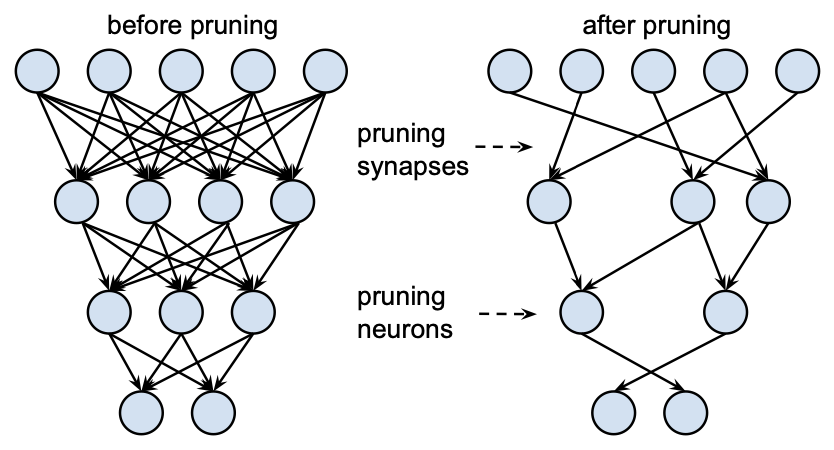
pruning(가지치기)는 학습된 모델에서 중요도가 낮은 뉴런이나 연결(시냅스)을 제거하여 모델의 크기와 계산 비용을 줄이는 기법이다. pruning을 통해 메모리 사용을 줄이고 연산 속도를 높일 수 있다.
pruning은 크게 structure, scoring, scheduling, initialization 4가지 관점에서 접근할 수 있다.
Pruning 기법의 분류
structure
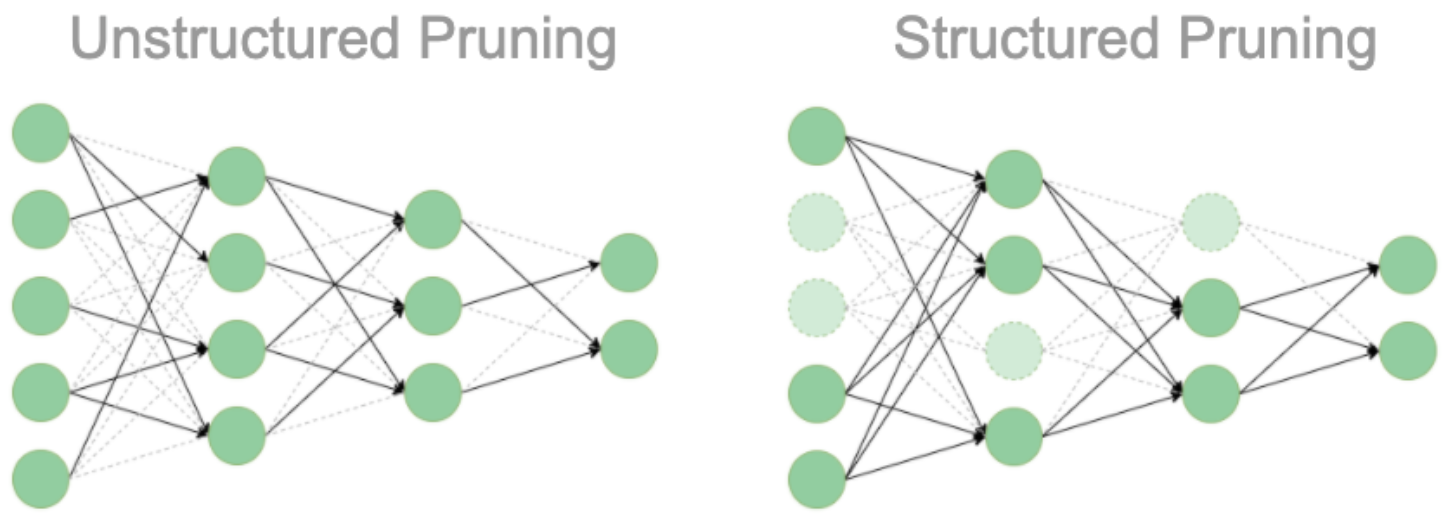
모델의 구조가 변경되느냐 변경되지 않느냐에 따라 structured pruning, unstructured pruning으로 구분할 수 있다. structured pruning은 뉴런, 채널, 혹은 레이어 전체를 제거하여 모델 구조가 변경되는 방식이다. unstructured pruning은 연결된 가중치를 독립적으로 제거하는 방식이다. 개별 파라미터 단위로 중요도가 낮은 값을 0으로 변경하기 때문에 모델 구조에는 변화가 없다.
