- 왜 읽게 되었는지?
- 논문의 어떤 부분이 중요한지?
- 논문 내용과 실험 결과
- 문제 해결을 원하는 부분과 Idea
- 구체적으로 어떤 method or model 을 사용할지
소셜 미디어 텍스트 (편향 포함) + 지도 학습의 경우 neural LM 편향이 발생.
소셜 미디어 텍스트를 학습하면서도 편향을 완화하도록 지식 그래프를 적용하면 되지 않을까? 가 main idea.
여기서 한 발 구체적으로 소셜 미디어 텍스트 data + 지식 그래프 활용 + Contrastive Learning 으로 편향성 발언을 줄이자가 목표이다. 일단 지금까지 읽은 내용들을 정리해보고, 어느 단계에서 각각 적용할 수 있을지, 어떤 영향을 가져올 수 있을지, variation 은 무엇이 있을지 생각해보자.
1) Mitigating Gender Bias in NLP: Literature Review
이 논문은 최근 NLP 논문들 중 gender bias 에 초점을 맞춰 debiasing 방법에 대해 괜찮은 방법들을 정리하고 있는 글이다.
방법은 크게 corpora, representation 에서 완화를 시도하는 방법과 prediction algorithms 에서 완화하는 방법 2가지가 있었다.
- Corpora 를 통한 방법:
original with name-anonymization + augmented data set(name-anonymization에 gendr-swapped)
Gender tagging: 애매한 상황에서 남성 화자로 확정하지 않도록
Bias Fine-Tuning: pretraining 자체는 편향이 없는 텍스트에서 진행한 후 편향이 있는 태스크에 대해서 파인튜닝
- Embedding 자체를 건드리는 방법:
원래 임베딩에서 코사인 유사도를 계산하면 he, she 가 굉장히 가까운 벡터로 표현될 것이고 이를 제거하는 것이다. 그럼 Genderless framework 를 만들 수 있지 않을까?
또다른 방법은 특정 공간에 gender info 를 모아두고 뉴트럴한 정보들은 다른 공간으로 둘 사이를 분리시키는 것이다. (이거 좋은 거 같은데 non-Euclidean 에서 cosine 유사도가 적용되지 않아서 잘 작동하지 않는다는 말이 무엇일까..?)
- 알고리즘 예측을 통한 방법:
Amplication 을 줄이는 방법이다, constrained conditional model 을 통해. (예측에 있어서 남성과 여성의 비율에 제한을 두는 방법) 어쨌든 알고리즘 예측을 조정한다는 것은 모델의 objective 또는 constraint 을 조정한다는 뜻같다.
2) StereoKG: Data-Driven Knowledge Graph Construction for Cultural Knowledge and Stereotypes
지식 그래프를 자동으로 생성하는 방법에 대해 소개한 논문이었다. 내용을 더 간단하게 정리하면서 지식 그래프를 어느 단계에서 활용하면 좋을지 생각해보자.
verbalized KG 를 학습한 masked LM 이 지식이 중요한 태스크에서 높은 성능을 기록했다는 것이 포인트였다.
왜? Stereotype 을 포함하지 않을 경우 분류에서 문제가 생기기 때문이다. bias reduction 을 위한 워드 임베딩, 분류 작업이 필요했고 과거엔 이걸 lexicon 단위로 작업했으나 여기선 KG로 풀겠다는 것. 지식 그래프를 활용하여 bias reduction 을 해내자는 의도이다.
결합 방법 2가지. 1. Fusion based approches (LM 표현 + KG 표현) 2. LM base (pre-trained LM => KG integration via intermediate pre-training)
KG 자체의 (automated manner) 형성 방법은 다음과 같다. (=> 그냥 알아만 두자.)
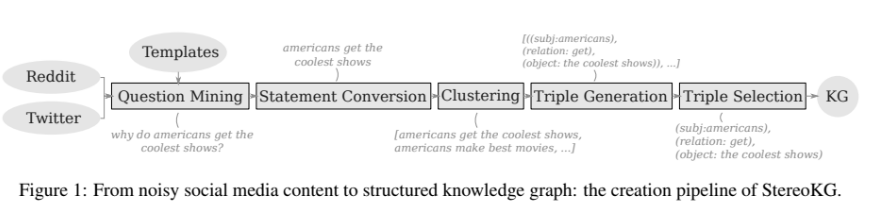
참고) 형성 방법에서 특징적인 것은 굳이 triple 로 바꿨다가 다시 그에 따라 문장을 생성한다는 점이다. 왜? 아무래도 지식'그래프'다 보니 정리된 문장만이 필요했을 것이다. (부사어구 등을 제외한) 다시 문장을 변환하고 문법성이 높은 1등이 cluster 의 대표로 선택되니 의미상에는 문제가 없을 것이다.
