 있으므로 사용자가 모델 weights에 액세스할 수 있는 경우에도 이를 우회할 수 없다.
연구에 사용된 코드, 데이터, 결과는 https://erasing.baulab.info/ 에서 확인할 수 있다.
1. Introduction

최근의 text-to-image generative models은 뛰어난 이미지 quality와 무한한 generation capabilities로 인해 주목 받고 있다.
이러한 모델은 방대한 '인터넷' 데이터 세트를 학습하여 다양한 concepts을 모방할 수 있다.
그러나 모델이 학습한 일부 concept은, copyrighted content 혹은 pornography와 같이 undesirable하므로 모델의 output에서 이를 피하고자 한다.
논문에서는 pretrained text-conditional model의 weights에서 단일 concpet을 '선택적으로 제거'하는 접근 방식을 제안한다.
이전의 접근 방식은 dataset filtering(학습데이터에서부터 필터링), post-generation filtering(생성 결과 필터링), inference guiding(추론시 가이드라인 제공)에 초점을 맞춰왔다.
data filtering 방법과 달리, 우리의 방법은 retraining이 필요하지 않으므로 대규모 모델에 대해서도 (사후에)적용할 수 있다.
Inference-based 방법은 원하지 않는 concept으로부터 output을 효과적으로 검열하거나 조정할 수 있지만, 쉽게 circumvented(우회)할 수 있다(open source이므로, 해당 코드 제거 가능).
반면, 논문의 접근 방식은 모델 parameters에서 concept을 직접 제거하여 weights를 안전하게 분배할 수 있다.
심지어는 SD 2.0에서는 dataset filtered 방법을 사용했음에도 불구하고, Inappropriate Image Prompts (I2P) benchmark의 4,703개 프롬프트를 사용하여 이미지 생성을 평가한 결과, SD 1.4 모델(2.0 이전 범용적인 모델)은 신체 부위가 노출된 이미지를 796개를 생성하는 반면, 새로운 restricted dataset을 사용한 SD 2.0 모델은 417개를 생성하는 것으로 나타났다(개선되긴 했지만 여전히 문제).
text-to-image 모델과 관련된 또 다른 주요 우려 사항은 copyrighted content를 모방할 수 있다는 점이다. AI-generated art의 품질이 사람이 생성한 창작물의 품질과 동등할 뿐만 아니라, 실제 아티스트의 artistic style을 복제하게 된다.
Stable Diffusion 및 large-scale text-to-image synthesis systems 사용자들은 "art in the style of [artist]"와 같은 프롬프트를 통해 특정 아티스트의 스타일을 쉽게 모방할 수 있으며, 이는 잠재적으로 원본 작품의 가치를 떨어뜨릴 수 있다.
몇몇 아티스트들은 저작권 문제에 대해 Stable Diffusion 제작자를 상대로 소송을 제기하여, 새로운 법적 문제가 대두되었지만, 법원은 아직 이 사건에 대한 판결을 내리지 않았다.
이와 관련된 최근의 연구는, 작가가 작품을 온라인에 게시하기 전에 adversarial perturbation을 적용(post-generation filtering)하여, 모델이 모방하는 것을 방지함으로써 아티스트를 보호하는 것을 목표로 했으나(사람에게는 똑같이 보이지만 모델은 인식이 어려워짐), 이러한 접근 방식은 pretrained model에서 학습된 artistic style을 제거할 수 없다.
safety(sexual)와 copyright 우려에 대응하기 위해, 논문에서는 text-to-image model에서 concept를 erasing하는 방법을 제안한다.
논문이 제안하는 Erased Stable Diffusion (ESD)은 추가 학습 데이터 없이 원하는 concept에 대한 설명만을 사용하여, 모델의 parameters를 fine-tunes한다.
dataset filtering 방식과 달리, ESD 방식은 속도가 빠르며 전체 시스템을 처음부터 교육할 필요가 없다.
post-generation filtering이나 inference guiding과 달리, ESD는 parameter에 접근할 수 있는 사용자라도 쉽게 우회할 수 없다.
offensive content에 대한 benchmark한 결과에서, ESD는 Safe Latent Diffusion만큼 효과적이라는 것을 확인했다.
모델에서 artistic style을 제거하는 방법에 대한 실험의 경우, user study를 통해 artistic style을 잘 제거했는지, 다른 artistic style을 가져오지는 않았는지, 이미지 품질에 영향이 없는지에 대해 테스트를 진행했다.
