Introduction
이번 방학은 역대급으로 아무것도 안 했다. 하루 종일 자고 유튜브 본 거 말고는 별로 한 게 없는 거 같다. 그나마 딥러닝 스터디라도 해서 조금이라도 공부를 할 수 있었다.
우리 과 동기 3명과 함께 딥러닝 스터디를 만들어서 딥러닝 계의 바이블이라고 할 수 있는 <밑바닥부터 시작하는 딥러닝> 을 다 같이 읽어보면서 공부해봤다. 그래도 방학 때 책 한 권이라도 거의 다 읽었다는게 참 다행인 것 같다..
사실 고등학교 때 딥러닝이 뭔지 궁금해서 이 책을 무턱대고 사서 봤을 땐 그냥 읽으면 바로 증발해버리는 수준이었다. 그래도 대학 와서 CS 지식도 좀 생기고 선대도 제대로 배우고 나니까 책 내용이 이해가 되더라.
책 절반 넘게 읽을 때까지는 이해 안 되는 내용이 거의 하나도 없었다. 그런데 5장에서 역전파(Backpropagation) 관련된 내용을 다룰 때 수식이 하나가 나왔는데, 그 수식에서 사고 회로가 그냥 정지해버렸다. 이번 글은 그 수식을 수학적으로 어떻게 증명할 수 있는지를 스스로 공부해본 내용을 정리하고자 한다.
Affine Layer
Affine Layer, 또는 FC Layer (Fully-Connected Layer)라고도 불리는 이 신경망 계층은 뉴런들이 이전 계층의 모든 뉴런과 결합된 형태의 계층을 의미한다. 보통 CNN 같은 신경망의 출력층 부근에 위치하는 계층이라고 한다.
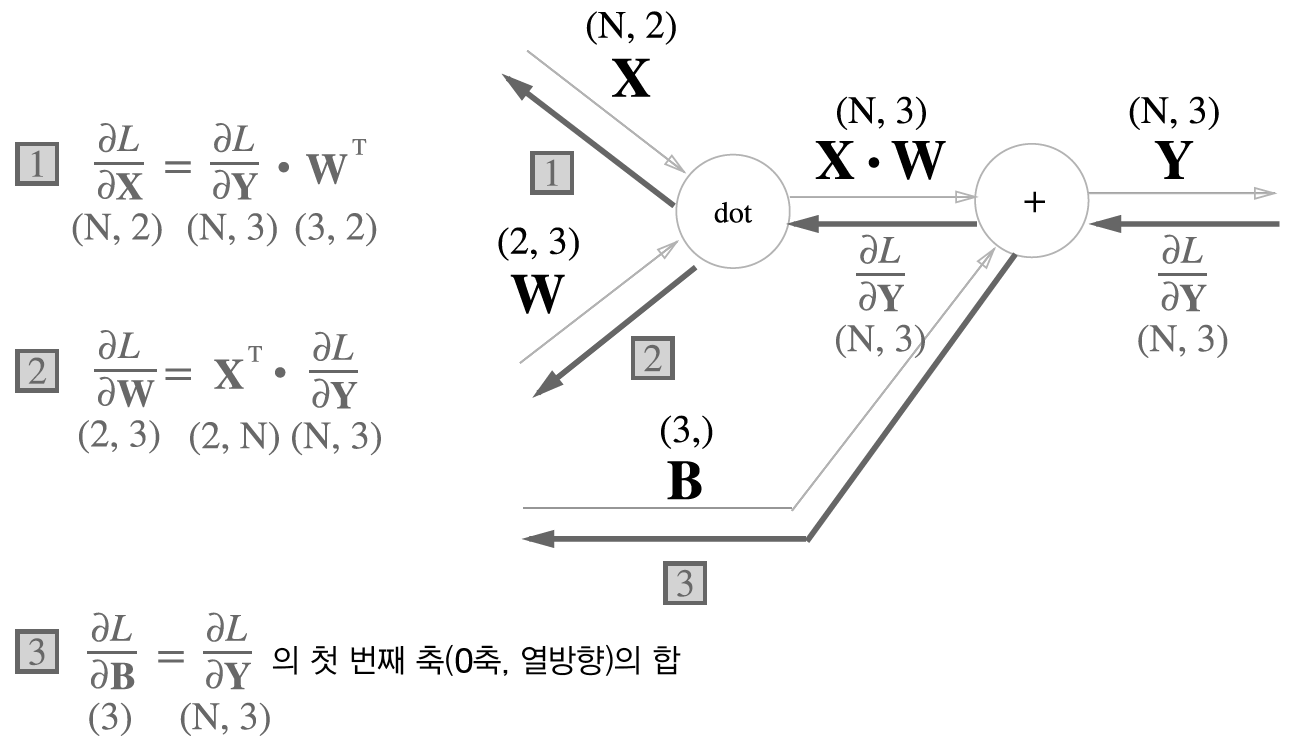
밑바닥부터 시작하는 딥러닝 책에 나오는 예제 그림(그림 5-24)으로 살펴보면,
