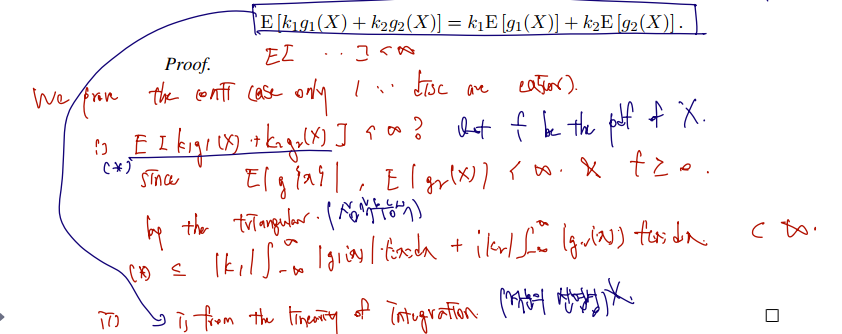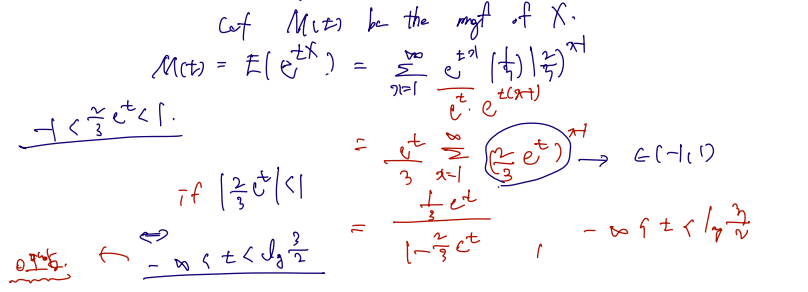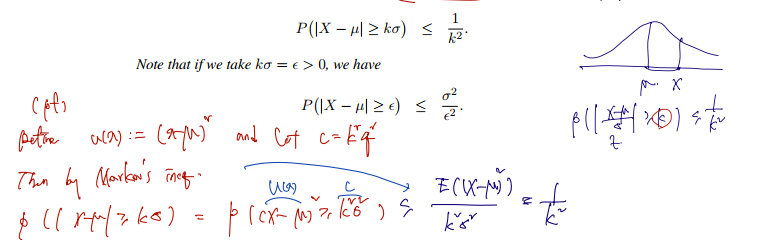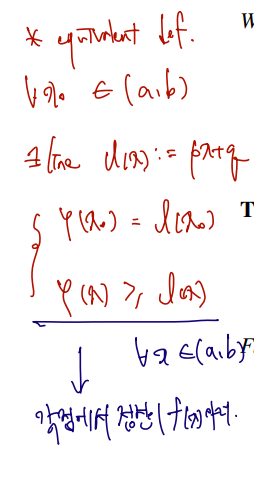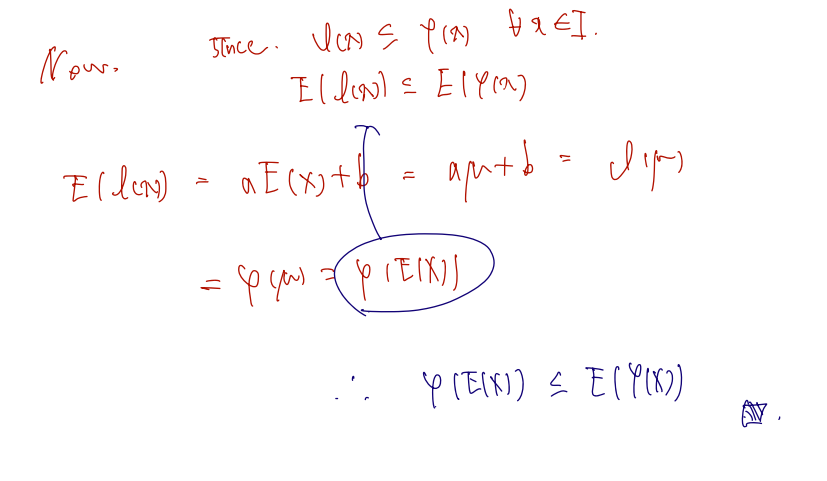일반적인 분산이 X에서 평균을 뺀 값에 제곱을 입히는 것과 달리 왜도는 세제곱을 취한다. 세제곱을 한다는 것은 부호가 산다는 것이며 50% 중앙값과 평균이 각각 어디에 위치하는지 그림에 따라 양, 음 값을 가진다.