마지막으로, complete object classes의 삭제에 대해서도 테스트했다.
2. Related Works
Undesirable image removal
Undesirable image output을 제거하는 이전 연구는 크게 2가지이다.
- 1) Dataset removal(훈련을 다시 시켜야한다는 점, 이미지를 전부 살펴봐야하는 cost 문제),
- 2) post-hoc(output 결과 필터링, inference 시 guidance. 우회 가능하다는 문제)
이후 실험에서, 논문의 접근방식 ESD의 결과를 Stable Diffusion 2.0(filtered Dataset으로 재훈련)과 Safe Latent Diffusion(SOTA. guidance-based approach)와 비교했다.
Image cloaking (Copyrighted image)
large-scale model의 모방으로부터 이미지를 보호하는 또 다른 접근 방식은 아티스트가 이미지를 인터넷에 게시하기 전에, adversarial perturbations을 추가하여 이미지를 은폐하는 것이다.
adversarial perturbations는 아티스트가 자신의 작품을 인간에게 보이게 하면서도 AI 학습 세트에서 자신의 콘텐츠를 자체 검열할 수 있는 유망한 방법이다(아티스트가 직접 적용해야한다).
논문의 방법은, 모델 제작자가 콘텐츠 제공자의 적극적인 자기 검열 의사
없이도 시각적 concept을 지울 수 있는 방법을 모색했다.
Model editing
Memorization and unlearning
Energy-based composition
3. Background
3.1. Denoising Diffusion Models(DDPM)
Diffusion model은 점진적인 노이즈 제거 과정(gradual denoising)을 통해 distribution space을 학습하는 생성 모델의 한 종류이다.
'샘플링된 Gaussian noise'에서 시작하여, 모델은 최종 이미지가 형성될 때까지 번의 time step에 걸쳐 점진적으로 노이즈를 제거한다.
이를 자세히 설명하면, Diffusion model은 매 time step 마다 노이즈 (제거할 노이즈)를 예측하는데, 이는 중간단계 이미지(일부 noise가 제거된) 를 생성하는 데 사용된다.
여기서 는 초기 노이즈에 해당하고 은 최종 이미지에 해당한다.
이 노이즈 제거 과정은 마르코프 전이 확률(t가 t-1 상태에만 의존)로 모델링된다.
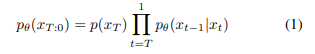
- x_t|x_t-1가 아니라 x_t-1|x_t로 표현된 것은 원본이미지로 복원하는 과정이기 때문(initial이 T고 최종 이미지가 0인 것과 같은 이유)
3.2. Latent Diffusion Models(LDM)
Latent diffusion models(LDM)은 인코더 와 디코더 를 사용하여 'pre-trained VAE'의 저차원 latent space 에서 작동함으로써 효율성을 개선했다(DDPM에 VAE를 적용하여 효율 개선).
- (Encoder를 통해 저차원 공간상에 latent space를 구현하다보니)
- (i) 데이터의 중요하고 의미있는 bits에 집중할 수 있고(+유사한 이미지 생성에도 더 용이),
- (ii) 더 낮은 차원에서 학습할 수 있어 computionally 효율적.
훈련 중에 image 에 대해 인코딩된 latent, 에 노이즈가 추가되어 노이즈 레벨이 에 따라 증가하는 가 된다(개념적으로 DDPM의 와 유사).
LDM 프로세스는 동일한 파라미터 를 가지는 DDPM의 시퀀스로 해석할 수 있으며(와 가 유사한 개념), 이 모델은 condition에 외에 time step 와 text condition(class정보) 를 추가한 상황에서 노이즈 를 예측하는 방법을 학습한다.
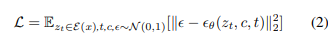
- 수식적인 이해는 'Latent Diffusion Models'을 통해 자세하게 할 수 있으며, 여기서는 DDM보다 효율적인 LDM을 활용했다는 것에 중점
Classifier-free guidance(이 부분에 대해서는 이해도 부족)

Classifier-free guidance는 이미지 생성을 재조정하는 데 사용되는 기법이다.
이 방법은 implicit classifier 에 따라 확률이 높은 데이터로 확률 분포를 리디렉션하는 것이다(가 특정 class에 속할 확률을 높이는 작업. classification을 적용).
이 접근 방식은 inference 중에 사용되며 conditional, unconditional 노이즈 제거에 대해 모델을 공동으로 학습시켜야 한다.
conditional, unconditional scores는 모두 inference 과정에서 얻어진다(매 time step ).
