기존의 2 stage detector은 localization, classification을 나누어서 진행하기 때문에 속도가 매우 느리다. 따라서 real-time으로 object detection task를 잘 실행하기 위해서 고안된 것이 이 모든 것을 한 번에 처리하는 1 stage detector이다. 특히 1 stage detector는 영역을 추출하지 않고 전체 이미지를 보기 때문에 객체에 대한 맥락적 이해가 높다.
YOLO v1
1 stage detector의 예시로 YOLO 모델이 있다. YOLO (You Only Look Once)는 GoogLeNet을 변형하여 object detection task에 사용했으며, 24개의 convolution layer를 이용해서 특징을 추출하고, 2개의 Fully-Connected (FC) layer를 통과하며 box의 좌표값과 확률을 계산한다.
입력 이미지를 7 7 grid로 나눈 후 각 grid마다 2개의 bounding box 좌표 (, , , )와 confidence score (= ), 해당 클래스일 확률 (conditional class probability = )을 계산한다. 그 후 NMS algorithm을 활용하여 가장 적절한 bbox를 도출한다.

loss function은 위와 같이 localization loss, confidence loss, classification loss로 이루어져 있다.
YOLO는 다른 real-time detector에 비해 정확도가 2배 높았고 이미지 전체를 보기 때문에 맥락적 정보를 가지고 있다는 장점이 있다. 그러나 grid보다 작은 크기의 물체는 detection할 수 없고, 신경망을 통과하며 마지막 feature만 사용하기 때문에 정확도가 하락한다는 단점이 있다.
Single Shot Multibox Detector
Single Shot Multibox Detector (SSD)는 VGG16을 backbone으로 사용하고 extra convolution layer에서 나온 6개의 서로 다른 스케일의 feature map에서 detection을 수행한다. 큰 feature map에서는 (→ early stage feature map) 작은 물체를 detection하고, 작은 feature map에서는 (→ late stage feature map)에서는 큰 물체를 detection한다.
서로 다른 스케일과 aspect ratio을 가진 미리 계산된 default anchor box를 사용해서 object의 위치를 예측한다. 이 논문에서는 feature map의 각 셀마다 6개의 default box를 만들어서 그 안의 class score를 계산한다.
학습 과정에서는 hard negative mining과 non maximum suppression을 사용하고, luss function은 localization loss와 confidence loss로 이루어져 있다.

YOLO v2
- batch normalization으로 mAP가 v1 대비 2% 향상
- anchor box 도입
- COCO dataset에 K means cluster
- 좌표 값 대신 offset을 예측하도록 학습함
- early feature map을 late feature map에 합쳐주는 passthrough layer 도입
- 다양한 크기의 입력 이미지 사용
- backbone으로 Darknet-19를 사용하고 마지막 Fully-Connected layer를 3 3 convolution layer로 대체 + 1 1 convolution layer 추가 → 속도에서의 향상
- word tree 구성 (ex) airplane이라는 상위 노드 하에 biplane, jet, airbus 등의 하위 노드가 있는 구조)
YOLO v3
- skip connection 적용
- 서로 다른 3개 scale의 multi-scale feature map 사용
- FPN을 사용하여 상위 level의 세부 정보와 하위 level의 semantic 정보를 얻음
YOLO v4
보다 빠르고 정확도가 높은 detector의 필요성이 대두되고 있는 상황에서, YOLO v4가 많은 실험을 거쳐 하나의 GPU에서 훈련할 수 있는 빠르고 정확한 object detector로 발돋움하게 되었다.
어떻게 YOLO v4가 정확도와 속도를 향상시켰는지 방법을 살펴보자.
Bag of Freebies (BOF)
inference 비용을 늘리지 않고 정확도를 향상시키는 방법이다.
- Data augmentation
- Semantic distribution bias
데이터 셋에 특정 라벨(배경)이 많은 경우 불균형을 해결하기 위한 방법
+ label smoothing : 라벨을 0 → 0.1, 1 → 0.9처럼 smooth하게 부여해서 모델의 overfitting을 막고 regularization 효과를 준다. - Bounding box regression
기존에 bbox regression을 할 때는 MSE loss를 사용하였으나, MSE loss는 IoU 정보가 반영되지 않아 다소 부정확하다. (ex) 같은 MSE loss 값인데도 IoU는 0.26, 0.65 등으로 차이가 나는 경우 존재) 이를 해결하기 위해 GIoU라는 IoU 기반 loss를 이용하여 bbox regression을 하면 bbox가 더 잘 학습된다.
Bag of Specials (BOS)
inference 비용을 조금 높이지만 정확도가 크게 향상하는 방법이다.