| 방법 | 단위 | 구조 변경 | 장점 | 단점 |
|---|---|---|---|---|
| unstructured | 개별 파라미터 | 없음 | 구현이 쉬움 | 연산 속도 향상 X |
| structured | 구조 | 있음 | 연산 속도 향상 | 구현이 어렵거나 불가능 |
scoring
scoring 관점에서 pruning은, 가지치기를 할 파라미터를 선정하는 방법(중요도)에 따라 구분하는 것이다. 이는 다시 "중요도를 계산하는 방법"과 "계산된 중요도를 반영할 단위"의 관점에서 생각해볼 수 있다.
먼저 "중요도를 계산하는 방법"의 관점에서는, 파라미터 별로 절댓값을 기준으로 중요도를 설정하는 방법과 레이어 별로 L-norm을 기준으로 중요도를 설정하는 방법이 있다.
파라미터 별로 절댓값을 기준으로 중요도를 결정하는 것은 아래와 같이 파라미터가 있을 때 절댓값이 작은 -2, 1을 pruning해서 0으로 대체하는 것이다.
→
레이어 별로 L-norm을 기준으로 중요도를 설정하는 방법은, 레이어 별로 L-norm을 계산해서 더 작은 값의 레이어를 pruning하는 것이다. L-norm을 기준으로 계산한다고 하면, 위쪽 레이어 (3, -2)의 L-norm은 , 아래쪽 레이어 (1, -5)의 L-norm은 이므로 위쪽 레이어가 pruning된다.
→
"계산된 중요도를 반영할 단위"의 관점에서는, 중요도를 전체 모델에서 비교하는 방법(global pruning)과 특정 단위별(ex) 레이어별)로 비교하는 방법(local pruning)이 있다.
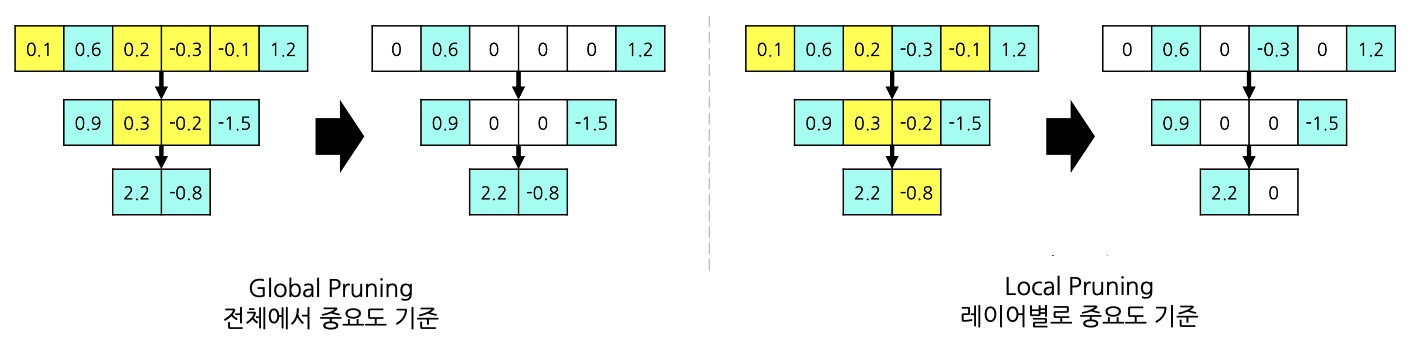
예를 들어 하위 50%의 파라미터를 가지치기 한다고 했을 때, global pruning에서는 모델 전체에서 하위 50%의 파라미터를 잘라내지만, local pruning에서는 레이어별로 하위 50%의 파라미터를 잘라내기 때문에 두 방법에서 가지치기된 파라미터가 다른 모습을 볼 수 있다.