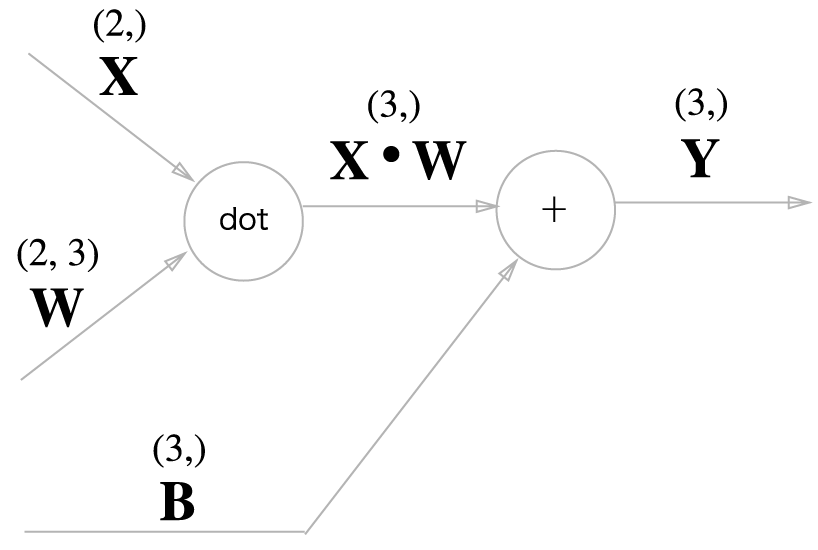
Y=X∙W+B 형태의 수식으로 표현된다고 볼 수 있다. 이때 X는 이전 층에서 들어오는 입력, W는 가중치, B는 편향, Y는 다음 층으로의 출력이다.
이제 이 Affine Layer에서 역전파를 해보자.
일단 이 책을 읽으면 + 연산은 역전파에 아무런 영향을 주지 않는다는 사실을 알 수 있다. 그렇기에 loss에 대한 cost function L에 대해서, 이 계산 그래프에서의 역전파는 다음과 같이 이루어질 것이다. (그림 5-27)
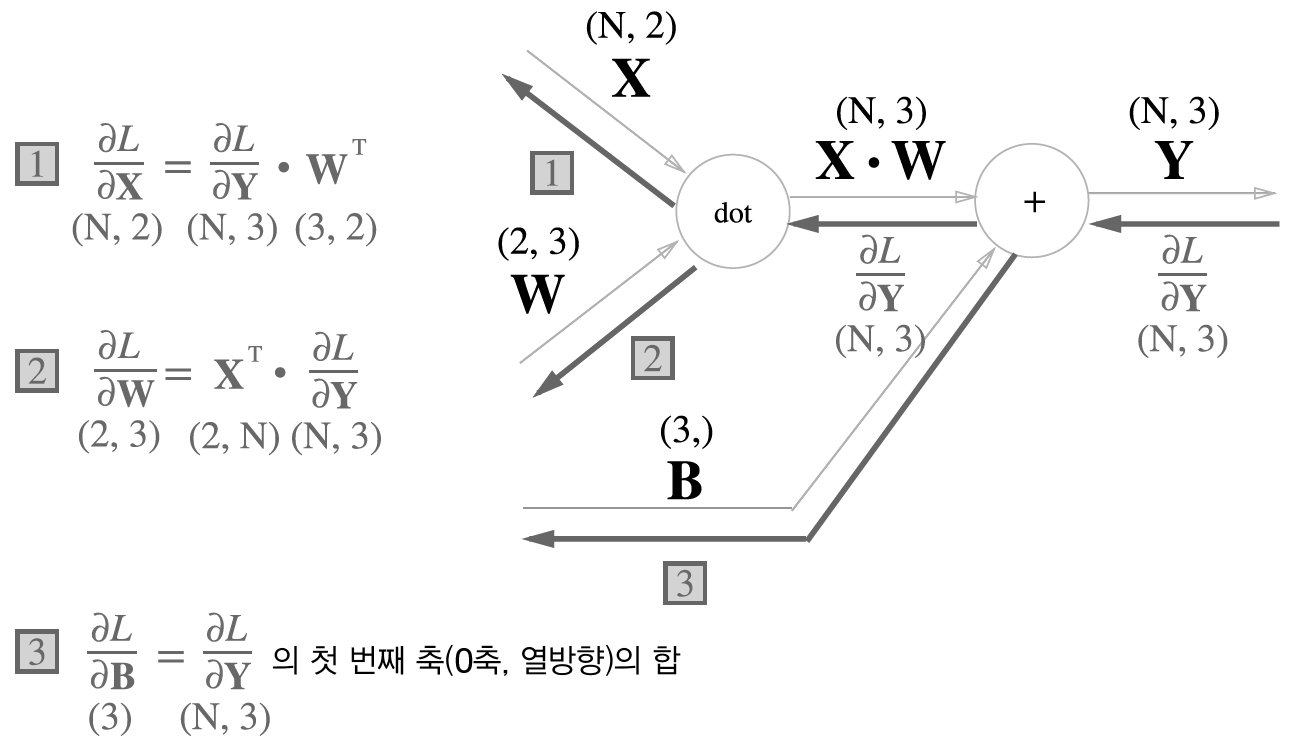
그런데 여기서 문제가 생긴다. 이제 행렬곱 (dot) 연산에 대한 역전파도 진행을 해야하는데, 그러면 1번에서는 Chain Rule에 의해
∂X∂L=∂Y∂L⋅∂X∂Y 이므로
우리가 구해야 하는 수식은 바로 ∂X∂Y이다.
마찬가지로 2번은 ∂W∂L=∂Y∂L⋅∂W∂Y 이므로 ∂W∂Y를 구해야 한다!
행렬을 벡터로 편미분, 행렬을 행렬로 편미분...? 이게 무슨 말도 안되는 식인가 싶지만 수학적으로 아무런 문제가 없는 식이다.
저 식들은 결과적으로 이런 식으로 변환이 가능하다.
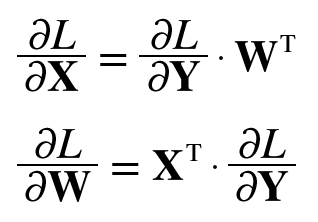
책에서는 물론 너무 복잡한 내용이라 그런지 증명을 생략해버렸지만, 그냥 넘어가기에는 찝찝함이 너무 크다. 이 두 수식을 한 번 증명해보자!
Proof
Chain Rule (General Version)