- Enhancement of receptive field
Spatial Pyramid Pooling, ASPP, W-MSA
-
Attention module
feature map에 global attention을 추가해주는 방법이다. context 관점에서 상대적으로 더 중요한 feature map에 집중할 수 있도록 해준다.
ex) SE, CBAM -
Feature integration
= feature map을 통합 = Neck -
Activation function
약간의 음수를 허용하는 Swish/Mish -
Post-processing method
불필요한 bbox 제거 (→ NMS)
Architecture
YOLO v4는 1) 작은 물체를 검출하기 위한 큰 네트워크 입력 사이즈, 2) 입력 사이즈 증가로 큰 receptive field (+ 많은 layer), 3) 하나의 이미지에서 다양한 크기의 물체 검출을 위한 큰 모델 용량에 집중하여 모델을 개발했다.
- backbone
Cross Stage Partial Network (CSPDarknet53)
기존 DenseNet에서 가중치를 업데이트할 때 gradient가 재사용되는 문제점을 개선
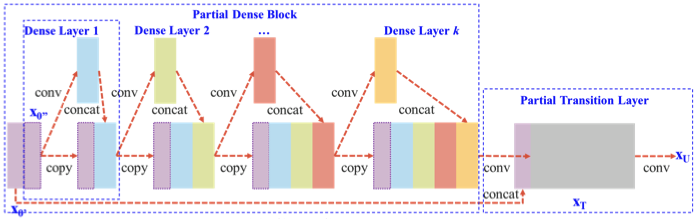
- augmentation
mosaic, Self-Adversarial Training (SAT), modified SAM, modified PAN, Cross mini-Batch Normalization (CmBN)
- neck : SPP + PAN
- dense prediction : YOLO v3
RetinaNet
2 stage detector들은 region proposal에서 background sample들을 제거하지만, 1 stage detector들은 anchor box의 대부분이 background에 해당하는 negative sample이다. 따라서 class의 대부분을 background가 차지하는 class imbalance 문제가 생기게 된다.
이를 해결하기 위해서 RetinaNet은 focal loss를 도입했다. focal loss는 cross entropy loss에 scaling factor를 도입하여, 쉬운 예제에는 작은 가중치를 부여하고 어려운 예제에는 큰 가중치를 부여하여 어려운 예제에 집중하도록 만드는 것이다. 이를 이용하면 배경에 대한 과도한 학습을 방지하고 실제 객체에 대한 학습 성능을 높일 수 있다.
M2Det
기존에 사용하던 feature pyramid는 classification task를 위해 설계된 것이라 object detection을 수행하기에는 충분하지 않은 면도 있다. 게다가 feature map은 single-level layer로서 single-level의 정보만 나타낸다. 이는 즉 하나의 feature map 내에서도 복잡한 외형과 간단한 외형을 탐지하는 데 성능 차이가 발생한다는 것이다. (보통 하위 level의 feature은 간단한 외형, 상위 level의 feature는 복잡한 외형을 잘 찾는다.)
따라서 M2Det은 multi-scale (→ 다양한 크기의 객체 탐지) 뿐만 아니라 multi-level (→ 단순 ~ 복잡까지 다양한 외형 탐지) 를 다루는 feature pyramid인 MLFPN을 고안하였다.
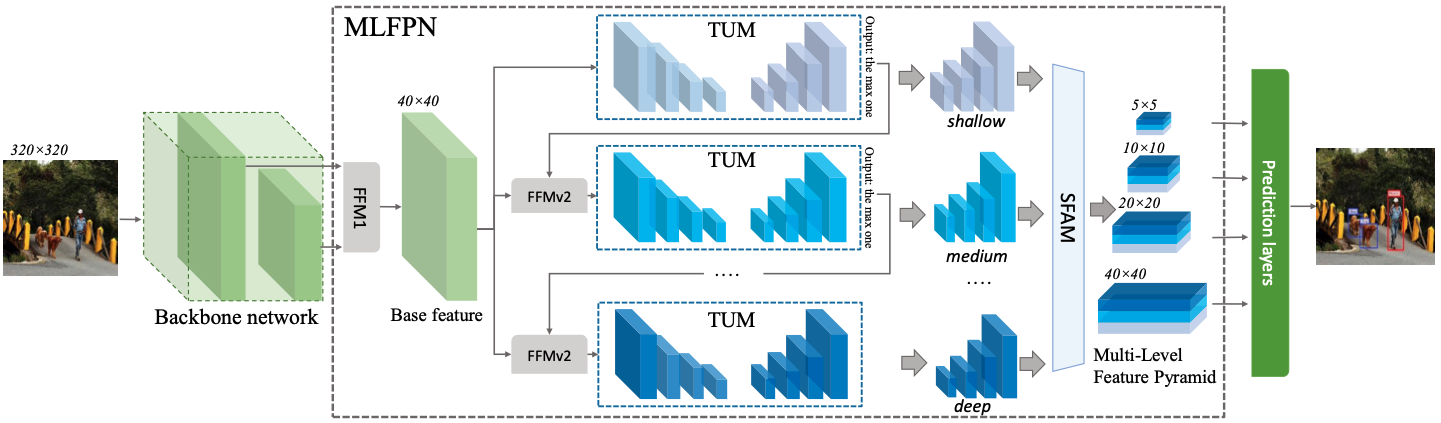
전체적인 architecture는 위 그림과 같다.