| 방법 | 단위 | 장점 | 단점 |
|---|---|---|---|
| global | 전체 모델 | 중요한 레이어 보존 | 계산량이 많음 |
| local | 레이어 | 특정 레이어에 pruning이 편중되지 않음 | 중요한 레이어가 과도하게 pruning 될 수 있음 |
scheduling
scheduling 관점에서 pruning은, 가지치기를 몇 번 할 것인지에 따라 구분하는 것이다. one-shot은 pruning을 한 번만 하는 것으로, 시간은 짧게 걸리지만 성능이 불안정하다. recursive는 pruning을 조금씩 여러 번으로 나누어 진행하는 것으로, 시간이 오래 걸리는 대신 성능이 안정적이다.
initialization
initialization 관점에서 pruning은, 가지치기를 한 후 fine-tuning 재학습을 할 때 어떤 상태에서 시작할 지에 따라 구분하는 것이다. 크게 pruning 직후의 상태를 그대로 이어서 fine-tuning을 진행하는 weight-preserving(classic) 방식과 랜덤 값으로 초기화 후에 fine-tuning을 하는 weight-reinitializing(rewinding) 방식으로 구분할 수 있다.
전자는 학습 및 수렴이 빠르지만 성능이 불안정한 반면, 후자는 학습에 시간이 더 걸리지만 성능이 더 안정적이다.
⭐️ Iterative Magnitude Pruning
가장 기본적인 pruning 방법으로, 1) unstructured 2) global (파라미터별 절대값), 3) recursive, 4) rewinding을 이용하여 가지치기 하는 기법이다.
더 고려할 내용들
Matrix Sparsity 문제
우선 matrix가 sparse하다는 것은, 행렬의 대부분의 요소가 0인 상태를 말한다.
density = = 1 - sparsity
sparsity = = 1 - density
unstructured pruning의 경우, 중요도가 낮은 파라미터 값을 0으로 바꾸게 되는데, 여전히 0이라는 데이터가 존재하고 이를 연산에 사용하기 때문에 계산 속도가 향상되지 않는다. 따라서 sparsity 정도에 따라 다른 조치를 취해주는 것이 중요하다.
Sparse Matrix Representation
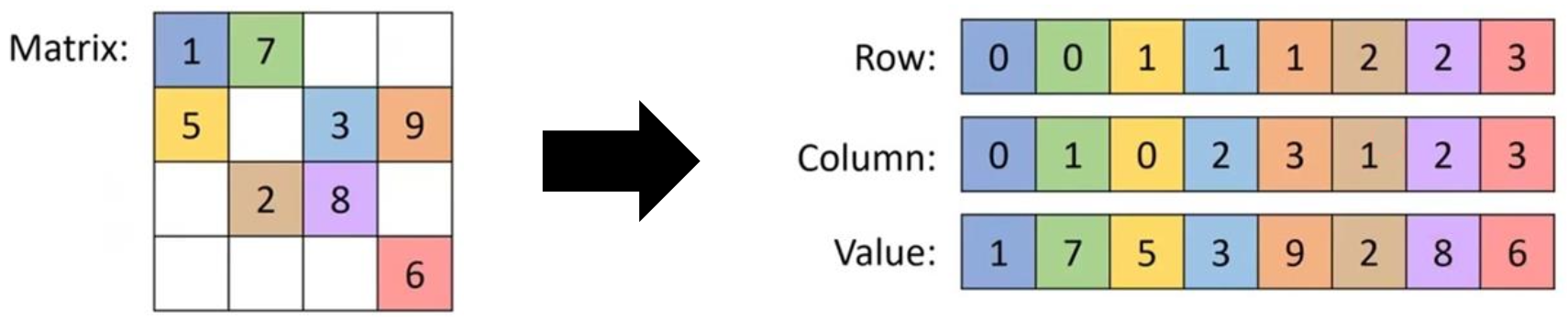
sparsity가 심한 경우 (0인 요소가 전체의 2/3 이상일 때) 에 효율적으로 사용할 수 있는 방법이다. (n m 행렬에서 k개의 0이 아닌 요소가 있다고 하면, nm > 3k일 때)
행렬에서 0이 아닌 값들의 좌표를 기억하여 연산에 활용하는 방식이다. 이 방법을 이용하면 메모리 효율이 증가하고 연산 속도가 향상된다.
