Bahdanau Attention Function
바다나우 어텐션에서의 함수는 역시나 Q, K, V로 구성되지만 이번에 Query 는 디코더 셀의 t시점이 아닌 t-1 시점의 은닉 상태이다.
Query: t-1 시점의 디코더 은닉 상태
Keys: 모든 시점의 인코더 은닉 상태들
Values: (계산된) 모든 시점의 인코더 은닉 상태들
앞서 어텐션 함수의 전체적인 계산 구조를 이해했으니, 이번 글에선 바로 바다나우 어텐션의 연산 순서로 들어가자.
어텐션 함수의 전체적인 계산 구조는 아래에서 확인할 수 있다.
Attention 이해하기
1. Attention Score 구하기
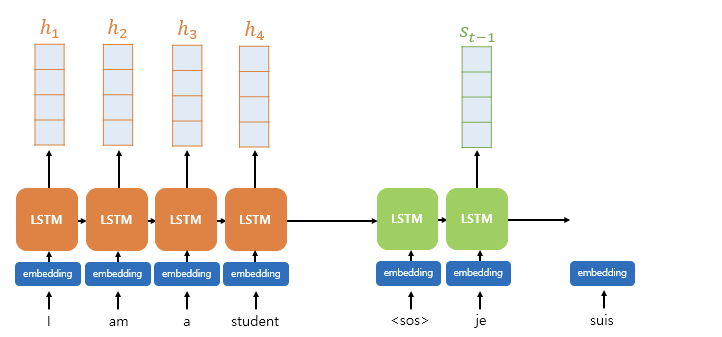
- h는 인코더의 은닉 상태를 말하고
- 는 t시점에서의 디코더 은닉 상태를 말한다. 여기서는 t-1 시점을 사용
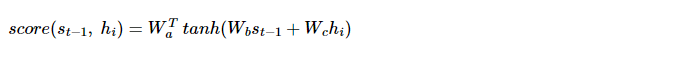
- Wa, Wb, Wc 는 학습 가능한 가중치 행렬
- 각각을 H로 변경
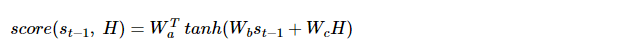
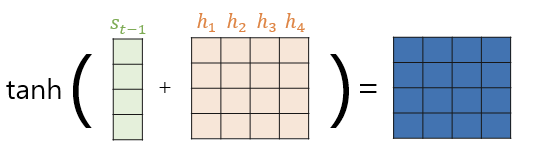
먼저 과 를 구하면 다음과 같다.
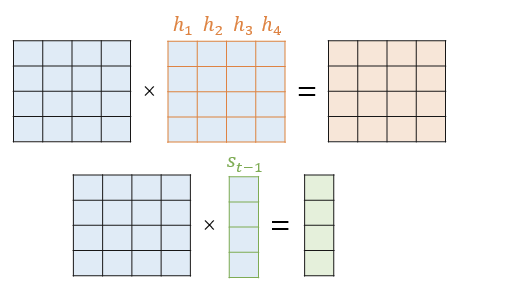
이들을 더한 후 tanh함수를 적용시킨다.
이제 와 곱하면 t-1 시점에서의 s와 h1, h2, h3, h4 의 유사도가 기록된 Attention score 를 얻는다.
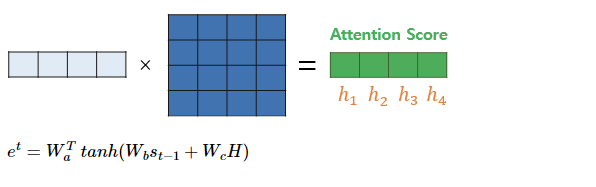
는 1 X 4 행렬임에 유의하자.
2. Attention distribution 계산 (Softmax)
소프트맥스를 한 번 거치면 h1 ~ h4 의 값에 해당하는 확률 분포를 얻고, 이를 Attetion Distribution 이라 한다. 각 값은 Attention Weight.

이렇게 계산된 각각의 값은 t-1시점의 디코더 은닉셀인 s와 인코더 각각의 은닉셀과의 연관도를 확률로 나타낸 것을 뜻한다.
3. 어텐션 가중치와 은닉 상태 Weighted Sum => Attention Value
2에서 계산된 Attention Weigh 와 h 은닉 상태를 또다시 곱한다. 다시 곱하는 이유는 원래 s와 상관없이 가진 h 문맥 정보에 확률 값을 곱하여 s에 따라 다른 Attention 집중을 주기 위함이다.

왼쪽 4X4 행렬이 은닉상태를 모아둔 것이며, 4X1 행렬이 각 인코더의 시점에서 어텐션 가중치이다. 이 둘을 가중합하면 인코더의 문맥이 포함된 Context Vector 가 완성된다.
4. Context Vector => 계산
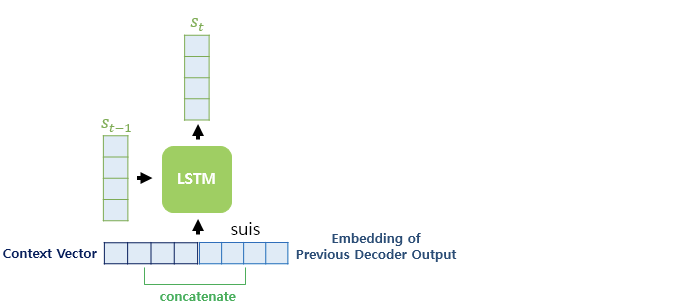
바다나우 어텐션은
- 3에서 구한 Context Vector 과 단어의 임베딩 벡터를 Concat (기존 LSTM 에서는 단어임베딩 벡터만 사용)
- 이전 시점으로부터 전달받은 St-1
- 위 2가지 값을 이용해 St 계산
5. 구한 로 예측값 계산
- 가중치 행렬을 곱하고
- bias 를 더한 후
- Softmax 적용하는 일반적 출력층 연산을 거친 후 예측값을 만든다.
차이점?
추가적으로 바다나우 Attention 이 기존 Attention 과 어떤 차이가 있는지 생각해보자.
- Query 의 시점이 디코딩 t시점이 아닌 t-1 시점이었다.
따라서 기존 Attention 연산은 LSTM 연산을 모두 끝내놓고 단어를 최종적으로 예측하기 위해 를 컨텍스트 벡터 와 Concat 한 값을 써서 를 계산했다. 그러나 바다나우에서는 LSTM 를 계산하기 위해 입력을 주는 값으로 컨텍스트 벡터를 사용했다.
따라서 직관적인 의미를 풀어써보자면..
기존 Attention 은 , 즉 디코딩 시점에서 단어에 대한 정보를 미리 구해두고 t시점의 단어를 기준으로 이전 단어들을 Attention 한 느낌이라면
바다나우 Attention 에서는 를 계산하는 것을 목적으로 t-1시점의 단어를 기준으로 이전 단어 중 어떤 것을 Attention 할 지 계산하고, 이를 활용하여 를 계산한 느낌이다.
