Attention 다시보기
- Decoding 연산 시, 왜 Linear 연산을 두 번 할까?
-> linear 연산의 size 를 보면 각각 concat = nn.Linear(hidden_size * 2, hidden_size) / out = nn.Linear(hidden_size, output_size) 이다. 첫번째 레이어와 두번째 레이어 후 연산에는 각각 hyperbolic tangent 와 softmax 연산이 적용되어 있다.
-> 내가 생각해본 건 그럼 hidden_size X 2 에서 바로 output_size 로 출력해서 Linear 연산 한 번 하면 어떨까 하는 거였는데.. 단순히 concat 만 한 상태니까 단어와 단어의 의미가 중복이 될 거 같다. 그래서 Linear 연산을 해줘서 원래의 hidden_size 로 되돌리는 연산이 한 번은 필요한 거 같다. (첫번째 Linear 를 말하는 거다.)
Subword Model
- Tokenization
- Subword Tokenization Method
1. Tokenization
토큰화는 많은 전처리 방법 중 하나이다.
전처리 방법으로는
-
Tokenization
문자를 연속적인 단위인 토큰으로 분해하는 것이다. 그러나 한 단위를 무엇으로 할 지는 언어마다 다르다. 한국어는 형태소, 영어는 단어로 주로 분해한다. -
Lemmatization, Stemming
각각 표제어 또는 어간을 추출하는 것이다. 표제어란 단어의 뿌리를 의미하는 기본 사전형 단어를 의미한다. is, are, am 의 기본형 be 가 Lemma 가 된다. 어간은 활용형의 기초가 되는 부분이다. 뛰고, 뛰어, 뛰지.. 의 어간은 뛰(어간) 일 것이다. -
Stop words
분석에 큰 의미가 없는 단어를 제거하는 것이다. 어떤 tasks 를 수행하느냐에 따라 stop word 가 달라질 순 있겠지만, 한국어의 경우 조사, 영어의 경우 대명사 정도를 Stop words 로 지정할 수 있다. -
Vectorization
문서, 문장, 단어를 숫자화, 벡터화해주는 과정을 뜻한다. 이전까지는 주로 Word Embedding 을 사용했다. (Count-based representation, Sparse Representation)
*NLP에서 Tokenization 이 동작하는 전체 프로세스는 다음과 같다.
- Raw 한 입력 텍스트가 들어오면 토큰화해서 다시 입력 토큰을 만든다
- 입력 토큰에 대해 인덱스 변환하여 입력 토큰 인덱스를 구한다
- 미리 학습시킨 임베딩에 대하여 해당 인덱스를 찾는다
- 입력 임베딩 벡터를 만든다
여기까지가 Neural Network Model 로 해당 텍스트에 대해 입력을 만들어 넣기까지의 과정이다. 결국, 네트웍으로 들어가는 건 '임베딩 벡터의 모음'이다!
✅ Types of Tokenization
-
Word-Level Tokenization
(생략) -
Character-level Tokenization
유사한 문자는 유사한 임베딩을 공유하고, OOV 문제를 해결할 수 있으나.. 단어 수준 의미를 catpure 하기 어렵고, 글자마다 embedding size 를 가져가므로 시퀀스 계산이 많아진다. 이렇게 RNN 계산이 길어지면 vanishing gradient 현상이 두드러진다는 것이 정론이다.
따라서 Character 보다는 크고, Word 보다는 작은 단위인 Subword 가 등장하게 된다. (참고로 Mixed Word/Character-level 도 있다. 워드임베딩과 + character 에서 LSTM 통과한 것을 concat 하는 방법)
- Subword-level Tokenization
텍스트를 단어보다는 작고, 문자보다는 크도록 나누는 것이다. 주로, 자주 발생하는 문자 조합이나 / 형태소를 기반으로 단위를 결정한다. 예컨대 'NLP is interesting' 이라는 문장이 들어오면 [NLP, is, in, ter, est, ing] 으로 쪼갠다.
이렇게 자르게 되면 자주 발생하는 조합으로 끊어내기 때문에 character 만큼 늘리지 않으면서 (예컨대 ing 의 재활용, character level 문제의 극복) OOV 문제도 해결(word level 문제의 극복) 할 수 있을 것 같다. 이렇게 Subword 로 전환하게 되면서 한국어에서도 비슷하게, 형태소 단위로 쪼갤 수 있게 되었다. (나, 는, NLP, 가, 재미, 있, 다)
Subword 의 단점으로는 Optimal subword unit 을 얻기위해 많은 계산이 필요할 수도 있다는 점이 있다. 그래도.. 장점이 더 많다. 성능을 보자.
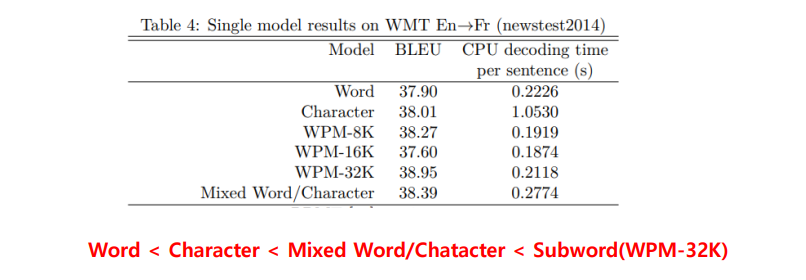
요즘의 언어모델들 또한 최종적으로 토큰화 + 벡터화만 진행하고, 방법으로 Subword 단위로 입력을 처리한다는 점을 알아두자.
2. Subword Tokenization Method
✅ 1. Byte Pair Encoding Model (BPE)
자주 나타나는 문자의 나열을 새로운 Subword 로 간주하는 방식이다. 대표적으로 GPT모델이 학습할 때, BPE 로 얻어진 단위로 학습을 한다.
- input: Words with frequency, Vocab size
- output Subword dict
-
Initialization for subword dictionary
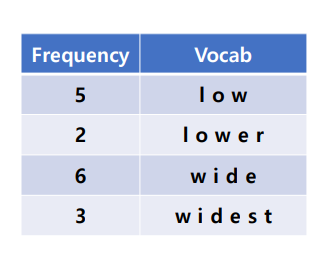
딕셔너리와 vocab 을 준비한다. -
Find, replace the most frequent pairs in vocab
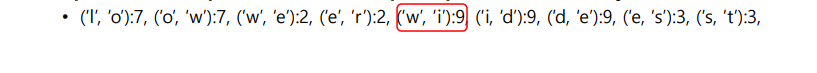
pair 마다 vocab 에서 몇번씩 나왔는지 count하는 과정이다. -
가장 많이 나타난 w, i 페어를 뽑고, subword dictionary 에 추가한다.

