1. Introduction
Text-to-image model의 inefficiency는 다음 두 가지가 주요 요인이다.
- 1) iterative denosing
- 2) complex model architecture
이전의 연구들은 주로 1)에 주목하여 연구를 진행하였다. 하지만 text-to-image 모델 자체가 매우 크기 때문에 적은 수의 denosing step을 가지더라도 inefficiency를 해결하기 어렵다.
이번 논문에서는 새로운 text-to-image 모델 구조를 제안한다. 그리고 이전에 활발히 연구되었던 reducing sampling steps 기법과 결합하여 efficient text-to-image 모델을 제시하였다.
2. MobileDiffsuion
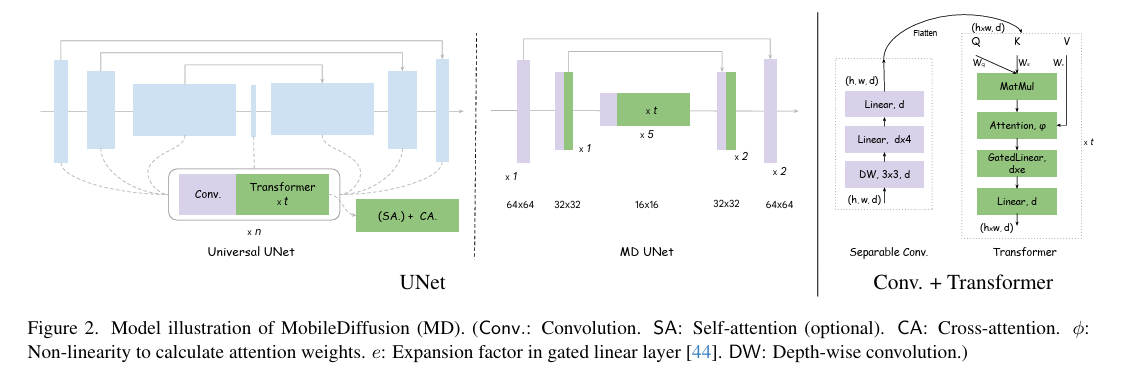
2.1 UNet Optimization
UNet은 transformer block과 convolution block이 interleave 하는 방식으로 구성되어 있다. 논문에서는 각각의 block을 나누어 optimization 방식을 설명한다. 논문에서는 Stable Diffusion의 UNet을 가지고 Optimization을 진행하였다.
Transformer block
Transformer block은 다음 세 가지 요소로 구성되어 있다.
- self-attention(SA)
visual features의 long-range dependency를 처리 - cross-attention(CA)
text condition과 visual features 사이의 interaction을 capture - feed-forward(FF)
attention의 output을 post-process
Attention operation은 computaional cost가 매우 높다. 따라서 논문에서는 attention의 computation 부담을 줄이기 위해 high resolution에서 transformer block을 줄이고 low resolution에 transformer block을 더 하는 방식을 base로 optimization을 진행하였다.
More Transformers in the middle of UNet
High resolution transformer blocks을 low resolution으로 replacing 하였다. 이때 기존의 total parameter 수를 유지하기 위해 low resolution의 feature map channel 수가 감소하도록 layer를 수정하였다.
Decouple SA from CA
Attention operation의 높은 computation cost는 visual features가 가지는 long sequence length 때문이다. (e.g. 32 x 32 feature map = 1024 seq length) 이에 반해 text encoding vector의 sequence length는 상대적으로 작다. 따라서 논문에서는 high resolution에 존재하는 transformer block에서 SA만 제거하고 CA는 남겨 놓는 방법을 제시한다.
Share Key-value Projections
Attention의 key, value vector를 얻기 위해 사용되는 projection weight 를 공유하는 방식을 제안했다.(i.e. ) 이 방법을 통해 모델의 parameter 수를 줄이는 것이 가능하다.
Replace gelu with swish
gelu activation function은 연산에 비효율적이다. 따라서 논문에서는 gelu 와 비슷한 형태를 지니면서 연산에 효율적인 swish 로 gelu activation을 대체하였다.