연쇄 법칙이야 고등학교 수학만 배웠다면 모두가 알 내용이다. 하지만 이 연쇄 법칙을 다변수 미적분에 대해 확장시킨다면 어떻게 될까? Stewart의 Calculus에 나오는 Chain Rule의 일반화된 버전은 다음과 같다.

n개의 변수 xi를 가지고 있는 u라는 미분 가능한 함수에 대해, n개의 변수 각각이 m개의 변수 tj에 대한 함수인 상황이다. 그렇다면, u를 tj라는 변수로 편미분하면 어떻게 될까? u의 각각의 변수 xi에 대해서 각각을 편미분한 값인 ∂xi∂u에 ∂tj∂xi를 곱하면 되는 것이다.
즉, ∂tj∂u=∑i=1n∂xi∂u∂tj∂xi인 것이다. 이 사실을 행렬에 확장시켜본다면, 행렬에 대한 편미분에서의 Chain Rule도 결국 행렬의 각각의 원소에 대해서 편미분을 해서 다 더해주는 형태라고 볼 수 있을 것이다. 이 사실을 염두에 두고 두 식을 증명해보자.
Assumption
일단 먼저 증명을 진행하기 전, 몇 가지 가정을 하자.
위 예시에서는 X가 1차원 벡터였지만, 다차원 신경망에 대해서 일반화 시키기 위해 행렬 X,W,Y의 차원을 다음과 같이 가정한다.
X:N×D,W:D×M,Y:N×M
또한, 여기서 B항은 편미분에 영향을 주지 않는 상수항이기 때문에 Y=XW라고 하더라도 무관하다.
이렇게 두 가지 가정을 해두고 증명을 해보자.
Proof 1)
먼저, ∂X∂L=∂Y∂L⋅∂X∂Y에 대해 살펴보자.
∂X∂L는 결국 X와 차원이 동일하고, X의 각 원소로 L을 편미분할 것이기 때문에, (L과 X의 각 원소 xij는 스칼라 (함수)이다)
(∂X∂L)ij=∂xij∂L이다.
