
역시나 Contrastive learning에 관한 논문이긴한데, 이전에 살펴본 논문과는 다른 loss 식을 적용하여 비슷한 문장은 큰 오류, 다른 문장에 작은 오류를 줬다. 결론적으로 비슷한 단어가 나오지 않도록 학습하는 것이 목적인데, 구체적으로 살펴보자!
A Contrastive Framework for Neutral Text Generation
Abstract
maximization-based decoding methods (beam search) of neural LM often lead to degenerate solutions
- unnatral
- contain repetitions
- stochasticity 나 objectives 수정을 통한 접근은 lack coherence
문제의 원인은 anistropic distribution of token representation 이며, contrastive solution:
1. SimCTG, a constrastive training objective to calibrate the model's representation space
2. decoding method - contrastive search - to encourage diversity, maintaining coherence
1. Introduction
conventional approach of training a LM (MLE) and decoding the most likely sequence is often not sufficient (degeneration; the generated texts tend to be dull and contain undesirable repetitions)
이러한 논문을 해결하기 위해 여러 방법이 있었지만 만족스럽지 못했고, 이 논문은 degeneration 문제가 anisotropic distribution of token representation 에서 기인한다고 보았다. (전체 공간의 narrow subset 에만 분포하는 것!)
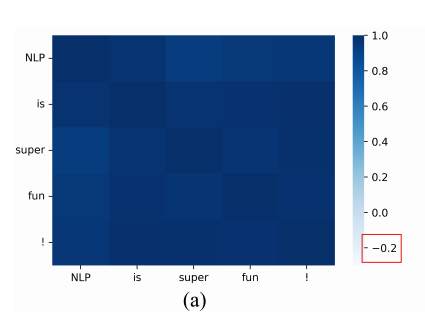
GPT-2 의 cosine similarity matrix 인데, 문장 안 단어들의 모든 값이 0.95를 넘는다. anisotropic 한 문제이며, 이것 때문에 generate repetitive token 문제 발생.
이상적인 상황에서는 token representaion follow isotropic distribution (sparse, distinct tokens should be discriminative) 아래는 SimCTG의 코사인 유사도 행렬이다.
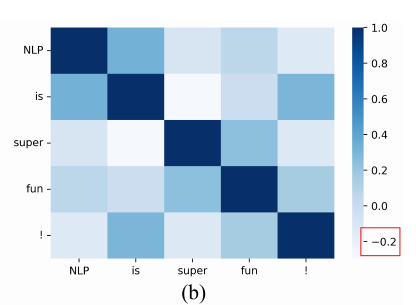
SimCTG(a simple contrastive framework for neutral text generation)
- Learning: 모델이 discriminative and isotropic token representations 을 학습할 수 있도록.
- Decoding: contrastive Search
Contrastive Search
1. most probable candidates (semantic coherence 를 만족)
2. 동시에 degeneration 문제를 피하기 위해 생성된 텍스트 사이 sparseness of the token smimilarity matrix 는 유지
결론적으로 proposed contrastive search significantly outperforms previous state-of-the-art decoding methods 임을 보였다고 주장하는 논문이다!
2. Background
2.1 Language Modelling(MLE)
LM의 목표는 variable-length text sequence x 에서 probability distribution 을 학습하는 것이다.
Maximum likelihood estimation (MLE) objective is used to train the language model.
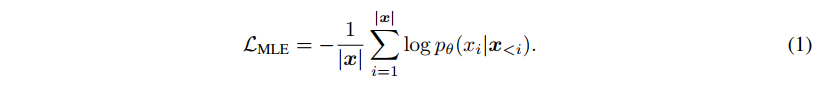
- anisotropic distribution of model representation 문제
2.2 Open-ended Text Generation(greedy, beam, necleus)
Oepn-ended text generation tasks (generality)
- stoty generation
- contextual text completion
- poetry generation
- dialogue system
주로 human-written prefix 가 주어지면 task 는 decode a continuation from a language model 하는 것이다.