결합 방법은 BASE모델/Domain Trained모델에, + intermediate MLM training UK / SK(UK와의 비교를 통해 지식 그래프의 효과를 볼 수 있다) 를 결합하는 것이다. 그리고 OLID, WSF 데이터로 테스트.
결론적으로 SK를 사용하여 성능이 향상된 경우는 Domain에서 train 하고 Domain 에서 test 했을 경우였다. 이 경우에만 지식 그래프에서 유의미한 성능 향상 발견.
👍지식 그래프를 생성하는 방법이나 결합하는 아이디어를 이 논문을 활용하면 이해하고 활용할 수 있을 것 같다. 기본적으로 소셜 미디어 텍스트를 데이터로 하는 학습이니, 주의깊게 봐두자.
3) A Contrastive Framework for Neural Text Generation
Contrastive learning 이나 Generation 과 관련한 이론 사항을 정리해보고 둘 중에 어떤 것을 사용할지, 왜 사용해야 하는지, 어디에 사용할지 생각해보자.
이 논문은 결과적으로 비슷한 단어가 등장하지 않으면서도 Semantic 하게 Coherence 를 유지하는 문장을 만들어내는 Contrastive Learning 을 소개하고 있다.
크게는 1. a contrastive training objective (학습 시 적용하는 방법) 과 2. Decoding method (generation 서치를 contrastive 하게하는 방법) 이 있다. 단계가 다르다는 것에 주의.
기존의 모델들은 MLE + Deterministic or Stochastic Method 를 붙인 형태였는데,
- Training objective 는 같은 토큰은 가깝게, 다른 토큰은 멀게 학습한 후 (SimCTG의 objective 는 MLE + CL 로 학습)
- Contrastive Search 시에 기존 방법처럼 단순히 가장 등장할 확률이 높은 v를 선택하는 것이 아니라 이전 prefix 를 고려한 계산을 하여 (이전에 등장했으면 페널티를 주는 방식으로) 선택.
결과적으로 1+2 를 하든, 1만 적용하든, 2만 적용하든 다른 방법들보다 우수한 성능이 측정되었다.
Potential Idea 정리
< IDEA1 >
- 소셜 미디어 텍스트 pretraining 사용
- Stereotype 지식 그래프 결합: intermediate training
- stereotype 지식 그래프를 학습할 때 Contrastive Learning Objective 적용 (편향은 편향끼리 모으고, 그렇지 않은 Neutral 은 다른 공간으로 분리)
- 그 다음 임베딩 자체를 건드리거나 아니면 바로 Decoding 하는 단계로 진입
- 임베딩 자체를 건드리는 방법으로는 편향이 담긴 공간과 그렇지 않은 공간으로 분리되었을 때 편향이 담긴 공간의 표현들은 아예 제거..?
- 또는 제거하지 않고도 이미 분리된 공간에 존재할테니 이를 Contrastive Decoding => 아래의 degeneration penalty 식을 "Bias penalty" 처럼 바꿔 편향 공간을 나타내는 식으로 바꾸거나 or degeneration penalty 식은 유지하면서 Bias penalty 식을 추가.
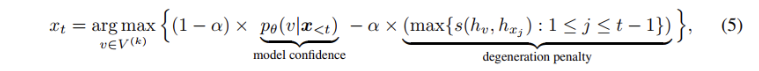
< IDEA 2 >
- 소셜 미디어 텍스트 representation: 1
- Stereotpye 지식 그래프 학습한 verbalized triple representation: 2
- 표현 1을 가지고 Decoding => degeneration penalty 부분을 max(s(h_1, h_2)) 로 바꿈 => 의도? 등장하려고 하는 후보 단어가 지식 그래프의 편향 단어와 유사도가 높으면 penalty.

좋은 정보 얻어갑니다