그런 다음 guidance scale α>1(높을 수록 class의 정확도는 높아지지만 이미지의 다양성이 줄어든다)을 사용하여 최종 점수 를 conditioned score 쪽으로 가깝게, unconditioned score에서 멀어지게 한다.
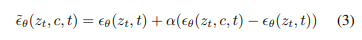
- dog 이미지를 복원하는 과정에서, condition 정보(class가 이다는 정보)를 주고 생성한 노이즈에서 unconditioned 노이즈를 빼면 에 대한 임베딩 값을 추론할 수 있을 것. 이 값을 에 더해서 class 정보가 추가된 방법으로 복원
- 와 가 다름 주의
inference 과정은 Gaussian 노이즈 에서 시작하여로 노이즈를 제거하여 을 얻는다.
이 과정은 까지 순차적으로 수행되며, 디코더 를 사용하여 이미지 공간으로 변환된다.
4. Method
본 논문의 목표는 추가 데이터 없이 자체 지식을 사용하여 text-to-image diffusion model에서 concepts을 지우는 것이다.
따라서 우리는 처음부터 모델을 훈련하기보다는 pre-trained model을 fine-tuning하는 것을 고려했다.
논문은 '텍스트 인코더 T', 'diffusion model(U-Net) ', '디코더 모델 D' 세 가지 하위 네트워크로 구성된 LDM과 Stable Diffusion(SD)에 초점을 맞췄다.
우리의 접근 방식은 pre-trained diffusion U-Net 모델의 weights를 편집하여 특정 style이나 concept을 제거하는 것이다.
논문은 concept에 따라 설명되는 likelihood에 따라 이미지 가 생성될 확률을 의 배율로 환산하여 줄이는 것을 목표로 한다.
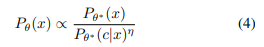
- 여기서 는 원래 모델에서 생성된 분포를 나타내고, 는 지울 개념을 나타낸다.
- 즉, 원래 모델의 latent 분포를, c가 포함된 결과가 나올 확률을 줄이는 방향으로 만드는 것
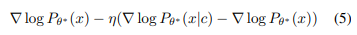
- 를 확장하면, 로그 확률 의 기울기는 위 공식과 같이 비례한다.
- 즉, 제거하고자 하는 class 가 포함된 이미지 - 원래 이미지()를 진행하면, 를 제거하는 임베딩 정보가 나올 것이고, 원래 이미지의 결과를 정보를 제외한 이미지로 대체(비례)되도록 학습을 진행하는 것
Tweedie의 공식과 reparametrization trick을 기반으로, 시간에 따라 변하는 노이즈 프로세스를 도입하고 각 점수(gradient of log probability)를 노이즈 제거 예측값 로 표현할 수 있다.
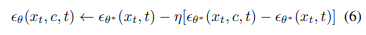
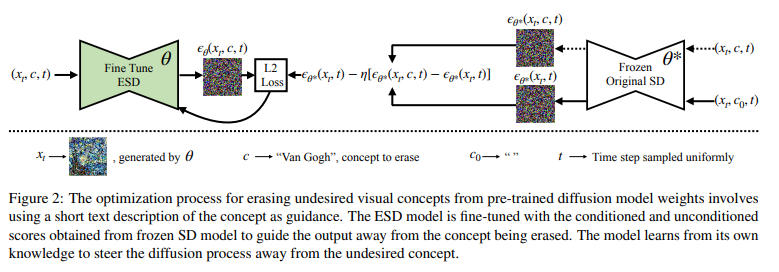
Fig. 2는 훈련 과정을 보여준다.
concept에 대한 모델의 지식을 활용하여 훈련 샘플을 합성하므로 데이터 수집이 필요하지 않다.
훈련은 diffusion model의 여러 예제를 사용하는데(랜덤 샘플링 노이즈 이미지), 한 파라미터 세트()는 고정하고(오른쪽), 다른 파라미터 세트()는 concept를 지우기 위해 훈련한다(왼쪽).
논문에서는 부분적으로 노이즈가 제거된 이미지 를 사용해 (가 추가된)를 샘플링한 다음, frozen model 에 대한 예측을 두 번 수행하여 한 번은 를 포함한 conditioned으로, 다른 한 번은 unconditioned으로 노이즈를 예측한다.