전용 하드웨어 사용
sparsity의 정도가 심하지 않은 경우에는 전용 하드웨어(ex) NVIDIA tensor core)를 사용하여 0의 위치를 스캔하고 해당 위치를 건너뛰고 계산하도록 조정하는 방식이다.
Sensitivity
sensitivity(민감도)란, 파라미터나 레이어를 가지치기 했을 때 전체 성능이 변하는 정도이다. 어떤 레이어나 파라미터를 제거했을 때, 성능이 크게 저하된다면 해당 파라미터나 레이어는 sensitivity가 큰 것이다. 따라서 sensitivity가 상대적으로 적은 파라미터나 레이어를 찾아서 제거해야 성능은 유지하면서 메모리와 연산 속도를 절감할 수 있다. 일반적으로는 가장 앞 부분의 레이어가 민감하고, 뒷 부분의 레이어가 덜 민감하다. 일반적으로 empirical하게 레이어 별로, pruning한 비율 별로 sensitivity를 측정해보면서 pruning을 하게 된다.
In practice
CNN에서의 pruning
CNN 모델은 보통 CNN(Convolutional Neural Network)과 FC(Fully-Connected) layer로 구성되어 있다. 대부분의 파라미터는 FC layer에 있고, 연산 속도의 bottleneck은 CNN에 있기 때문에 공간적, 시간적 효율을 모두 향상시키기 위해서는 FC layer와 CNN을 모두 pruning하는 것이 필요하다.
여기서는 우선 CNN의 pruning만 다루도록 하겠다. CNN 레이어는 여러 필터로 구성되어 있는데, 그 중에서 중요도가 상대적으로 낮은 필터를 제거하는 방법이 대부분이다. 중요도는 sparsity 또는 L2-norm 값을 기준으로 판별한다. Unstructured pruning을 하기 위해서는 sparse convolution 연산을 구현해야 한다.
BERT에서의 pruning
BERT(Bidirectional Encoder Representations from Transformer)는 LLM이 나오기 전에 많이 사용된 다용도 언어 모델이다. BERT는 12개의 transformer layer로 이루어져 있다.