1) Deterministic Methods
가장 많이 쓰이는 2가지는 greedy 와 beam search 이다. (모델의 확률분포 p에서 가장 높은 text continuation 을 선택) 역시나 dullness, degeneration 문제가 있다.
2) Stochastic Methos
분포의 꼬리로부터 샘플링 되는 것을 막기위해, 1. top-k sampling 제안 (vocabulary subset 에서
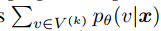
아래를 maximize 하도록 샘플링. 이며 는 prefix context 이다. (정해진 수의 단어 사전에서만 샘플링 되도록)
- Nucleus sampling: 가장 작은 단어 부분집합 U에서 샘플링.
이렇게 샘플링하여 결정하면 degeneration 문제는 피할 수 있지만 semantic meaning 에서의 문제가 생긴다. (prefix 와 어긋나거나, sampled text 가 diverge)
3. Methodlogy
이제 1. 언어모델에서 contrastive learning 을 사용해 representation space 를 만드는 방법과 2. decoding algorithm 으로 contrastive search 를 알아보자.
3.1 Contrastive Training
목표는 언어모델이 discriminative, isotropic token representation 을 학습하도록 하는 것이다.
Objective (contrastive)
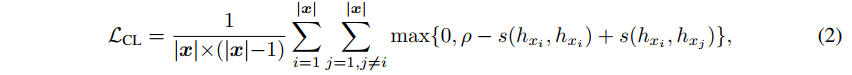
- variable-length sequence
- : pre-defined margin
- : representation of token
- : token representation 사이 유사도 함수
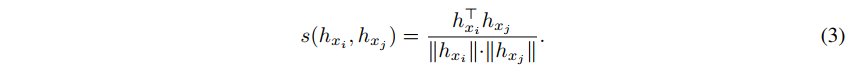
위 식을 잘 들여다보면 max(0, p - 같은 token + 다른 token) 구조로 되어있고, 목표는 이 loss 를 줄이는 것이다. 따라서 loss 를 줄이는 방향으로 학습하게 된다면 '같은 token' 의 유사도는 크고, '다른 token' 의 유사도는 작으면 될 것이다. (model learns to pull away the distances between representation of distinct tokens => discriminative, isotropic 달성가능)
종합하여 SimCTG의 objective 는 다음과 같이 정의된다.
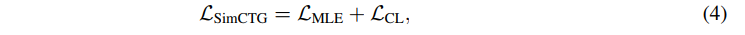
3.2 Contrastive Search
key ideas for decoding step
1) generated ouput 은 모델에 의해 가장 가능성이 높은 후보를 선택
2) generated output은 이전 문맥을 고려하는 동시에(semantic coherence) discriminative 해야함(avoiding degeneration)
-
X<t 의 previous context
-
time step t
-
selection of tue output
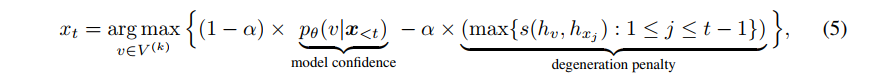
-
는 모델의 확률분포를 다르는 top-k prediction set 이다.
-
model confidence 부분: 모델에 의해 후보 v가 예측될 확률
-
degeneration penalty: context 를 고려하면서 후보 v의 discriminative 측정, v와 t 이전 모든 단어들의 유사도 조합 중 max 값
-
따라서 degeneration penalty 의 값이 크다는 것은 context 와 더 비슷하다는 것이고, 다르게 말하면 degeneration 가능성도 있다는 것.
-
따라서 이를 차로 두고, 알파를 조정하며 두 부분 사이 중요도 조정. 쉽게 말해 second term 에 가중치를 더 많이주면 v의 후보 중에서 유사도가 컸던 v에게 penalty를 많이 주는 것(degeneration을 막을 수 있을 것이다)이고, first term 에 가중치를 더 많이주면 이전 context 를 고려하여 가장 등장할 것 같은 v를 선택하는 것이다(semantic 에서 강점이 있을 수 있을 것이다)
4. Document Generation
평가에 관련한 부분이다. open-ended document generation 의 tasks 에 적용.