또한, L=f(Y), 즉 L은 행렬 Y에 대한 함수라고 볼 수 있다. 따라서, Generalized Chain Rule에 의해,
∂xij∂L=∑α=1N∑β=1M∂yαβ∂L∂xij∂yαβ 임을 알 수 있다.
이때, Y=XW 이기 때문에, 행렬 곱의 정의에 의해
yαβ=∑k=1Dxαkwkβ라는 사실을 알 수 있다.
그렇다면, ∂xij∂yαβ라는 항을 잘 살펴보자.
yαβ=∑k=1Dxαkwkβ=xα1w1β+...+xαDwDβ라는 항을 xij에 대해서 편미분한다면, 시그마 식에서 정확하게 α=i,k=j인 항만 편미분되어서 값이 남을 것이고 나머지 항들은 전부 0이 될 것이다. 그 남는 값은 xij=xαk 뒤에 남는 wkβ일 것이고 k=j이므로, wkβ=wjβ이다.
따라서,
∂xij∂yαβ={wjβ0i=αi=α 라는 사실을 알 수 있다!
이를 위의 double sigma 식에 대입하면 해당 식을 다음과 같이 변형 가능하다.
∂xij∂L=∑α=1N∑β=1M∂yαβ∂L∂xij∂yαβ=∑β=1M∂yiβ∂Lwjβ
(α=i 일때만 뒤의 항이 wjβ이기 때문에, 앞의 항에서 α를 i로 바꿔주고 뒤의 항을 wjβ로 바꾼 다음 β에 대해서만 sigma를 하면 된다.)
그런데, 우리는 (∂X∂L)ij=∂xij∂L임을 알고 있다.
따라서,
(∂X∂L)ij=∑β=1M∂yiβ∂Lwjβ 이다.
이때, (∂X∂L)ij=∂xij∂L와 유사하게 ∂yiβ∂L=(∂Y∂L)iβ이고,
wjβ는 W의 전치행렬 WT의 βj성분이기 때문에 wjβ=(WT)βj이다.
그러므로, (∂X∂L)ij=∑β=1M∂yiβ∂Lwjβ=∑β=1M(∂Y∂L)iβ(WT)βj이다.
그런데, (∂X∂L)ij=∑β=1M(∂Y∂L)iβ(WT)βj는 행렬곱의 정의식 꼴과 같다.
따라서, ∂X∂L=∂Y∂L⋅WT임이 증명되었다.
■
Proof 2)
2번의 증명도 1번의 증명과 동일한 방식으로 진행하면 된다. 그렇기 때문에 2번 증명에는 글 없이 수식으로만 증명을 서술하겠다.
∂W∂L=∂Y∂L⋅∂W∂Y
(∂W∂L)ij=∂wij∂L
L=f(Y)
∴∂wij∂L=∑α=1N∑β=1M∂yαβ∂L∂wij∂yαβ
Y=XW ∴yαβ=∑k=1Dxαkwkβ
∂wij∂yαβ={xαi0j=βj=β
∴∂wij∂L=∑α=1N∑β=1M∂yαβ∂L∂wij∂yαβ=∑α=1Nxαi∂yαj∂L
(∂W∂L)ij=∂wij∂L
∴(∂W∂L)ij=∑α=1Nxαi∂yαj∂L
∂yαj∂L=(∂Y∂L)αj
xαi=(XT)iα
∴(∂W∂L)ij=∑α=1Nxαi∂yαj∂L=(∂W∂L)ij=∑α=1N(XT)iα(∂Y∂L)αj
=>(∂W∂L)ij=∑α=1N(XT)iα(∂Y∂L)αj
∴∂W∂L=XT⋅∂Y∂L
■
Conclusion
이렇게 선형대수학과 미적분학의 도움으로 두 수식을 증명할 수 있었다.
이번에 이 책을 다시 읽고 이 증명을 정리하면서 참 많은 생각이 들었다.
1) 역시 딥러닝 제대로 이해하려면 수학적 base가 겁~나 중요하구나
2) 스칼라를 행렬로 미분하는데 행렬이 나온다 : 수학의 세계는 정말 알 수가 없구나...
(어디선가 미분도 결국 선형변환이라는 글을 본 적이 있긴 하다...)
3) Latex는 써도써도 적응이 안 되는구나...
이제 좀 열심히 살자... 화이팅... ^^
References
<밑바닥부터 시작하는 딥러닝>, 사이토 고키
<Calculus Early Transcendentals by James Stewart, 9th edition>
엄청 도움이 된 블로그 글 (https://calofmijuck.tistory.com/17)
Stanford CS231n 자료 (http://cs231n.stanford.edu/handouts/linear-backprop.pdf)