첨도는 분포 내에 얼마나 이상치 outlier 가 많은지를 확인할 수 있는 값이다.
일반적인 N(0,1)의 왜도는 0, 첨도는 3이다.
이제 적률생성함수 mgf의 정의를 보자. 적률생성함수는 우리가 X의 확률에 대해 분포를 나타날 때 대표적으로 쓰는 cdf / pmf or pdf / mgf 로 매우 중요하게 쓰이는 분포에 대한 표현 중 하나라 이해하자.
Definition (mgf) Let X be a r.v. such that E(etX)<∞ for all ∣t∣<h for some h∈(0,∞]. Then, MX(t):=E(etX) is called the moment generating function (mgf, 적률생성함수) of X.
E(etX)<∞ 라는 것은 발산하지 않고 기댓값이 존재한다는 것이고,
중요하게 t가 -h와h 사이의 open interval 에서 정의된다. (0을 포함해야 한다.)
E 안에 들어간 변수를 g(x)로 두고 변환을 적용하면 다음과 같이 쓴다.
정의에 따라서 pmf 가 주어질 때 mgf를 구하는 과정과 특히나 과정서 범위를 유심히 살펴보자.
Exmaple1: negative binomial distribution, 음이항분포. Let X be a r.v. with the pmf
p(x)=31(32)x−1,x=1,2,…
Find the mgf of X.
Exmaple2: exponential distri'n, 지수분포. Let X be a r.v. with the pdf f(x)=e−x, x>0. Find the mgf of X.
Theorem: Uniqueness of mgf: Let X and Y be r.v.s with mgf MX and MY, respectively, existing in open intervals containing 0 . Then, FX(z)=FY(z) for all z∈R if and only if MX(t)=MY(t) for all t∈(−h,h) for some h>0.
cdf 가 모두 같다는 것은 mgf 가 모두 같다는 것과 같은 말이다. 이 증명은.. 따로 없이 넘어갔다.
mgf 사실관계
mgf 는 존재하지 않을 수 있다. (발산할 수 있다)
mgf 를 통해 pdf 를 찾을 수 있는 경우가 있으나 일반적이지 않음.
mgf를 사용하면 m차 적률을 쉽게 구할 수 있다. 즉, mgf 를 한 번 미분하면 E(X)이고 두 번 미분하면 E(X^2) 이다. (모든 m차 적률이 존재한다고 할 때, Taylor expansion 사용하면)
Example
사실관계 3에 대한 예시를 보자. binomial distri'n 이라 할 때, mgf는 M(t)=(pet+1−p)n. 이고, E(X)를 찾는다고 하자.
E(X)는 mgf를 한 번 미분하여 t = 0을 대입하면 구할 수 있다고 하였다. mgf를 미분하면 다음과 같고,
M′(t)=dtd(pet+1−p)n=petn(pet+1−p)n−1
따라서 t = 0 을 대입하면 pn 이므로 E(X) binomial distribution 의 흔히 알고 있는 expectation 과 맞아떨어진다. (이 부분이 가장 놀라웠던 부분)
그러나 모든 distribution 의 mgf를 외우고 있을 필요도 없고 그럴 수도 없다는 것.. 따라서 mgf의 미분을 통해 E(X^m) 을 구하는 것은 가능은 하지만 일반적이지 않아보이긴 한다.
