Before the beginning,,,
What is Recurrent Neural Networks (RNN)?
RNNs use the idea of processing sequential information. The term “recurrent” applies as they perform the same task over each instance of the sequence such that the output is dependent on the previous computations and results. Generally, a fixed-size vector is produced to represent a sequence by feeding tokens one by one to a recurrent unit. In a way, RNNs have “memory” over previous computations and use this information in current processing.
- Structure of Simple RNN
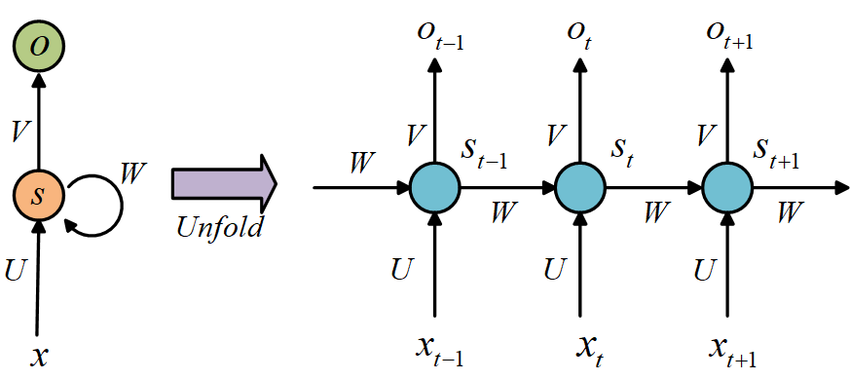
: the input to the network at time step
: the hidden state at time step
Caculation of is based as per the equation:
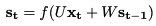
-> is caculated based on the current input and the previous time step's hidden state
-> is considered as the network’s memory element that accumulates information from other time steps
The function : a non-linear transformation such as
: weights that are shared across time
- Properties of RNN
- Pros
- Given that an RNN performs sequential processing by modeling units in sequence, it has the ability to capture the inherent sequential nature present in language, where units are characters, words or even sentences.
- RNNs have flexible computational steps that provide better modeling capability and create the possibility to capture unbounded context.
- Cons
- Simple RNN networks suffer from the infamous vanishing gradient problem, which makes it really hard to learn and tune the parameters of the earlier layers in the network.
- Pros
Conventional BPTT (e.g., Williams and Zipser 1992)
-
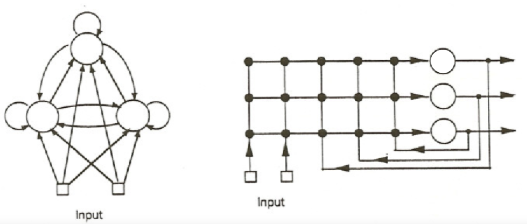
Network Architecture
-
Let the network have units, with external input lines.
-
Let denote the -tuple of outputs of the units in the network at time .
-
Let denote the -tuple of external input signals to the network at time t.
-
We also define to be the -tuple obtained by concatenating and in some convenient fashion.
-
Let denote the set of indices such that the component of , is the output of a unit in the network.
-
Let denote the set of indices for which is an external input.
-
Furthermore, we assume that the indices on and are chosen to correspond to those of x, so that
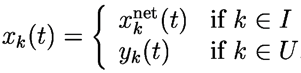
-
Let denote the weight matrix for the network, with a unique weight between every pair of units and also from each input line to each unit.
-
The element represents the weight on the connection to the unit from either the unit, if , or the input line, if .
-
Furthermore, note that to accommodate a bias for each unit we simply include among the input lines one input whose value is always 1; the corresponding column of the weight matrix contains as its element the bias for unit . In general, our naming convention dictates that we regard the weight as having as its “presynaptic” signal and as its “postsynaptic” signal.

-
For each k, the intermediate variable represents the net input to the unit at time . Its value at time is computed in terms of both the state of and input to the network at time by
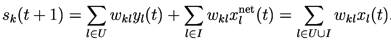
The longer one clarifies how the unit outputs and the external inputs are both used in the computation, while the more compact expression illustrates why we introduced and the corresponding indexing convention above.
-
The output of such a unit at time is then expressed in terms of the net input by
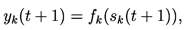
where is the unit's squashing function.
-
In those cases where a specific assumption (differentiable) about these squashing functions is required, it will be assumed that all units use the logistic function.
-
-
Network Performance Measure
- Assume that the task to be performed by the network is a sequential supervised learning task, meaning that certain of the units’ output values are to match specified target values (which we also call teacher signals) at specified times.
- Let denote the set of indices for which there exists a specified target value that the output of the unit should match at time . Then define a time-varying -tuple by
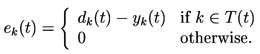 -> Note that this formulation allows for the possibility that target values are specified for different units at different times.
-> Note that this formulation allows for the possibility that target values are specified for different units at different times.
-
Denote the negative of the overall network error at time t.
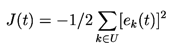
-
A natural objective of learning might be to maximize the negative of the total error oversome appropriate time period .
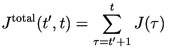
-
One natural wat to make the weight changes is along a constant positive multiple of the performance measure gradient, so that
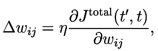
for each and , where is a positive learning rate parameter.
LSTM
1. Introduction
- With conventional "Back-Propagation Through Time" (BPTT) or "Real-Time Recurrent Learning" (RTRL), error signals "flowing backwards in time" tend to either (1) blow up or (2) vanish
(BPTT 참고: https://velog.io/@jody1188/BPTT)
-> LSTM is designed to overcome these error back-flow problems. It can learn to bridge time intervals in excess of 1000 steps even in case of noisy, incompressible input sequences, without loss of short time lag capabilities.
3. Constant Error Backprop
3.1 Exponentially Decaying Error
3.2 Constant Error Flow: NAIVE APPROACH
- A single unit
- To avoid vanishing error signals, at time , 's local error back flow is
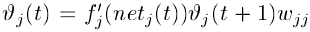
- To enfore constant error flow through , we require
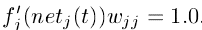
- To avoid vanishing error signals, at time , 's local error back flow is
- The constant error carrousel
- Interating the differential equation above, we obtain
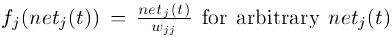
- This means: has to be linear, and unit 's activation has to remain constant:
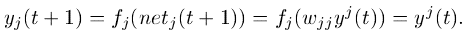
- In the experiments, this will be ensured by using the identity function :, and by setting . We refer to this as the constant error carrousel (CEC).
- Interating the differential equation above, we obtain
4. LONG SHORT-TERM MEMORY
- Memory cells and gate units
- To construct an architecture that allows for constant error flow through special, self-connected units without the disadvantages of the naive approach, we extend the constant error carrousel CEC embodied by the self-connected, linear unit from Section 3.2 by introducin additional features.
- A multiplicative is introduced to protect the momory contents stored in from pertubation by irrelevant inputs. Likewise, a multiplicative is introduced which protects other units from perturbation by currently irrelevant memory contents stored in .

- : $t
<References>
- https://arxiv.org/pdf/1708.02709.pdf
- https://gwern.net/doc/ai/nn/rnn/1995-williams.pdf
- https://www.semanticscholar.org/paper/13-Gradient-Based-Learning-Algorithms-for-Recurrent-Williams-Zipser/4983823eb66ed5d8557f20dd5c8a09ed66f05c25
- https://www.bioinf.jku.at/publications/older/2604.pdf
- https://medium.com/@mfouzan144/understanding-lstm-gru-and-rnn-architectures-e0b3a0c1d741