이렇게 딕셔너리에 추가한다는 것은 자주 나타난 단어이니 그냥 하나로 보겠다는 것이다.
후 다시 센다, 다음 후보는 d,e 페어이다. de 도 역시나 딕셔너리에 추가한다.

다음으로 많이 나온 글자는 wi, de 페어이다. 9번 나왔으므로 wide 로 딕셔너리에 추가한다.

여기서 종료하게 되면 위와 같은 Subword 딕셔너리를 최종적으로 얻게 된다.
만약 wider 라는 단어가 들어오면 긴 것부터 매칭하여 'wide' 를 찾을 것이고, 다음은 'r' 을 찾아 wide + r 구조의 단어를 만들 것이다.
BPE의 종료조건
BPE merging 을 언제까지 할 것이냐? 의 문제인데, 다음과 같은 방법이 있다.
- Fixed Number of Merges
• 고정된 병합 수까지 진행하고 종료한다 - Subword Dictionary Size Limit
• 딕셔너리 크기를 지정하고 크기가 넘으면 종료한다 - No More Merges Possible
• 더 이상 병합이 불가능할 때까지 진행한다. 이렇게 할 경우 모든 단어가 병합이 될 것인데.. subword + word embedding 이 되어버려 문제가 생긴다. - Minimum Frequency Threshold
• threshold 보다 작은 페어가 나오면 종료한다.
가장 많이 쓰이는 방법은, 연산을 위해서 Subword dictionary 크기를 고정시키는 2번째 방법이다.
✅ 2. WordPiece
두번째 방법으로, 빈도에만 의존하지 않고 나타나는 가능성을 최대화하는 방법이다.
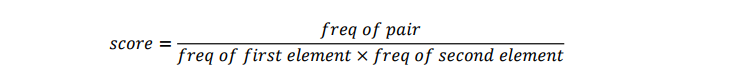
쌍의 카운트를 하긴 하지만, 각각의 개별 단어의 빈도까지 고려하는 방법이다. 각 단어가 다른 곳에서도 많이 등장한다면, 꼭 그 페어랑 등장하는 것이 아닌 원래 많이 나오는 단어이므로 score 를 감하겠다는 것이다. Score 가 높은 쌍이란 따라서, 다른 곳에서도 덜 나오면서도 꼭 둘이는 자주 나오는 페어를 뜻한다.
이러한 방법은 BERT 기반의 Transformer 모델들이 wordpiece 의 variation 으로 얻어진 서브워드 단위로 학습한다.
해당 페이지 에서 BERT 의 subword 를 확인할 수 있다. 총 28996 개의 subword 가 있었고, 대략적으로 아래와 같이 생겼다. 처음에는 initailization 해놓은 단어만 있다가, 갈수록 더욱 더 길어지고 정교화된 단어들이 만들어지는 것을 느껴볼 수 있다