* 2 stage detector 초기 모델부터 공부하려면 이 포스팅 참조
기존의 Fast R-CNN에서 IoU를 0.5로 고정해서 posivie sample과 negative sample을 나누어 학습했었는데 0.6, 0.7로 바꾸면 성능이 어떻게 변화할까? IoU가 높을수록 False Positive가 줄어드는 모습을 볼 수 있다. 정확히 말하자면 input IoU가 높을수록 높은 IoU threshold에서 학습된 모델이 보다 더 좋은 localization performance를 낸다. input IoU가 낮으면 낮은 threshold에서 학습된 모델이 더 좋은 localization performance를 낸다. detection performance의 경우, IoU threshold가 높을수록 높은 IoU threshold에서 학습된 모델이 더 좋은 성능을 보인다.
cascade R-CNN
위의 실험 내용을 정리하면, 단순히 IoU를 높인다고 해서 성능이 무조건 향상되는 것이 아니라는 것이다. 그래서 IoU 값에 따라 성능을 체계적으로 향상시키기 위해서 cascasde R-CNN가 고안되었다.
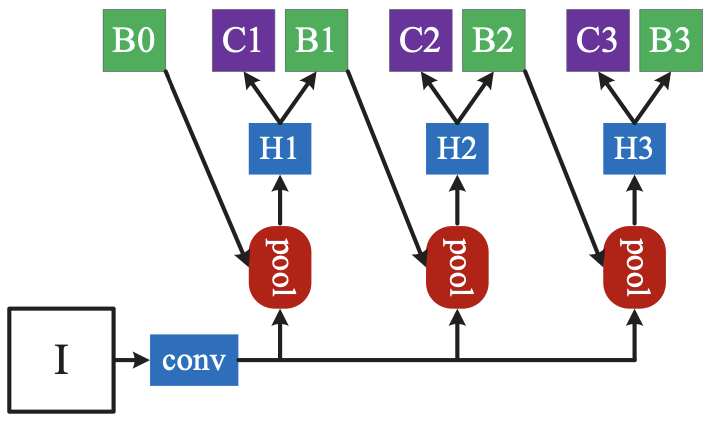
IoU threshold에 따라서 RoI head를 여러 개 두고 학습시킨다.
- bbox pooling (이전 threshold의 box가 다음 pooling의 input으로 들어감)을 반복수행해서 성능 향상
- IoU threshold가 다른 classifier가 반복될 때 성능 향상
- IoU threshold가 다른 RoI head를 cascade로 쌓으 시 성능 향상
Deformable Convolutional Networks
일반적인 convolution 연산만을 사용하면 고정된 filter size를 갖기 때문에 같은 이미지라 하더라도 geometric transform (기울이기, 시점 변환, 포즈 변환 등)이 가해졌을 때 같은 이미지로 인식하지 못하는 문제점이 있다. 그리고 geometric invariant feature selection을 하더라도 사람이 인지하지 못한 feature는 학습시키지 못한다는 단점이 있다.
deformable convolution은 convolutional filter size를 고정된 형태가 아니라 geometric 연산에 맞게 변형할 수 있도록 해서 기존의 단점을 극복하고자 했다. offset을 학습시켜서 위치를 유동적으로 변화시키는 것이다. kernel의 각 값마다 random offset을 주거나, 팽창, 회전하는 형태의 offset을 줄 수도 있다.
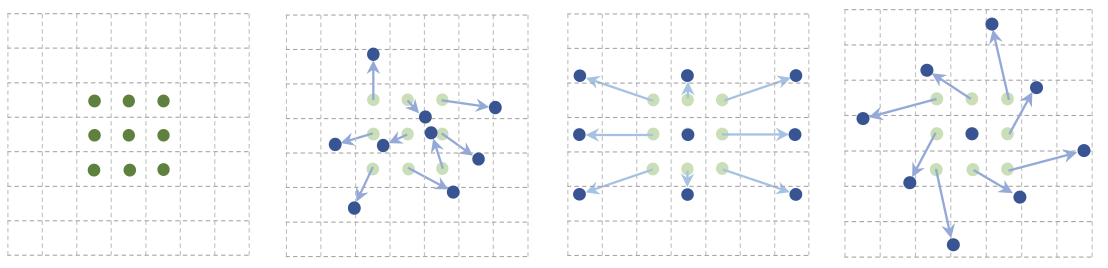
고정된 filter size의 패턴이 아니라 offset을 학습시키면 객체가 있을 법한 위치를 더 잘 학습하고 detection할 수 있게 된다.
