Computer Vision 분야에서 가장 대표적으로 쓰이는 CNN과 최근 주목받고 있는 ViT (Vision Transformer), 그리고 그들의 hybrid model에 대해서 알아보자.
CNN (Convolutional Neural Network)
- grid 형태의 데이터 (ex) 이미지) 를 처리하도록 설계됨
- convolutional layer, pooling layer, fully connected layer로 구성됨
- 시각적 특징의 계층적 표현을 학습함
ConvNeXt
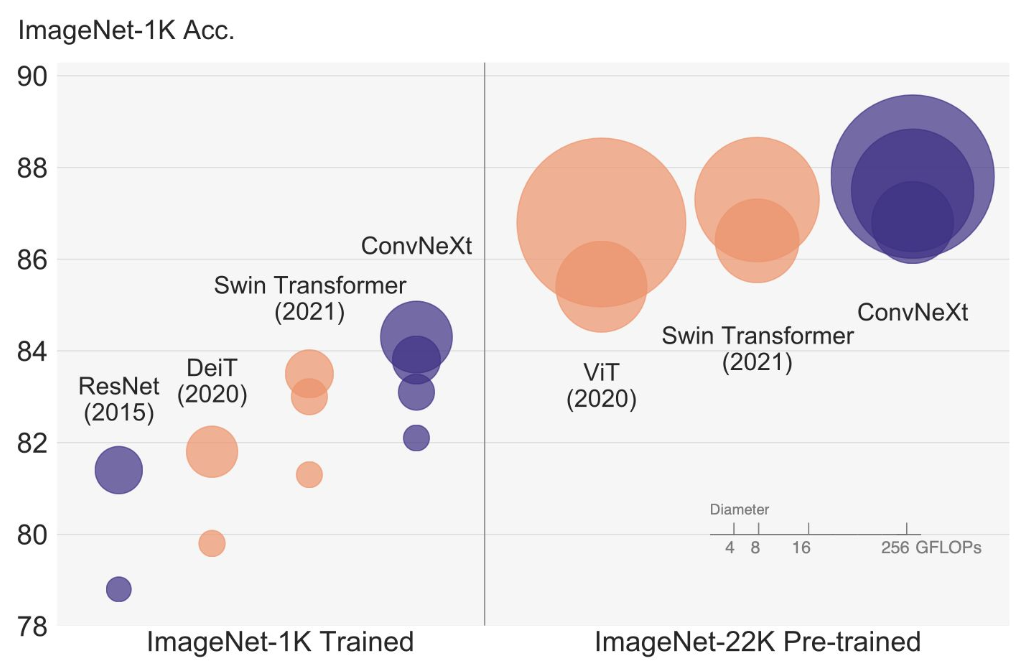
- CNN의 강점을 최대한 활용하면서도 최신 딥러닝 기법들을 도입한 모델
- depthwise convolution : Convolution 연산을 더 효율적으로 수행하기 위해, Depthwise Convolutions와 Pointwise Convolutions로 나누어 연산을 최적화
- Layer Normalization : 더 안정적인 신경망 학습 & 트랜스포머의 효과적인 학습 기법 도입
- 7 7 kernel : 기존의 3 3 kernel보다 더 큰 커널을 사용해 더 넓은 범위에서 특징을 추출. ViT의 patch와 유사한 역할을 함.
- GELU activation function
- inverted bottleneck : 파라미터 효율성을 극대화하고 연산량을 줄여 성능 최적화
- ConvNeXt는 ViT와 비슷한 성능을 내면서도 구조가 비교적 단순하고 연산이 효율적이다. 대규모 데이터에서는 ViT가 더 좋은 성능을 발휘하지만, 작은 데이터셋에서는 ConvNeXt가 더 유리할 수 있다.