마지막으로, 두 prediction을 선형적으로 결합하여 concept과 관련된 예측 노이즈를 무효화하고 새 모델을 새로운 목표에 맞게 조정한다.
- 즉, (오른쪽에서 들어오는 정보)에서 를 뺀 값(의 정보)과 (왼쪽에서 들어오는 정보)에 대한 노이즈의 차이를 0으로 만드는 작업
- 차이(L2 Loss)가 0이라는 말은, 가 있으나마나 한 상태로 만드는 것으로(를 제거할 수 있는 노이즈를 만드는 것), 결국 가 로 변화되도록 학습하는 것
4.1. Importance of Parameter Choice

대상 삭제를 적용하는 효과는 fine-tuned parameters의 subset에 따라 달라진다.
주요 차이점은 cross-attention parameters 와 non-cross-attention parameters 이다.
Fig. 3a에 일루전으로 표시된 cross-attention parameter는 프롬프트의 텍스트 입력 따라 직접적으로 프롬프트로 연결되는 게이트웨이 역할을 하는 반면, 다른 parameter(Fig. 3b)는 프롬프트에 concept이 언급되어 있지 않더라도 시각적 concept에 기여하는 경향이 있다.
- artistic style과 같이 제거 대상을 지정하고 프롬프트를 통해 선택적으로 적용하고자 하는 경우 cross attentions인 ESD-x를 fine tuning할 것을 제안한다.
- NSFW nudity와 같이 글로벌 concept이 삭제되어야 하는 경우, unconditional layer(non-cross-attention modules)인 ESD-u를 fine tuning할 것을 제안한다.

"Van Gogh" 스타일을 지울 때 ESD-u 및 unconditioned parameter를 선택하면, 스타일의 일부분을 전체적으로 지워 반 고흐 이외의 많은 artistic styles에서 반 고흐 스타일의 일부분을 지운다(다른 그림에도 global한 영향).
반면, cross-attention parameter만 조정(ESD-x)하면 프롬프트에서 반 고흐의 이름이 언급될 때, 반 고흐의 독특한 스타일만 지워져 다른 예술 스타일과의 간섭을 최소화한다.
반대로 NSFW 콘텐츠를 삭제할 때는 '누드'라는 시각적 concept을 global하게 삭제하는 것이 중요하다.
이러한 효과를 측정하기 위해 NSFW 용어를 명시적으로 언급하지 않은 많은 프롬프트가 포함된 데이터 세트를 평가했다(Sec 5.2).
5. Experiments
- ESD-x 방법은 cross-attention을 fine-tuneing
- ESD-u과 Stable Diffusion U-Net module의 unconditional weights을 fine-tuning
- SD(pretrained Stable Diffusion)
- SLD(Safe Latent Diffusion)
- SD-Neg-Prompt (Stable Diffusion with Negative Prompts)
5.1. Artistic Style Removal
- User study에 참여한 참가자들은 실험 이미지와 실제 예술 작품이 동일한 작가에 의해 제작된 것 같은지 여부를 5점 리커트 척도로 평가하였다.
- 13명의 참가자, 참가자당 평균 170건의 응답
5.1.1. Experiment Setup
5.1.2. Artistic Style Removal User Study
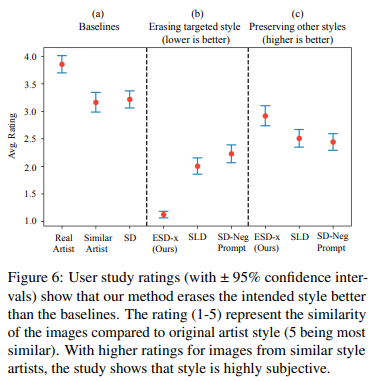
- a: 품질(해당 작가의 원본 같은지)
- b: target style을 잘 제거했는지
- c: style이 지워져도 원본과 유사한지(target style만 지워지는지)

