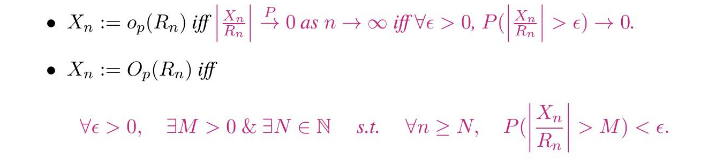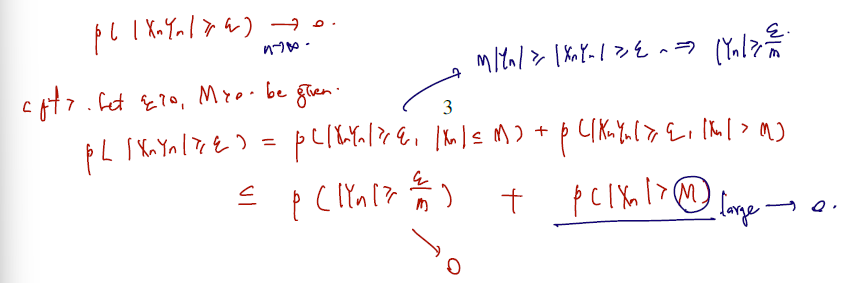확률유계의 개념을 알기 위해선 big-O 와 little-o notation 에 대해 알아야 한다. 아래 big-O, little-o 의 정의부터 보자.
Definition (Lindau's big-O and little-o notations). Let {xn} and {rn} be nonrandom sequences of real values.
xn:=o(rn) iff ∣∣∣∣rnxn∣∣∣∣→0 as n→∞.
little-o 의 경우 xn을 rn으로 나누게 되면 n이 무한대로 가면서 0으로 수렴한다는 것이다. 따라서 다음의 예시를 생각해볼 수 있다.
xn:=O(rn) iff limn→∞∣∣∣∣rnxn∣∣∣∣<∞ iff
∃M>0,∃N∈N such that ∀n≥N,∣∣∣∣∣rnxn∣∣∣∣∣≤M
위의 notation 보다 아래의 정의를 조금 더 많이 많이 쓴다. 0보다 큰 M이 있고, 자연수 집합에 속하는 N이 있다고 했을 때 이 N보다 큰 n에 대해서 (수열의 number가 점점 더 크게 갈수록) M 으로 bound 가 된다는 것. 따라서 다음과 같은 예시가 있다.
현재 관찰 중인 수열 xn들은 왼쪽이다.
n^2/3n^2은 0으로 수렴하므로 little-이면서 big-O로 쓸 수 있다.
n^3/n^2 은 n이 커지면서 무한대로 발산하므로 bound 되지 않는다.
n/n^2 은 bound 된다.
따라서 관찰하는 수열의 leading term이 big-O notation 내의 수열보다 차수가 작거나 같을 때 big-O로 쓸 수 있다. 작거나 같다는 건 big-O 내 수열 아래로 bound 가 된다는 뜻이다.
이러한 의미로 알고리즘 등에서 계산 복잡도 등을 나타날 때 big-O를 사용했던 것이다. 우선 n이 무한대로 간다는 조건이 필요하고.. 무조건 big-O(.) 보다 작거나 같음, 이 아래로 복잡도가 떨어진다는 것이다.
비슷하게 little-o notation에서 이를 함수로 확장하면 다음과 같다.
Similarly, f(x)=o(g(x)) as x→a is defined by f(x)/g(x)→0 as x→a.
아래의 예시를 보자.
x^2/x = x 이므로 x 가 0으로 가면서 0으로 수렴한다.
x/sinx 를 x 가 0으로 가면 1로 수렴하므로 little-o가 아니다.
little-o 를 이용하면 테일러 전개에서도 little-o를 포함한 notation 을 쓸 수 있다. 우선 테일러 전개는, 점 y를 근사하는데 x 근처의 y를 써서 이를 x에 대한 식으로 전개함으로 간단히 말할 수 있겠고.. 이때 절편은 g(x), 기울기는 g'(x) 다.
그런데 마지막 항은 이 항 자체를 |y-x| 로 나누고 y -> x 로 보내게 되면 0으로 수렴할 수 있으므로 by def. = o(|y-x|) 로 바꿀 수 있다. 따라서 y가 x로 갈 때 다음과 같이 테일러 전개를 little-o를 포함하는 식으로 바꿀 수 있다. 이는 이어지는 delta method 를 증명할 때 잠깐 사용되는 내용이니 챙겨두자.
Example: Taylor expansion. Suppose g(x) is differentiable at x. Then we can write
g(y)=g(x)+g′(x)(y−x)+o(∣y−x∣) as y→x
big-O와 litte-o에 대한 간단하 성질들을 보자. 이는 직관적으로 쉽게 이해할 수 있는 내용으로, 다른 증명은 하지 않고 자유롭게 쓰도록 하자.
