Attention 의 implementation 을 해보기 위해, pytorch 에 올라와있는 tutorial 페이지를 이용해보자!
- 데이터 load, 전처리
- 패딩
- 배치 단위로 준비
가 완료되었다고 가정하고, 모델을 세우는 것부터 시작해보자!
- Seq2Seq model (variable lenght input, return variable lenght output)
Encoder
인코더의 경우 RNN 구조가 기본적으로 사용되며, 각 time step 에 있어서 input, output, hidden vector 값을 가진다. 이때 전달되어 다음 계산에 사용되는 것은 hidden state vector 라 가정하자.
이때 구현해볼 것은 encoder 의 RNN 으로 multi-layered Gated Recurrent Unit, GRU 를 포함한 구조이다. bidirectional variant GRU 를 사용한다는 것은 두가지 독립적인 RNN을 사용한다는 말과 같다. 하나는 normal sequence order 로 인풋을 받으며, 다른 하나는 완전히 뒤집힌 reverse order 로 input sequence 를 받는 것이다. 그리고 나서 각 time step 에 output 을 결합하면, bidirectoinal GRU가 완성된다. (이 GRU는 아마 과거와 미래 context 를 모두 잘 capture 할 것이다!)
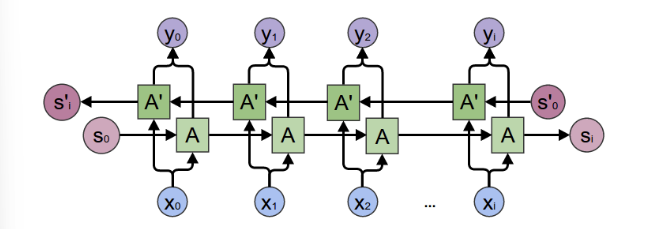
구현 사항을 정리하자.
- 가지고 있는 word indexes 를 embedding 으로 전한
- RNN 계산을 위해 패딩된 batch of sequence 로 전환
- GRU forward computation
- Unpack padding
- SUm bidirectional GRU output
- Return final hiddden state
input
- input_seq: 인풋 문장들을 뜻한다. (max_length, batch_size)
- input_length: 각 배치에 담긴 문장 수를 의미한다 (batch_size)
- hidden: hidden state 를 의미한다. (n_layers x num_directions, batch_size, hidden_size)
Outputs
- outputs: GRU의 마지막 hidden layer 의 featrues 을 의미한다. (bidirectional outputs 의 sum) (max_length, batch_size, hidden_size)
- hidden: GRU로부터 업데이트된 hidden state 를 의미한다 (n_layers x num_directions, batch_size, hidden_size)
본격적으로 EncoderRNN 을 정의하면 다음과 같다.
EncoderRNN Implementation
class EncoderRNN(nn.Module):
def __init__(self, hidden_size, embedding, n_layers=1, dropout=0):
super(EncoderRNN, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embedding = embedding
# Initialize GRU; the input_size and hidden_size parameters are both set to 'hidden_size'
# because our input size is a word embedding with number of features == hidden_size
self.gru = nn.GRU(hidden_size, hidden_size, n_layers,
dropout=(0 if n_layers == 1 else dropout), bidirectional=True)
def forward(self, input_seq, input_lengths, hidden=None):
# Convert word indexes to embeddings
embedded = self.embedding(input_seq)
# Pack padded batch of sequences for RNN module
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
# Forward pass through GRU
outputs, hidden = self.gru(packed, hidden)
# Unpack padding
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)
# Sum bidirectional GRU outputs
outputs = outputs[:, :, :self.hidden_size] + outputs[:, : ,self.hidden_size:]
# Return output and final hidden state
return outputs, hidden- n_layers, hidden_size 는 GRU 를 init 정의하기기 위해 가져온다. embedding 은 실제 forward 연산을 하기 위해 가져온다.
- GRU 는 input 으로 이미 한 번 인덱스 -> 임베딩으로 변환된 input 을 받아야하기에 input과 hidden_size 가 모두 hidden_size 로 초기화된다. 레이어 수, dropout, bidirectional 을 지정해주자
- forward 연산에서 embedding 은 인덱스들을 embedding 으로 바꿔주는 역할을 할 것이다. 따라서 embedded는 (max_length, batch_size, hidden_size)
nn.utils.rnn.pack_padded_sequence는 임베딩을 이어받고, 지정받은 input_length (여기선 배치 사이즈를 뜻한다) 를 입력받아 배치로 변환한다. packed는 (max_length, input_length. hidden_size)- gru 에는 packed 된 배치를 넣고, outputs, hidden 을 반환한다.
- outputs 를 받아 한 번 unpack 해준다
- outputs 내부적으로는 현재 bidirectional = True 이므로 두 값이 모두 들어있을 것이다. (hidden 을 기준으로 앞은 원래 order, 뒤는 reverse order) 따라서 둘을 time step 순대로 합한 outputs 을 다시 만든다.