Model and Baslines: representative GPT-2 model 에 evaluated benchmark 파인튜닝. (objective SimCTG)
비교는 1) GPT-2를 MLE objective 으로 파인 튜닝한 모델과 2) GPT-2 를 unlikelihood objective 으로 파인튜닝한 모델과 비교.
Evaluation Benchmark: 위키피디아의 글을 모아둔 Wikitext-103 dataset 사용
Training: SimCTG, MLE 는 Wikitext-103 으로 파인튜닝, unlikelihood baseline 의 경우 token-level unlikelihood objective 으로 학습 후 sequence-level 로 전환하여 훈련. 배치사이즈 128, 문장 최대길이 256, optimizer Adam, learning rate 2e-5
Decoding: test set 의 prefix 가 주어졌을 때 나머지를 얼마나 잘 예측하는지를 기반으로 모델을 평가했으며, prefix 길이는 32, continuation 길이는 128로 설정. decoding method 에 따라
- greedy, beam search 의 경우 beam size 10
- stochastic method 의 경우 nucleus sampling with p = 0.95
- contrastive search 의 경우 k = 8, 알파 = 0.6 으로 설정
4.1 Evaluation Metrics
언어 모델의 내부적 퀄리티와 만들어진 텍스트의 퀄리티 두 가지 metric
1) Language Modelling Quality
예측 정확도를 보면
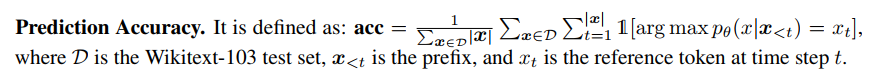
테스트 셋에 있는 텍스트에 대해 prefix 가 주어졌을 때 x의 등장확률을 reference token 과 비교 (잘 맞췄는지)
Prediction Repetition의 경우 next-token 예측이 prefix 에 존재하는지를 따지는 것이다. (반복하여 예측한 단어는 없는지)
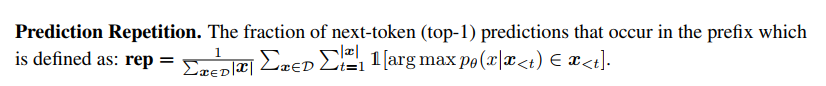
2) Generation Quality
Generation Repetition: 만들어진 텍스트에서 문장수준으로 반복된 비율을 n-gram 으로 체크하는 것이다. 아래를 보면 알 수 있듯이 unique n-gram 비율이 많을수록 Repetition n-gram의 값은 작을 것!
Diversity: n-gram 의 레벨을 2부터 4까지 변경시켜가며 평균으로 평가하는 것이다. 식을 보면 알겠지만 rep-n 이 분자에 들어가기 때문에 반복이 많을수록 Diversity 값은 높아진다고 할 수 있다.
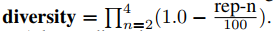
MAUVE: 값이 높을수록 만들어진 텍스트와 인간이 적은 실제 텍스트 간 token closeness 가 높다.
Semantic Coherence: prefix x 와 generated text x'의 유사도로 측정한다.
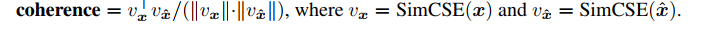
Perplexity of Generated Text: prefix x 가 주어졌을 때 generated text x' 의 perplextity
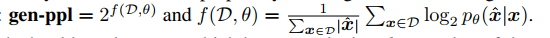
값이 높다는 것은 prefix 가 주어졌을 때 만들어진 텍스트가 unlikely 하다는 것.
4.2 Results
metric 으로 평가한 결과는 다음과 같다.