- style을 제거할 때, 다른 작품에 영향을 미치는지(interference)에 대한 평가
- 논문의 방법이 SLD에 비해 다른 예술적 스타일을 방해하지 않음(대각행렬만 큰 변경이 적용)
- 다만, 다른 방법과 달리 모델을 영구적으로 수정하기 때문에 많은 작업을 진행한 후에 결과에 대해서는 의문(리뷰어의 의견)
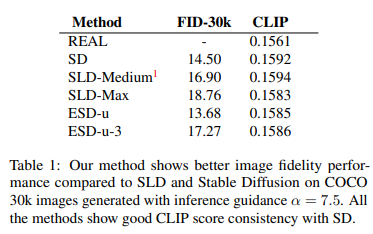
5.2. Explicit Content Removal
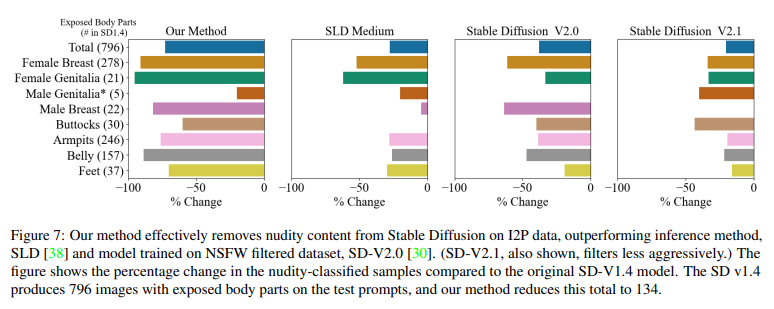
- parameter를 영구적으로 수정하기 때문에 우회문제로부터도 자유로움
- Dataset filter 방법을 사용한 SD 2.0에 비해서도 훨씬 높은 성능
- global한 적용을 위해 ESD-u를 사용
5.3. Object Removal
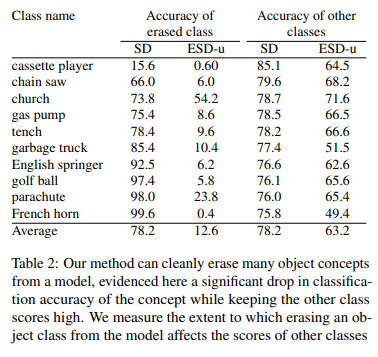
- ImageNet class의 하위 집합에서 각각 하나의 class를 제거한 10개의 ESD-u 모델을 이용해 평가 진행
- 각 모델을 사용해 각 class(제거한 class)의 이미지를 500개씩 생성한 다음, pretrained Resnet-50 classifier를 이용해 결과를 평가
- 다른 class의 성능이 같이 떨어지는 Interference이 발생하기도 하지만, 개체의 삭제 성능은 월등하다.
5.4. Effect of η on Interference
- η = 10으로 설정하면 누드 이미지의 92%를 지우지만, 물체 이미지에서는 1000방향 분류 정확도가 34% 감소하고
- η = 3으로 설정하면 88%를 지우고 물체에 14% 영향을 주며,
- η = 1로 설정하면 83%를 지우고 물체에 7% 영향을 주는 것을 확인했다.
- 즉, η 값을 줄이면 Interference을 완화할 수 있지만 η를 줄이면 목표 concept를 지우는 효율성이 감소한다.
5.5. Limitations

논문의 방법은 target concept의 삭제와 다른 concept에 대한 Interference 사이의 trade-off가 존재한다.
Fig. 8에서는 몇 가지 한계를 설명한다.
특정 객체 클래스를 지울 때, 논문의 방법은 일부 클래스에 대해 실패하며, 특정 concept의 고유한 속성(예: 교회의 십자가, 낙하산의 갈비뼈)만 지우고 더 큰 concept를 지우지 못하는 경우가 있다.
6. Conclusion
논문에서는 모델의 weight를 직접 업데이트하여 text-to-image generation model에서 cific concepts을 제거하는 접근 방식을 제안한다.
dataset filtering과 retraining이 필요한 기존 방법과 달리, 본 논문에서 제안하는 접근 방식은 데이터 세트를 조작하거나 비용이 많이 드는 재학습이 필요하지 않으며, 대신 제거하고자하는 concept 이름만 입력하고 fine-tuning하면 되는 빠르고 효율적인 방법이다.
모델의 weights에서 직접 concept를 제거함으로써, post-inference filters가 필요 없고, parameters를 안전하게 배포할 수 있다(inference guiding가 아니기에, 우회 불가능).
논문은 세 가지 적용에서 접근 방식의 효율성을 입증했다.
- 첫째, 우리의 방법이 Safe Latent Diffusion과 비슷한 결과로 노골적인(성적인) 콘텐츠를 성공적으로 제거할 수 있음을 보여주었다.
- 둘째, 우리의 접근 방식이 artic styles을 제거하는데 어떻게 사용될 수 있는지를 보였다.
- 마지막으로, 구체적인 객체 클래스를 제거하는 실험을 통해 이 방법의 다용도성을 설명했다.