ViT
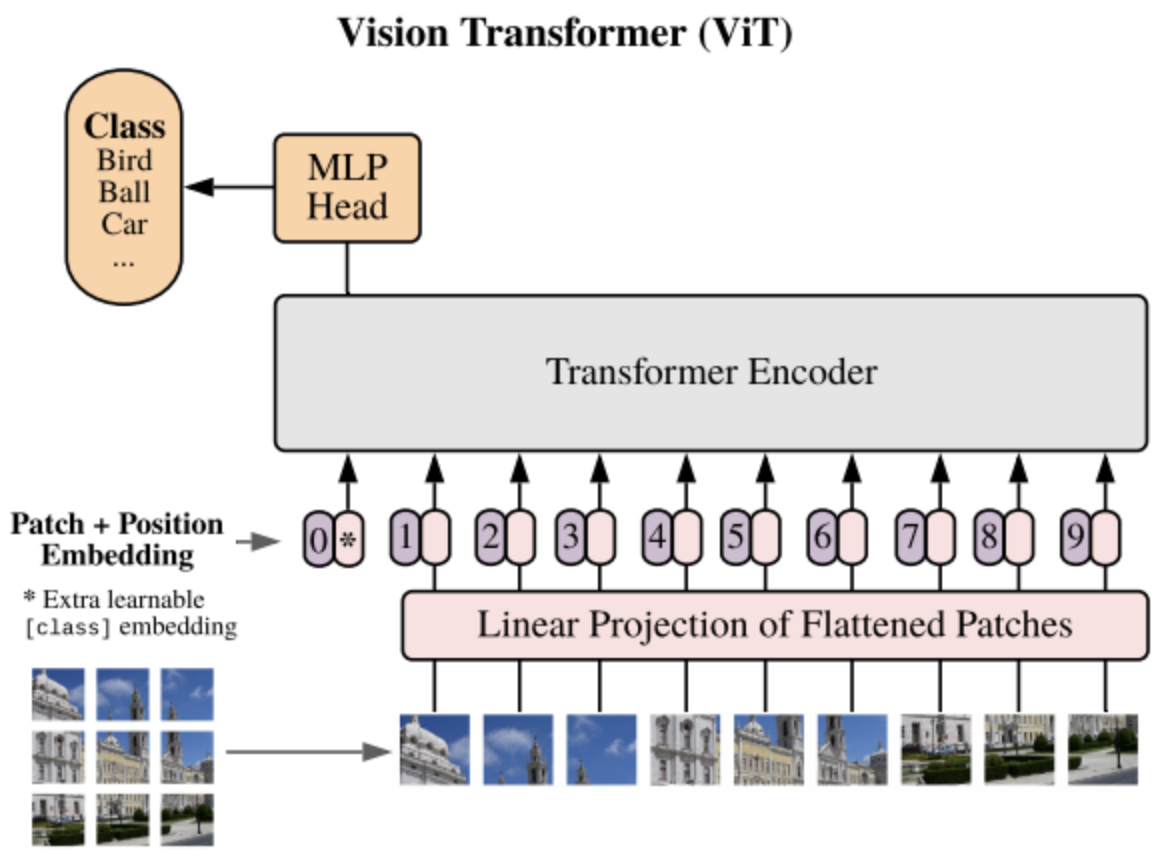
- NLP 분야에서 쓰이는 transformer를 computer vision 분야에 적용한 모델
- patch embedding : 이미지를 패치로 분할하고, 평탄화된 패치르르 선형으로 투영한다. 학습 가능한 위치 임베딩을 추가한다.
- encoder : self-attention과 feed-forward layer가 쌓여 있어 계층적 패치 표현을 학습
- classification head : global average pooling, 선형 layer가 있으며 클래스의 확률을 예측
CNN vs ViT
| 제목 | CNN | ViT |
|---|---|---|
| local pattern 학습 | ⭕️ | ❌ |
| 계산 효율성 | ⭕️ | ❌ |
| 가변 크기 입력 | ❌ | ⭕️ |
| 장거리 의존성 | ❌ | ⭕️ |
| 데이터 효율성 | ⭕️ | ❌ |
hybrid model
각기 다른 CNN과 ViT를 합친다면, 서로의 단점은 보완하면서 장점은 활용하는 좋은 모델을 만들 수 있을 것이다. 이렇게 CNN과 ViT를 합친 hybrid model의 대표적인 예가 CoAtNet이다.
CoAtNet

- s-stage 설계 : C-C-T-T layout (C = Convolutional, T = Transformer)
- 점진적인 해상도 감소와 채널 증가
- 적은 데이터로 더 나은 generalization
- 더 빠른 수렴
- 향상된 학습 efficiency
- 더 큰 data set에 대한 우수한 scalability
- ViT보다 적은 사전 학습 데이터와 계산량 필요
이외에도 ConViT, CvT, LocalViT 등의 hybrid 모델들이 있다.
References
https://arxiv.org/abs/2201.03545
https://paperswithcode.com/method/vision-transformer
https://arxiv.org/abs/2106.04803

Let it code