XGBoost 와 LightGBM
- Tree 기반 Gradient Boosting 알고리즘이 모델 성능의 우수성은 인정되나 학습 시간이 너무 오래걸림
- XGBoost 가 발표된 이후 더욱 Gradient Boosting 방식이 인기
- XGBoost 경우 모델 성능이 좋고 병렬 학습으로 인한 학습 시간 단축을 기대할 수 있음
- XGBoost 도 대용량 데이토에 대해서는 학습 시간 오래 걸림
- LightGBM 은 모델의 성능은 물론이고 모델 학습 시간을 대폭 향상시키기 위해 개발 (XGBoost < LightGBM < Randomforest)
- 대용량 데이터에 최적화 모델을 만들기 위해 반복적인 Feature Egineering 과 하이퍼 파라미터 튜닝을 수행해야 하므로 많은 시간이 필요함. 때문에학습 시간을 단축해주는 LightGBM이 많이 사용.
LightGBM 개요
- leaf-wise 방식으로 Tree 를 생성하므로 보다 빠르게 Tree 생성을 할 수 있음
- leaf-wise 방식은 level-wise 방식보다 더 overfitting 하기 쉬움 (성능의 문제)
- 내부 하이퍼 파라미터, 구현 기술로 성능 문제를 극복하면 학습 시간은 4배 빠르게 유지시키고, 성능은 거의 대등하게 구현 가능함
- feature 개수가 수천개로 늘어나도 성능이 크게 저하되지 않음.
leaf-wise와 level-wise
트리의 성장방식에 따른 분류이다. 문서 를 참조하자.
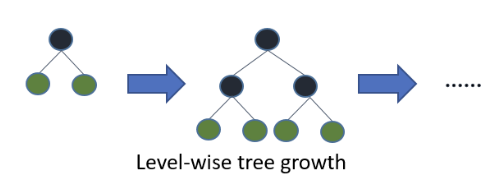
level_wise tree growth 의 경우 트리의 깊이를 줄이고 균형있게 만들기 위해서 root 노드와 가까운 노드를 우선적으로 순회하여 수평성장하는 방법. 이때에는 균형을 잡기위한 추가 연산이 필요. XGBoost 가 여기에 속함.
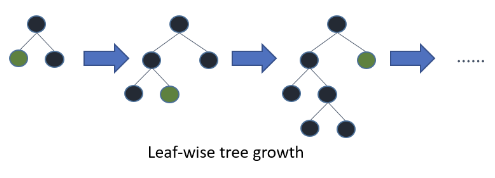
leaf-wise tree growth 의 경우 loss 변화가 가장 큰 노드에서 분할하여 성장하는 수직 성장방식. 비대칭 트리 생성이 특징이며 loss 변화 기준으로 분할하기 때문에 예측 오류 손실이 작거나 빠르게 도달할 수 있다. LightGBM 이 여기에 속함.
level-wise 와 달리 leaf-wise는 빠르게 도달할 수 있는 장점과 달리 성능면에서 overfitting 하기 쉬운 아키텍쳐이지만 이를 내부 하이퍼 파라미터와 구현 기술로 극복했다고 보는 것이 맞다.
GBM 개요
Gradient Descent + Boosting
경사하강법 + 부스팅
오류에 대해 가중치를 주는 방식이다.
LGBM 주요특징
- histogram 기반으로 feature Binning
- Boosting 시 GBDT 외에 GOSS, DART 방식 제공
- Overfitting 극복하기 위해 여러 hyper parameter
✅ histogram 기반 feature Binning
Best split gain 을 위해 모든 leaf node 의 데이터들을 대상으로 해야함. 오랜 수행 시간. : 연속형 피처들을 특정한 개수의 Bin 으로 할당하여 시간을 줄임
✅ Goss
- Gradient 값이 상대적으로 큰 값에 대해서만 선택적으로 필터링, 반복적으로 재학습
- Gradient 값이 작을경우 이미 상당한 수준의 학습이 진행되었다 가정
- 수행 시간은 단축, 모델 성능은 ..
✅ DART(Dropouts meet Multiple Adiitive Regression Trees)
- iteration 을 수행하면서 트리가 만들어질 때 마지막에 만들어 지는 트리들이 일부 데이터 세트 조건만을 만족시키기 위해 만들어지는 경우 있음. 이 Tree 를 아예 Drop out.
LightGBM boosting type
- boosting type 은 gbdt, goss, dart, rt 가 있음
- 어떤 타입이 최적인지는 직접 수행을 해봐야 알 수 있음.
LightGBM 하이퍼 파라미터
-
오버피팅에 취약 (depth 가 깊어지는 문제)
-
max_depth: 트리의 최대 깊이 -
num_leaves: 최대 리프노드 갯수
이 두 가지를 조정을 해서 뎁스가 너무 깊어져 오버피팅이 나지 않게 해주는 게 중요.
bagging_fraction/subsample: 데이터를 절반만 트리를 생성하는데 사용feature_fraction/colsample_bytree: 매우 많은 피처 중 일부만 사용min_data_in_leaf/min_child_samples: 리프 노드가 될 수 있는 최소 데이터 건수lambda_l2/reg_lambda: L2 규제 적용 값.lambda_l1/reg_alpha: L1 규제 적용 값.max_bin: Feature 들의 histogram 만들 때 최대 bin 들의 개수
하이퍼 파라미터 튜닝 수행 방법

Grid Search : 격자, 값에 대한 범위를 이산값으로 표현해서 (개별 하이퍼 파라미터들을) 순차적으로 결합. 수행시간이 너무 오래 걸린다.
Random Search : 랜덤하게 개별 하이퍼 파라미터 결합. 수행시간은 줄이지만 운에 맞긴느 것이다. 최적 파라미터를 찾기 어려움.
Bayesian Optimization
수동 튜닝 : 어느정도 사용하는 것이 바람직하다.
- 튜닝해야 할 하이퍼 파라미터 개수가 많고 범위가 넓어서 개별 경우의 수가 너무 많다.
- 데이터가 크면 너무 오랜 시간이 걸린다.