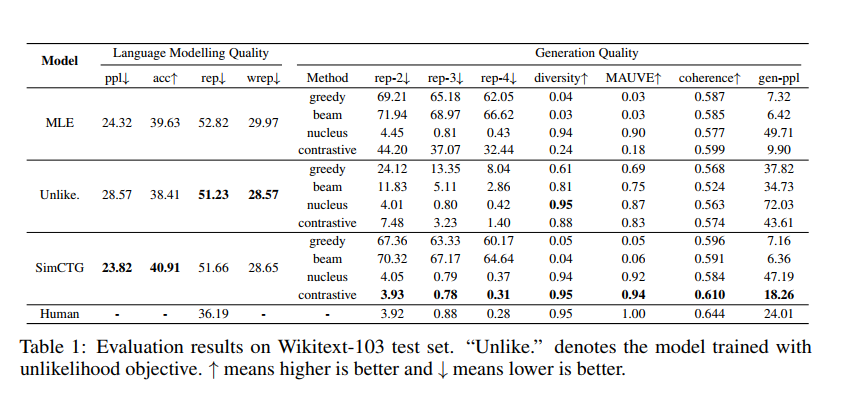
1) SimCTG 의 경우 perplexity, accuracy 에서 좋았다. (discriminative, less confusing)
2) 놀랍게도 Generation 성능과 관련해선 SimCTG + contrastive method 가 모든 성능에서 우수했다. contrastive decoding 만 하면 다른 method 보다 성능이 좋았지만 그래도 training 에서도 쓰는 게 좋다는 결론!
4.3 Human Evaluation (생략)
5. Open-domain Dialogue Generation
tasks of open-domain dialogue generation 에 적용한 결과를 보자!
Benchmark and Baselines: Chinesse 의 경우 LCCC dataset, English 의 경우, DailyDialog dataset 이용.
Evaluation: human evaluation 으로 평가. 200 dialogue 를 랜덤으로 선택하고 generated responses 에 대해 5명의 annotators 가 평가. (coherence, fluency, informativeness)
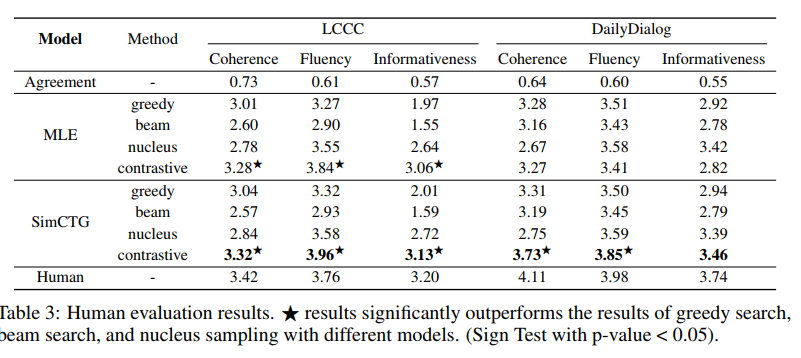
여기서도 역시나 SimCTG + contrastive search 가 다른 방법보다 outperform, 이로써 다른 언어나 tasks 에 대해서도 적용할 수 있음이 증명되었다. (심지어 MLE training 을 택했을 때에도 contrastive decoding 만 붙이면 다른 방법보다 뛰어난 성능을 보였다.)
6. Further Analysis
1. Token Representation Self-similarity
SimCTG로 학습한 token representation 분석을 위해, text sequence x 내에서 토큰 표현의 self-similarity 평균을 정의.
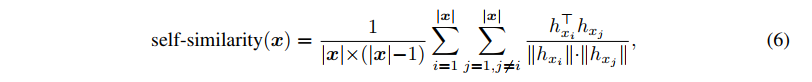
따라서 이 값이 낮다는 것은 시퀀스 x내에서 다른 토큰들이 서로 덜 유사함을 뜻한다. (more discriminative)
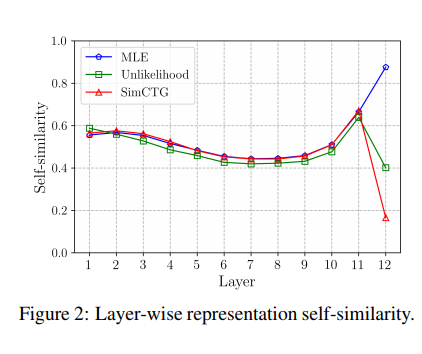
위의 그림을 보면 layer 중간에서는 비교적 모델들이 상대적으로 비슷한 self-similarity 를 유지하다가 output layer(12) 에서 SimCTG가 극단적으로 낮은 유사도를 띄는 것을 볼 수 있다.