1.10 Important inequalities
다음의 이어지는 3가지 부등식의 의미와 증명, 적용까지 모두 알아두자.
Markov's inequality (마코프 부등식)
Chebyshev's inequality (체비셰프 부등식)
Jensen's inequality (얀센 부등식)
1. Markov's inequality. Let u(x):R→R be a nonnegative function. If E{u(X)} exists, then for every positive constant c, we have
P(u(X)≥c)≤cE{u(X)}
(proof)
2. Chebyshev's inequality. Let X be a r.v. where E(X2)<∞. Let μ:=E(X) and σ2:=Var(X). Then for every k>0,
P(∣X−μ∣≥kσ)≤k21
Note that if we take kσ=ϵ>0, we have
P(∣X−μ∣≥ϵ)≤ϵ2σ2
(proof)
3. 얀센 부등식 전.. convex function
얀센 부등식은 convex function 에 대한 이해를 포함하고 있으니 이것 먼저 확인하자. Convex function 의 정의는 다음과 같고, '내분의 함숫값이 함숫값의 내분보다 항상 같거나 작다'로 알아두면 편하다.
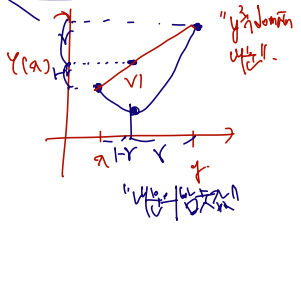
Definition. A function φ defined on an interval (a,b) is said to be a convex (볼록 또는 아래로 볼록) function if for all x,y∈(a,b) and 0<γ<1,
φ(γx+(1−γ)y)≤γφ(x)+(1−γ)φ(y)
We say φ is strictly convex (순볼록) if this inequality is strict.
이와 정확히 같은 의미로 쓰이는 것이 다음 φ에서 그을 수 있는 접선 l(x)=px+q 를 통한 정의이다.
++) 만약 φ is differentiable on open interval, then
Theorem 1.10.4. If φ is differentiable on some open interval I, then
1. φ is convex if and only if φ′(x)≤φ′(y) for all x,y∈I with x<y,
2. φ is strictly convex if and only if φ′(x)<φ′(y) for all x,y∈I with x<y.
++) 만약 φ′′ exists on I,
φ is convex if and only if φ′′(x)≥0 for all x∈I,
φ is strictly convex if and only if φ′′(x)>0 for all x∈I.
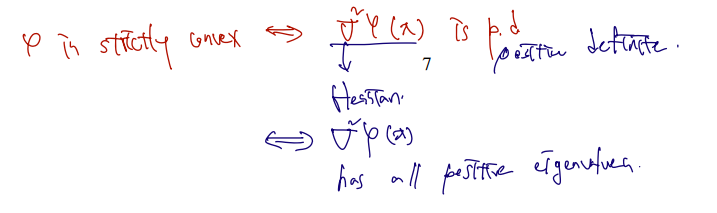
여기서 나아가 φ 가 stricly convex 하다는 것과 동치로 쓰일 수 있는 statement 로 1) 이 함수의 Hessian 이 positive definite 라는 것, 2) hessian 의 eigenvalues 가 모두 positive 라는 것 이 있다.
이제 얀센의 부등식을 보자. 얀센의 부등식 또한, convex를 정의할 때 느낌을 가져와 내분의 함숫값이 함숫값의 내분이라는 의미 그대로다.
3.Jensen's inequality. Let φ be convex on an open interval I. Let X be a r.v. whose support is contained in I and E∣X∣<∞. Then, we have
φ(EX)≤E{φ(X)}
If φ is strictly convex, then the inequality is strict unless X is a constant.
(proof)
부등식의 증명만 두고 보면 간단하나 linear function l 이 다음과 같이 존재하는 것까지 증명하면 더 깔끔해보인다.