Decoder
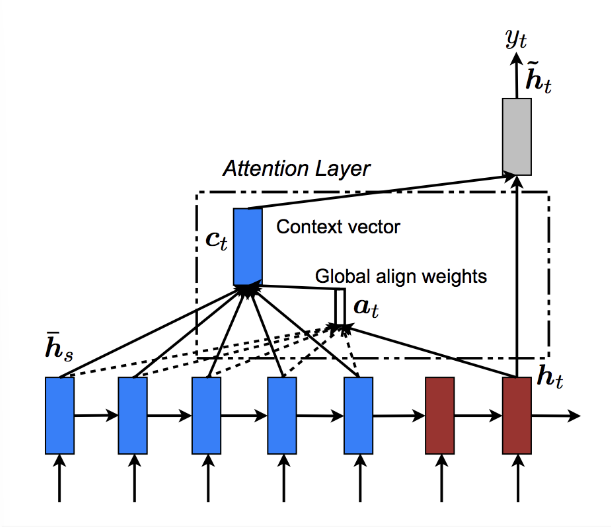
기존의 vanilla seq2seq decoder 에서 나타나던 문제점인 context vector 하나가 이전 문장의 정보들을 잘 잡아내지 못한다는 information loss 를 해결하기 위해서 attention mechanism 을 도입하기로 한다. (decoding 을 할 때 input sequence 중 어디서 집중할 지 결정하는 것이다.)
따라서, attention 은 decoder 의 현재 hidden state 와 encoder의 outputs 를 통해 계산된다.
Luong et al. 의 경우 "Global attention" 으로 "Local attention" 의 bahdanau 와 달리 모든 encoder 의 hidden states 와 현재 decoder hidden state 로 계산하는 것으로 한 단계 더 발전시키고, attention 계산에 있어서 몇가지 score function 을 제시한다.
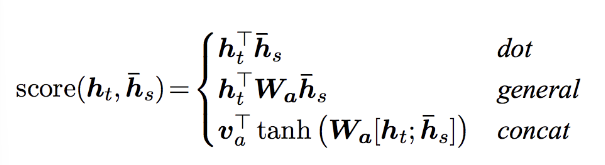
전체적인 Global mechanism 을 아래의 그림으로 묘사할 수 있다.
Luong attention layer Implementation
# Luong attention layer
class Attn(nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.FloatTensor(hidden_size))
def dot_score(self, hidden, encoder_output):
return torch.sum(hidden * encoder_output, dim=2)
def general_score(self, hidden, encoder_output):
energy = self.attn(encoder_output)
return torch.sum(hidden * energy, dim=2)
def concat_score(self, hidden, encoder_output):
energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1), encoder_output), 2)).tanh()
return torch.sum(self.v * energy, dim=2)
def forward(self, hidden, encoder_outputs):
# Calculate the attention weights (energies) based on the given method
if self.method == 'general':
attn_energies = self.general_score(hidden, encoder_outputs)
elif self.method == 'concat':
attn_energies = self.concat_score(hidden, encoder_outputs)
elif self.method == 'dot':
attn_energies = self.dot_score(hidden, encoder_outputs)
# Transpose max_length and batch_size dimensions
attn_energies = attn_energies.t()
# Return the softmax normalized probability scores (with added dimension)
return F.softmax(attn_energies, dim=1).unsqueeze(1)- Attention score 계산 방법은 dot, general, concat 중 선택한다
- dot_score 는 단순 곱 / general_score는 learnerble 가중치 W 를 추가하고 곱 / concat은 encoder_output 사이즈에 맞춰 concat 먼저 하고, Linear, tanh, v 를 추가한 것이다
- 어떤 방식으로든 attn_engergies 를 계산한 후 softmax 를 적용시켜준다.
LuongAtttnDecoderRNN
class LuongAttnDecoderRNN(nn.Module):
def __init__(self, attn_model, embedding, hidden_size, output_size, n_layers=1, dropout=0.1):
super(LuongAttnDecoderRNN, self).__init__()
# Keep for reference
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout = dropout
# Define layers
self.embedding = embedding
self.embedding_dropout = nn.Dropout(dropout)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout))
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.attn = Attn(attn_model, hidden_size)
def forward(self, input_step, last_hidden, encoder_outputs):
# Note: we run this one step (word) at a time
# Get embedding of current input word
embedded = self.embedding(input_step)
embedded = self.embedding_dropout(embedded)
# Forward through unidirectional GRU
rnn_output, hidden = self.gru(embedded, last_hidden)
# Calculate attention weights from the current GRU output
attn_weights = self.attn(rnn_output, encoder_outputs)
# Multiply attention weights to encoder outputs to get new "weighted sum" context vector
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
# Concatenate weighted context vector and GRU output using Luong eq. 5
rnn_output = rnn_output.squeeze(0)
context = context.squeeze(1)
concat_input = torch.cat((rnn_output, context), 1)
concat_output = torch.tanh(self.concat(concat_input))
# Predict next word using Luong eq. 6
output = self.out(concat_output)
output = F.softmax(output, dim=1)
# Return output and final hidden state
return output, hidden- 계산을 위해선 decoder 의 hidden state 와 encoder 의 hidden state 가 모두필요하다 했다, 따라서 gru 를 한 번 통과시켜 디코더에서도 rnn_output 을 만든다
- attn 연산을 통해 현재 시점에서 attn_weights 를 계산한다
- attn_weights 는 말그대로 '관련이 있을 확률'이므로 wegihted sum 이 필요하다, encoder_outputs 전체와 ws 해주자. context vector 완성.
- 현재시점 rnn_output 과 이와 관련있는 context 를 concat 해준다. (concat_input)
- 여기에 Linear 연산, tanh 연산을 해준다 (concat_output)
- concat_output 은 여전히 hidden_size 이므로 output size 로 변경해준다. 차원 변환과 softmax 를 적용하여 최종적인 예측을 한다. (output)