- FFMv1 (Feature Fusion Module)
backbone network에서 나온 서로 다른 scale의 feature map 2개를 합쳐 semantic 정보가 풍부한 base feature map을 만든다.
- TUM (Thinned U-shape Module)
encoder-decoder 구조로 되어 있으며, base feature map이 통과하면서 다양한 스케일의 이미지가 생성된다. M2Det 논문에서는 8개의 TUM을 사용하였다.
- FFMv2
base feature map과 이전 TUM 출력 중 가장 큰 feature map을 합쳐서 다음 TUM에 입력한다.
- SFAM (Scale-wise Feature Aggregation Module)
TUM에서 생성된 multi-level, multi-scale feature map을 합친다. 거기에 channel-wise attention 연산을 수행하여 채널별 가중치를 계산하여 각각의 feature를 강화하거나 약화시킨다.
- Detection stage
8개의 TUM을 통과하고 나면 6개의 scale feature가 출력되는데 6개의 feature마다 2개의 convolution layer를 추가해서 regression, classification을 수행한다.
6개의 anchor box를 사용하고 soft-NMS를 사용하여 후보 영역을 골라낸다.
이 architecture가 동작하면 결과적으로 multi-level, multi-scale feature map을 얻게 된다. shallow level에서는 단순한 외형, deep level에서는 복잡한 외형을 잘 찾을 수 있으므로 M2Det을 이용하여 다양한 크기의 물체 뿐만 아니라 다양한 외형의 물체를 모두 잘 탐지할 수 있게 된다.
CornerNet
기존의 object detection 모델들은 anchor box를 만들어 물체를 탐지하는 것에 이용하였지만 anchor box의 수가 굉장히 많이 나오고, 또 대부분이 배경인 negative sample이라 class imbalance 문제가 생긴다. 또, anchor box와 관련된 하이퍼 파라미터 (개수, 사이즈, 가로세로 비 등)를 고려하는 것도 까다로운 문제이다.
그래서 CornerNet에서는 anchor box 없이, 물체가 있을 법한 위치의 top-left, bottom-right 점을 이용하여 객체를 검출하는 방법을 고안했다.
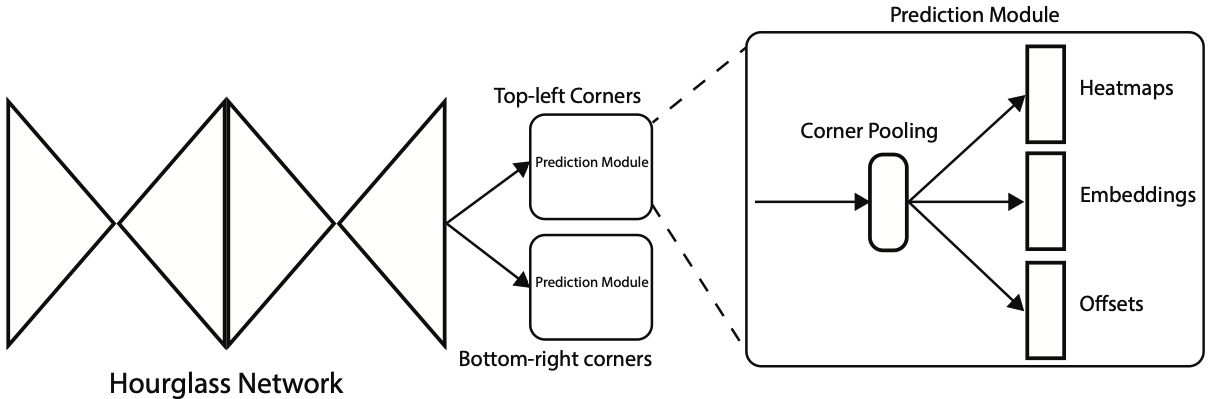
전체적인 architecture는 위 그림과 같다.
- Hourglass network
- 입력 이미지가 hourglass network를 통과하며 feature map이 출력 (global, local 정보 모두 추출 가능)
- encoder-decoder 구조
- Prediction module
- hourglass network로 생성된 feature map으로부터 2개의 prediction module은 각각 top-left corner, bottom-right corner를 예측
- corner pooling을 통해 heatmap, embedding offset을 예측
heatmap은 corner의 좌표를 표시한 map, offset은 좌표를 조정하는데 쓰이는 정보, embedding은 top-left corner와 bottom-right corner의 짝을 맞춰주는 정보이다.
* corner pooling : bbox를 보면 알겠지만 보통 bbox의 모서리 부분은 배경 부분에 위치하여 특징을 잡기 어려운 경우가 많다. 따라서 이런 환경에서도 모서리의 위치를 보다 정밀하게 찾기 위해서, 모서리에 객체의 정보를 집약시키는 기술이 corner pooling이다.
이외에도
- CenterNet : 중심점을 예측하여 단 하나의 anchor box를 생성하는 모델
- FCOS : 중심점으로부터 bbox 경계까지의 거리를 예측하는 모델
등이 있다.