2. The Effect of Contrastive Loss Margin
Equation 2번에 도입되었던 contrastive loss margin (-1에서 1 사이의 값) 의 영향력에 대한 분석이다.
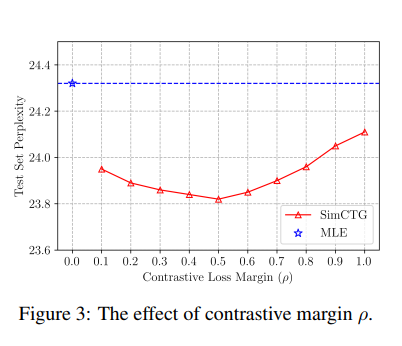
이 값이 0일 경우 결국 MLE 와 다를 것이 없게되고, 이 값이 너무 작거나 (0.1) 너무 크게되면 (1.0) less or too isotropic 해질 수 있게 된다. 가장 적절한 값은 0.5
3. Contrastive Search versus Nucleus Sampling
둘의 구체적인 비교를 이해 Necleus 에서는 p값을, Contrastive에서는 알파 값을 변경시키며 Perplextity 와 Diversity 를 비교했다.
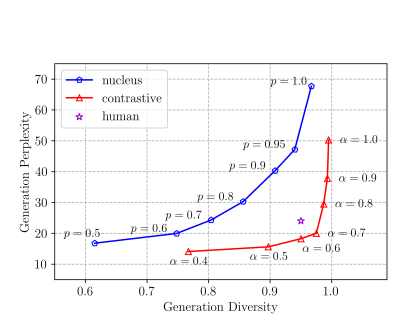
이렇게 비교를 해봐도 contrastive search 에서 알파가 0.5-0.8 사이일 때 특히나 두 값이 human performance 와 견줄만 했다.
4. Decoding Latency Comparison
practical usage: Latency 에 대한 비교로 SimCTG 내에서 서로 다른 decoding methods 를 사용했을 때 시간을 비교한 것이다. b, k 가 작을 때는 비슷했지만 이 값이 커질수록 contrastive 가 빨라지는 것을 확인할 수 있다.

5. Case Study

beam 의 경우 degeneration repetitions, nucleus 의 경우 incoherent semantics, contrastive 의 경우 reasonable repietition 을 확인할 수 있다.
6. Comparison of Token Similarity Matrix
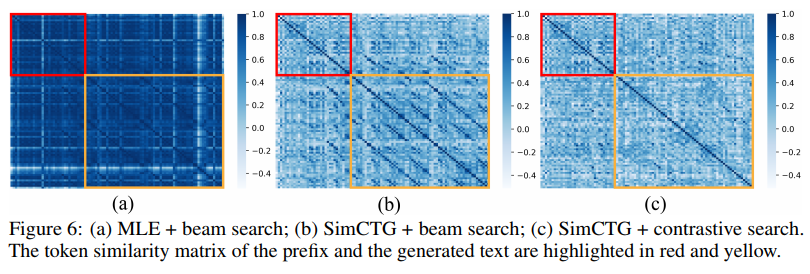
빨간색은 prefix, 노란색은 생성된 텍스트의 similarity matrix 를 보여준다. SimCTG+beam search 의 경우 prefix 가 sparse, isotropic 하지만 여전히 생성 텍스트에서 문제임을 확인할 수 있다. 그러나 SimCTG + contrastive search 에서는 전체 matrix 가 성공적!
7. Conclusion
- neural LM에서 degeneration 문제는 anisotropic token representation 문제에서 기인함을 밝혀냈고
- 새로운 방법인 SimCTG: isotropic and discriminative representation space 를 얻을 수 있는 언어 모델의 학습 방법과
- Contrastive search 라는 decoding method 를 제안했다
- 결과적으로 degeneration 문제를 해결하면서도 현재의 text generation 성능을 뛰어넘는 방법임을 입증!