Properties. (big-O & little-o)
xn=o(1)⟺xn→0. In addition, xn=o(1)⟹xn=O(1)
xn=O(1)⟺{xn} is bounded.
xn=o(rn)⟺xn/rn=o(1) and xn=O(rn)⟺xn/rn=O(1).
xn=o(1),yn=o(1)⟹xn+yn=o(1) and xnyn=o(1)
(simply say o(1)+o(1)=o(1) and o(1)o(1)=o(1) ).
xn=O(1),yn=o(1)⟹xn+yn=O(1) and xnyn=o(1).
xn=O(1),yn=O(1)⟹xn+yn=O(1) and xnyn=O(1).
확률유계를 알기 위해선 여기에서 그치지 않고 Big-O-p 와 little-o-p 를 알아야 한다. p가 들어간 이유는, 이전에는 각 xn, rn 수열을 나눈 것이 0으로 수렴한다면, 지금은 Xn, Rn 확률변수가 도입되고, 이 둘을 나눈 것이 0으로 확률수렴한다. (little-o-p 의 정의) 이에 대한 정의를 보자.
Definition (Big-O-p and little-o-p notations). Let {Xn} and {Rn} be sequences of random variables.
Xn:=op(Rn) iff ∣∣∣∣RnXn∣∣∣∣P0 as n→∞ iff ∀ϵ>0,P(∣∣∣∣RnXn∣∣∣∣>ϵ)→0.
확률수렴은 다른 말로 0보다 큰 임의의 앱실론이 존재하여 해당 변수가 앱실론을 벗어날 확률이 0을 보이는 것이었고, 따라서 iff 뒤의 두 notation 을 번갈아쓴다.
Big-O-p 는 임의의 앱실론 외에도 M이 도입되어 이 변숙 M 밖에 위치할 확률이 앱실론 밑으로 bound 될 경우를 뜻한다. 아래의 경우를 보자.
정규분포를 따르는 X의 pdf 라 하자. 그리고 cdf 를 적분하여 더해간다고 할 때,
에타1, 에타2를 다음과 같이 given 앱실론의 확률 바깥에 위치하도록 잡을 수 있다.
FX(x)<ϵ/2 for x≤η1 and FX(x)>1−(ϵ/2) for x≥η2
하나의 에타를 더 큰 에타로 max 로 정한다면, X가 에타 안에 들어갈 확률은 (에타 자체를 잡을 때 앱실론 안에 들어가도록 했으므로) 1-앱실론보다 작음을 보일 수 있다. -> 무조건 들어간다는 뜻이고, 여기서 포인트는 앱실론 밑으로 확률이 떨어진다보다 (이는 임의의 앱실론에서 가능하므로 0과 가까움을 이야기하고 싶다는 표현이고) 어쨌든 계산된 확률변수가 M 안의 범위로 bound 된다는 것이다. M 또한 임의의 수이므로 매우 크거나 작게 조절할 수 있다.
Let η=max{∣η1∣,∣η2∣}. Then
P[∣X∣≤η]=FX(η)−FX(−η−0)≥1−(ϵ/2)−(ϵ/2)=1−ϵ
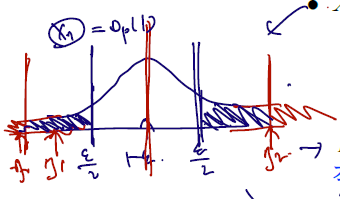
위 그림에서는 Xn 만 설정하여 Xn/1 이 M으로 bound 됨을 보였는데, 이렇게 big-O 안에 1이 들어 Xn 변수 자체만 볼 수 있다면, if Xn=Op(1)로 쓸 수 있고, 이때의 Xn is call bounded in probability (확률 적으로 유계임) or stochastically bounded.
따라서 Xn이 확률유계다~ 라고 한다면 0으로 수렴하는 것이 아닌 해당 변수가 M으로 bound 됨을 생각하면 되고,
임의의 양수 앱실론, M, N이 존재할 때 다음이라 생각하고 알아두자.
P(∣∣∣∣∣RnXn∣∣∣∣∣>M)<ϵ
Big-O-p 와 litte-o-p 도 직관적으로 아래의 성질들이 가능함을 보일 수 있다.
Properties. nonrandom big-O and little-o notations.
For a sequence of nonrandom numbers {xn},xn=o(1)⟺xn=op(1) and xn=O(1)⟺xn=Op(1).
Xn=op(1)⟺XnP0. In addition, Xn=op(1)⟹Xn=Op(1).
Xn=Op(1)⟺{Xn} is bounded in probability (it is by definition).