DETR
DETR (End-to-End Object DEtection with TRansformer)은 Transformer를 object detection에 처음 적용한 모델이다. 기존의 detection 모델들은 후보 bbox들이 많이 생성되어 그 bbox들을 class score 순으로 나열한 뒤 NMS 알고리즘을 이용하여 하나의 가장 적절한 bbox를 골라내는 과정을 거쳤다. 그러나 object detection에 transformer를 도입함으로써 이 단계를 없앨 수 있었다.

backbone은 CNN을 사용했고, CNN에서 나온 highest level featue map만을 transformer에 통과시키고 prediction head에 입력해 box를 설정했다. 이 때 N (> 한 이미지에 존재하는 object 개수)개의 output이 나오도록 하고, groundtruth에서 부족한 수를 no object (background)로 padding처리하여 N:N 매핑을 한다. 따라서, NMS 등의 post-process가 필요 없게 된다.
Swin Transformer
Transformer는 그 특성상 계산 비용이 매우 큰데, swin transformer는 CNN과 유사한 구조로 설계하고 window라는 개념을 활용해 계산 비용을 줄였다.
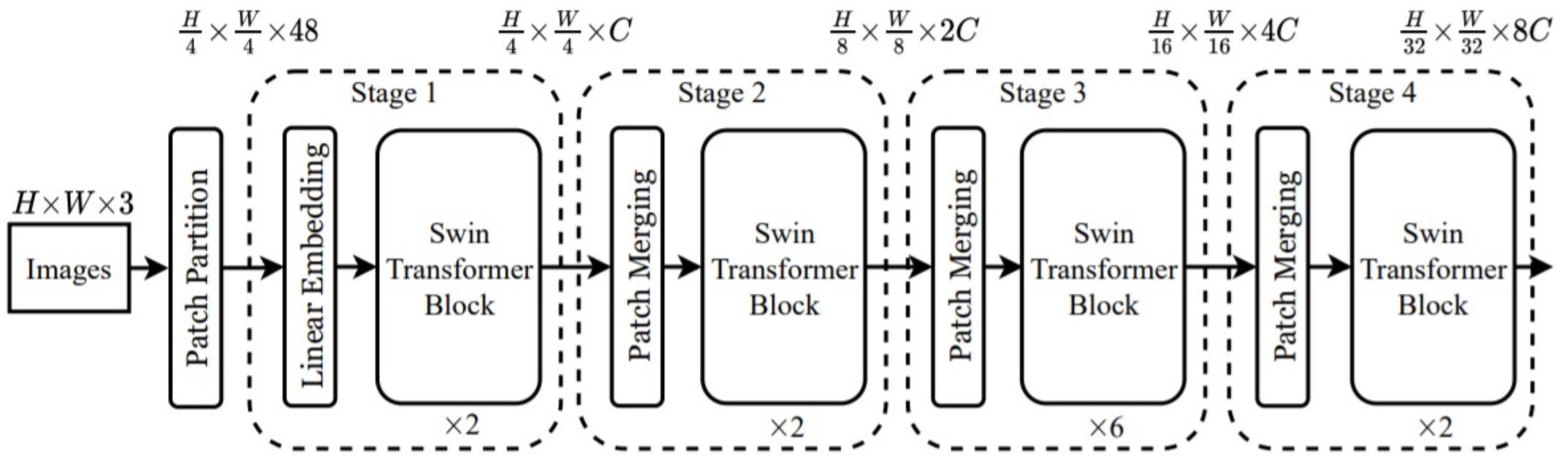
전체적인 구조는 위의 그림과 같은데, transformer를 N개로 나누어 실행하는 것이 특징이다. 각 stage로 넘어갈 때 feature map의 size를 1/2로 줄여준다.
- Patch partitioning
이미지를 패치로 나눈다.
- Linear embedding
classification이 아니라 detection이 더 주요 task이므로 class embedding 제거
-
Swin transformer block
attention layer 2개가 모여 하나의 transformer block이 된다.
multi-head attention 대신 Window Multihead Self Attention (W-MSA)를 도입했다. embedding을 window 단위로 나누어서 window 안에서 transformer 연산을 수행한다. 그러나 window 안에서만 연산이 일어나 receptive field가 제한되는 한계가 있어서, 두 번째 attention layer에서 Shifted Window Multihead Self Attention (SW-MSA)를 이용하여 window를 다르게 설정한 것으로 transformer 연산을 수행해서 보완했다. 이렇게 window를 사용하면 계산 비용이 훨씬 줄어든다. -
Patch merging
feature size를 줄이고 channel-wise하게 concat해서 채널을 늘린다.