Finetune softmax into relu
Attention value 계산을 위한 softmax function은 연산에 비효율 적이다. 이를 효율적으로 만들기 위해 relu로 대체하였다. 이 방식은 "Replacing softmax with relu in vision transformers" 논문에서 제시되었으며 fine tuning이 필요하다.
Trim Feed-forward Layers
기존 transformer block의 feed-forward은 expansion ratio가 8이다. 논문에서는 실험을 통해 expansion ratio를 6으로 감소했을 때 모델의 성능을 어느 정도 유지한다는 것을 확인하였다. expansion ratio를 6으로 감소하여 모델의 parameter 수를 줄일 수 있다.
Convolution Block
Separable Convolution
UNet의 outer most layer를 제외한 모든 convolution layer를 separable convolution으로변경하였다.
Prune Redundant Residual Blocks
Block 당 한 개의 layer를 두어 22개에서 12개로 layer를 감소시켰다.
2.2 Sample Efficiency
Off-the-self progressive distillation method를 이용하여 sample steps를 8로 줄일 수 있는 것을 확인했다. 반면 diffusion, GAN hybrid 방식(UFOGen)을 이용하면 sample step을 1로 감소시킬 수 있는 것을 확인하였다.
3. Experiments
Quantitative Evaluation
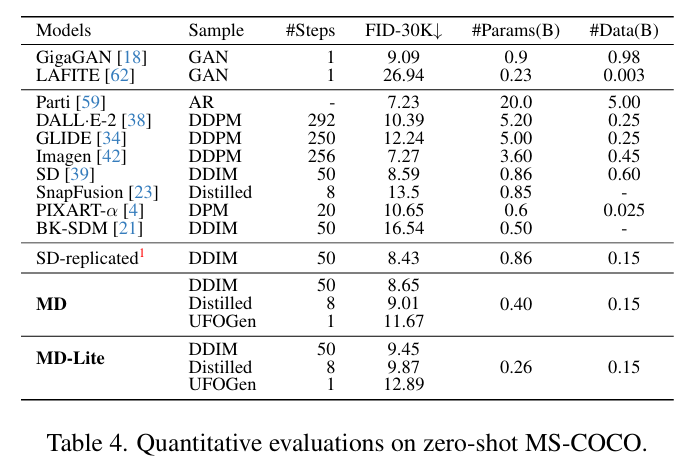
MD에 DDIM sample 기법을 사용하면 SD와 비슷한 수준의 FID를 기록 하였고 distillation method와 UFOGen을 사용한 결과는 comaprable한 결과를 얻었다. MD-Lite는 너 narrow하고 shallow한 UNet을 가진 모델로 더 빠른 속도를 보여주긴 하지만 FID score는 다소 떨어진다.
Qualitative Comparison

MD 가 SD-XL에 비해 다양한 sample method와 비교해 비슷한 수준의 이미지를 생성한다는 점이 주목할만 하다. 이는 MD가 on-device application에 큰 potential을 가지고 있다는 것을 보여준다.
On-device Benchmark
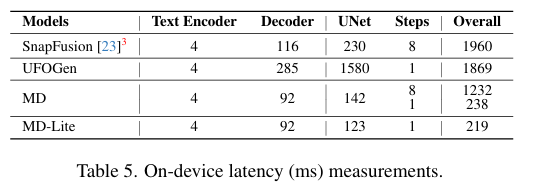
MD가 다른 모델들에 비해 on-device 에서 latency가 크게 낮은 것을 확인 할수 있다. 위 benchmark는 iPhon 15 pro에서 진행 되었다.
Applications

LoRA, ControllNet application task에 대해 efficient sample method가 잘 적용되는 것을 확인 하였다.
4. Conclusions
Mobile diffusion은 diffusion의 UNet 구조를 efficient하게 바꾸는 방식에 대해 연구한 논문이다. 기존에 제시된 efficient architecture 방식들을 더 깊게 연구하고 결합하여 효율적인 UNet 구조를 제시하였고 기존에 많이 연구된 efficient sampling 기법과 결합하여 성공적인 결과를 얻었다. 최근 on-device에 대한 관심이 높아진 만큼 앞으로 mobile diffusion의 인기가 더 높아지고 후속 연구가 더 진행 될 것 같다.
Reference
