
💡 Intro
머신러닝을 공부하는 사람이라면, Kaggle을 알고 있는 사람이라면 한 번쯤은 "House Prices - Advanced Regression Techniques" Competition에 참가해 보았을 것이다. 이 Competition에서 제공하는 Dataset을 활용하여 Submission을 제출해 보자!
✍🏻 Import Library & Data Load
House-Prices dataset은 train data와 test data가 따로 제공되기 때문에 임의로 data를 split할 필요가 없다.
# 필요한 라이브러리 import
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns# train data와 test data 불러오기
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv(('test.csv'))✍🏻 Data 확인하기
train 데이터를 확인해본 결과, 1460개의 데이터, 81개의 column이 있는 것을 확인함.
print(f'train data의 갯수 : {len(train_df)}')
print(f'train data의 column 갯수 : {len(train_df.columns)}')문제점
- column의 갯수가 81개로 매우 많음. 예측 목표인 SalePrice에 영향을 줄 수 있는 column을 선택할 필요가 있음.
- column 설명을 확인한 결과, 부동산 도메인에 대한 지식이 필요함.
Selected Columns
가설: 집의 가격에 영향을 미치는 것은 집의 크기, 위치, 상태일 것이다.
위의 가설에 따라 선택한 Column은 다음과 같다.
- Neighborhood: 집이 위치한 지역(번화가인지 아닌지를 평가할 수 있다고 생각함.)
- OverallCond: 집의 전반적인 상태(0~10의 척도로 평가, 숫자가 높을수록 좋음.)
- YearBuilt: 집이 지어진 시기(오래된 건물은 비교적 가격이 낮을 것임.)
- GrLivArea: 집의 크기(생활할 수 있는 면적)
✍🏻 SalePrice Check
예측의 목표인 SalePrice를 확인해보자! pandas의 describe()를 통해 데이터의 정보를 알 수 있다.
# SalePrice Check
train_df['SalePrice'].describe()output
count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.000000
max 755000.000000
Name: SalePrice, dtype: float64SalePrice 분포 확인
plt.figure(figsize = (12, 6))
sns.histplot(train_df['SalePrice'])
plt.title('Distribution of SalePrice')
plt.xlabel('SalePrice')
plt.ylabel('Counts')
plt.show()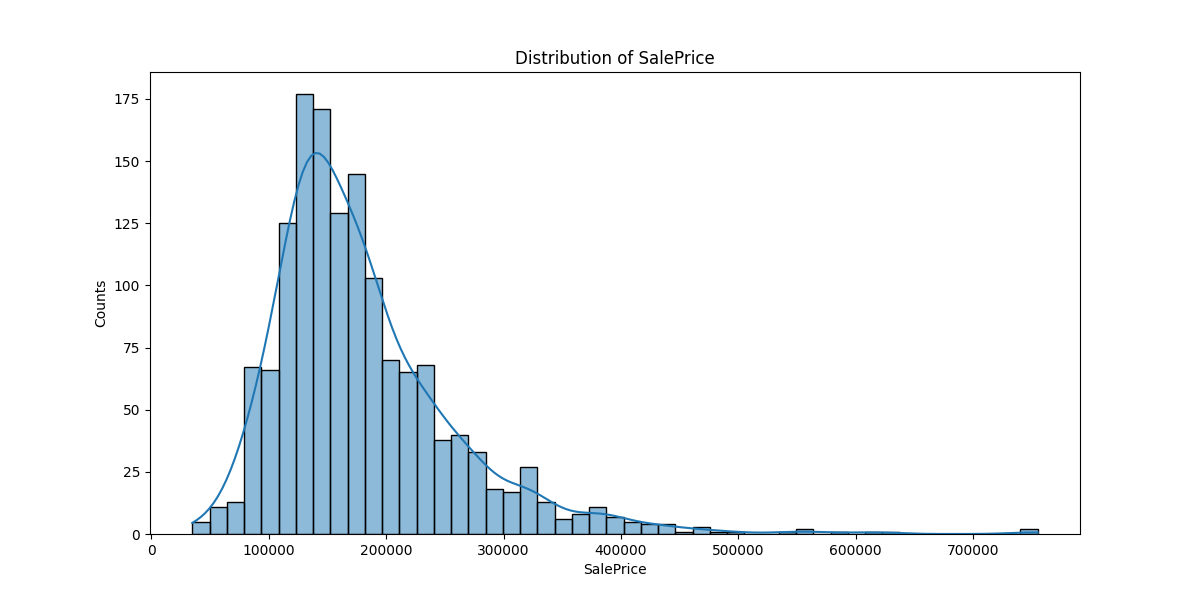
SalePrice의 분포를 확인했으니 왜도와 첨도를 확인해 보자!
# skewness, kurtosis check
print(f'Skewness of SalePrice : {train_df["SalePrice"].skew(): .2f}')
print(f'Kurtosis of SalePrice : {train_df["SalePrice"].kurt(): .2f}')
Skewness of SalePrice : 1.88
Kurtosis of SalePrice : 6.54왜도는 1.88, 첨도는 6.54로 나타났다. SalePrice의 분포는 오른쪽으로 꼬리가 생기지만 비교적 대칭적이고 중앙에 데이터가 모여 있는 것으로 판단할 수 있다.
❓왜도(Skewness)와 첨도(Kurtosis)
왜도: 분포의 비대칭성을 나타낸다. 정규 분포의 경우 왜도가 0인 경우이며 완벽한 대칭을 뜻한다. 오른쪽으로 긴 꼬리가 나타날 경우에는 양수(Positive Skewness)이며 왼쪽으로 긴 꼬리가 나타날 경우에는 음수(Negative Skewness)이다.
첨도: 분포의 뾰족함을 나타낸다. 정규 분포의 경우 첨도가 0인 경우이다. 첨도가 높을수록 데이터가 중앙에 모여있다는 뜻이며 극단값이 많을 수 있다. 첨도가 낮으면 데이터가 중앙값 주위에 퍼져있다는 뜻이다.
© 참고
Stacked Regressions : Top 4% on LeaderBoard
[Kaggle] 보스턴 주택 가격 예측(House Prices: Advanced Regression Techniques)