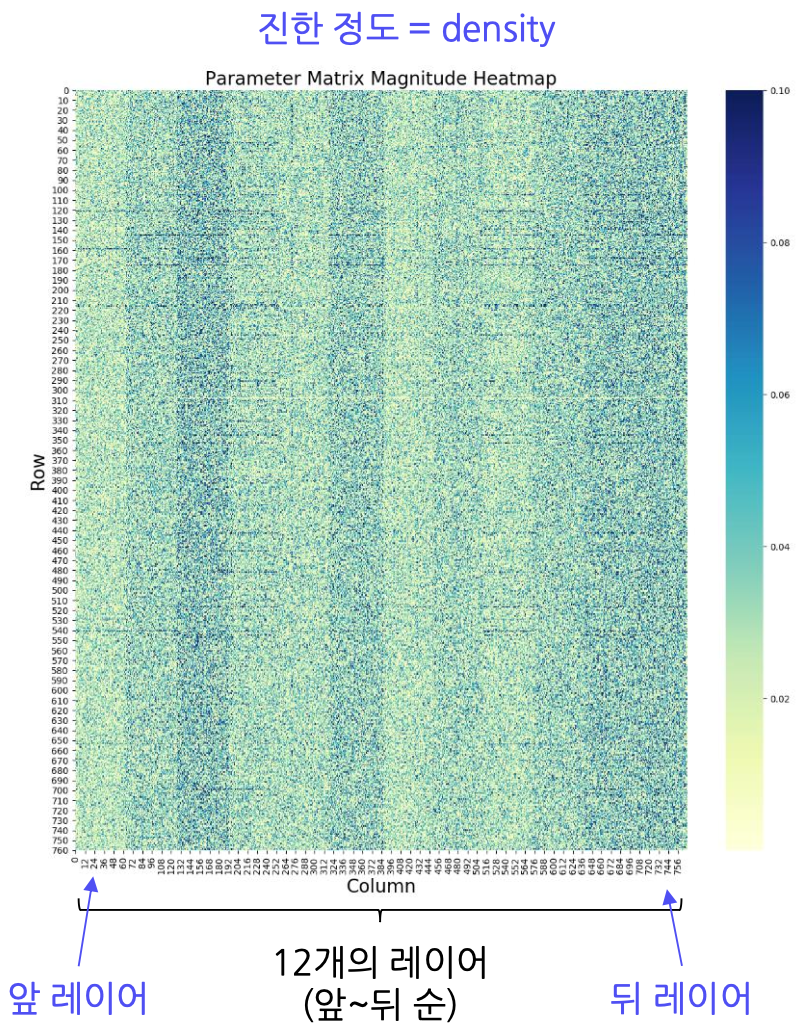
BERT는 앞 레이어에서 작은 형태(단어 등), 뒤 레이어에서 큰 형태(문장 등)를 처리한다. 그러나 위의 그림에서 볼 수 있듯이 레이어 별 sparsity가 일관적이지 않다. 따라서 global pruning이나 structured pruning을 사용할 경우 성능이 크게 떨어질 위험이 있다. 그러나 대부분의 파라미터가 0에 가깝기 때문에, 절댓값을 기준으로 한 pruning이 효과적이다. 보다 작은 형태를 다루는 앞 레이어에서, 짧은 단어일수록 더 sparse한 벡터로 인코딩되기 때문에 local pruning을 하면 성능 저하를 줄이면서 경량화를 할 수 있다.
코드
import torch.nn.utils.prune as prune
# 간단한 예시를 위한 2-layer MLP 모델
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(2, 10)
self.fc2 = nn.Linear(10, 2)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
# 모델 선언
model = Model()
# 학습 & 테스트
train(model, train_data)
test(model, test_data) # pruning 전
# 파라미터 확인하기
total_params = sum(p.numel() for p in model.parameters()) # 전체 파라미터 수
total_params_nz = sum((p != 0.0).sum() for p in model.parameters()) # 0이 아닌 파라미터의 수
# pruning할 레이어 선언
layer = model.fc1 # layer.weight로 weight tensor 확인 가능
# 랜덤으로 첫 번째 레이어에서 50%를 제거
prune.random_unstructured(layer, name='weight' amount=0.5)
# 파라미터 절댓값 하위 50%를 제거
prune.l1_unstructured(layer, name='weight', amount=0.5)
# 다시 학습 데이터에 fine-tuning
train(model, train_data)
# pruning & fine-tuning 후 성능 확인하기
test(model, test_data)References
https://arxiv.org/abs/1506.02626
https://opendatascience.com/what-is-pruning-in-machine-learning/
https://onlinelibrary.wiley.com/doi/10.1155/2021/2485934
https://arxiv.org/abs/2002.08307