Xn=op(Rn)⟺Xn/Rn=op(1) and Xn=Op(Rn)⟺Xn/Rn=Op(1).
Xn=op(1),Yn=op(1)⟹Xn+Yn=op(1) and XnYn=op(1)
( simply say op(1)+op(1)=op(1) and op(1)op(1)=op(1)).
Xn=Op(1),Yn=op(1)⟹Xn+Yn=Op(1) and XnYn=op(1) (Theorem 5.2.7).
Xn=Op(1),Yn=Op(1)⟹Xn+Yn=Op(1) and XnYn=Op(1).
이어지는 내용으로 계속해서 성질들을 다루되 증명할 것 3가지와 그냥 알아둘 것 1가지가 있다.
(그냥 알아둘 성질1) XnDX⟹Xn=Op(1).
Xn이 X로 분포수렴한다면 Xn은 M에 의해 bound 가 되는 확률유계가 된다.
(증명할 성질1)
if f(x)=o(g(x)) as x→a and XnPa, then f(Xn)=op(g(Xn)).
(증명할 성질2) Xn=Op(1) and YnP0⟹XnYnP0 (i.e., Op(1)op(1)=op(1)). -> big-O-p 인 확률유계와 op(1) 인 두 변수를 곱하하면 op(1) 이 된다.
(증명할 성질3)
Suppose Xn=op(Yn) and Yn=Op(1). Then Xn=op(1). -> op 안으로 Big-O-p 인 확률 유계가 들어가면 op로이다.
Proof. Let a,ϵ>0 be given. Because the sequence {Yn} is bounded in probability, there exist positive constants N1 and B such that
n≥N1⟹P(∣Yn∣>B)≤2ϵ
Also, because Xn=op(Yn), there exist N2>0 such that
지금까지 다룬 정리와 증명을 포함하여 아래 델타method 를 증명한다. 델타 방법은, (0, 모분산)으로 수렴하는 확률변숙 있다면 여기에 non-linear 변환을 거친 것이 어떤 분포를 따르느냐 하는 것이다. 예컨대 표본평군의 제곱의 분포, square root 를 씌웠을 때 어떤 분포를 따를 지 궁금할 수 있다.
Theorem ( Δ-method). Let {Xn} be a sequence of random variables, 다음이 주어질 때
n(Xn−θ)DN(0,σ2)
Suppose the function g(x) is differentiable at θ and g′(θ)=0. Then 아래의 것을 보이고 싶다.
n(g(Xn)−g(θ))DN(0,σ2(g′(θ))2).
(Proof.) First, we claim that the assumption implies XnPθ, since the in-distribution convergence of n(Xn−θ) implies n(Xn−θ)=Op(1) and Xn−θ=Op(1/n).
여기까지의 내용은 in disribution convergence 가 있다면 Xn은 확률 유계라는 (그냥 알아둘 성질1)을 쓴 것이다.
Now, using Taylor expansion of g at θ, we have
g(t)=g(θ)+g′(θ)(t−θ)+o(∣t−a∣) as t→a
Combining this with XnPθ, we obtain
여기서는 (증명할 성질1), 함수에 있어서 확률변수와 little-o-p 를 끼워넣는 방법을 써서, 아래를 얻을 수 있다.
g(Xn)=g(θ)+g′(θ)(Xn−θ)+op(∣Xn−θ∣), as n→∞
이를 square root n을 곱하고 넘겨서 정리하면 다음이 나온다.
n(g(Xn)−g(θ))=g′(θ)n(Xn−θ)+op(n∣Xn−θ∣)
우리는미 n∣Xn−θ∣=Op(1)임을 밝혀두었었고, little-o-p 안에 Big-O-p 가들어가있는 구조로 이는 liitle-o-p(1)로 수렴한다. (이는 증명할 성질 3)을 쓴 것이다. 마지막 term 이 0으로 가고, by Slutsky's theorem, (n(Xn−θ)가 분포 수렴하는 상황에서 g′(θ) 상수가 곱해져있으므로)
결론: the limiting distribution of n(g(Xn)−g(θ)) is the same as the limiting distribution of g′(θ)n(Xn−θ), which concludes the proof.
주어진 식에서 n(Xn−θ)DN(0,σ2) 은 이미 가정이므로, 여기에 g′(θ) 를 곱하게 되면 g′(θ)n(Xn−θ)DN(0,σ2(g′(θ))2) (분산만 제곱으로 끼워넣어주므로) 이다. 따라서 증명을 마무리할 수 있다.
Example.n(Xˉ−μ)DN(0,σ2). 를 가정할 때 이를 제곱한 n(Xˉ2−μ2) 은 어떤 분포를 따를지 보이자. 여기서는 nonlinear 변환이므로 위의 델타 method 를 쓸 수 있다.